Статьи за 2008
использование lftp
2008/01‣sysadmin
Всем приходится пользоваться ftp-клиентами, иногда даже консольными. Стоит про них знать. Консольных клиентов несколько, самый простой – ftp - есть почти везде, правда, немного отличается по реализации в разных системах. Из более удобных продвинутых есть lftp и ncftp. Про второй пока промолчу, я им почти не пользовался, про lftp пойдет речь ниже. подключение Подключение к серверу возможно несколькими способами. Если вызываем lftp вот так: ... подробнее
руководители телекоммуникационных компаний размышляют о будущем отрасли
2008/01‣бизнес
Новый онлайновый опрос корпорации IBM, охвативший более 250 руководителей глобальных телекоммуникационных компаний, наглядно демонстрирует, как эта отрасль реагирует на происходящую сегодня революцию в коммуникационном и медийном секторах. В результате опроса, проводившегося силами организации Economist Intelligence Unit по поручению подразделения IBM Institute for Business Value, было установлено, что 69% поставщиков телекоммуникационных ... подробнее
IT-инфраструктура: слона-то я и не приметил
2008/01‣бизнес
В одном из исследований компании Forrester за 2007 год подчеркивается, что постоянно растет количество IT-бюджетов, потраченных в основном на предоставление и поддержание IT-сервисов. Многие компании в сфере IT тратят около 80% своего годового бюджета на поставку сервисов, в то время как еще десять лет назад на эту статью расходов уходило 60-65%. Это означает, что компании все меньше средств тратят на разработку новых проектов. В долгосрочной ... подробнее
Linux на борту: Разработка приложений для Nokia N800
2008/01‣программирование
Заглянем внутрь телефона/Интернет-планшета/Web-камеры Nokia N800 и подробнее рассмотрим среду разработки, построенную на базе scratchbox. Linux приобрел заслуженную популярность в мобильных и встроенных приложениях, благодаря его способности сокращаться до небольших размеров, необходимых для эффективной работы на компактных устройствах. Коммуникатор Nokia N800 пользуется этим и предлагает широкий спектр общей функциональности, которую может ... подробнее
угрозы "валюте нового мира"
2008/01‣save ass…
IronPort Systems, дочерняя компания Cisco, поставщик средств защиты предприятия от спама, вирусов и шпионских программ, опубликовала отчет о тенденциях развития систем сетевой безопасности в 2008 году (2008 Internet Security Trends Report). Отчет IronPort выделяет главные тенденции развития систем безопасности на сегодня и предлагает способы защиты от угроз нового поколения, которые могут появиться в Интернете в будущем. время любительских ... подробнее
цена простоя
2008/01‣save ass…
Корпорация Symantec опубликовала результаты исследования, посвященного изучению отношения предприятий малого и среднего бизнеса к технологиям обеспечения безопасности и бесперебойности работы ИТ-инфраструктуры, а также степени информированности этих предприятий о такого рода технологиях. Партнером при проведении исследования выступила компания Softline. Исследование проводилось посредством веб-анкетирования и опроса по телефону 100 ... подробнее
краткое руководство по общению с *никсофилами
2008/01‣PRIcall
Не нравится мне, что сейчас творится. Ох, не нравится! Наглые линуксятники совсем задавили Пользователей Операционной Системы Windows®. Последние, как люди интеллигентные, не всегда находят что противопоставить хамящим пингвинятникам. Но будет неправильно, если Зло одолеет в споре адептов Единственно Верной Операционной Системы. Так что, пораскинув мозгами, я решила внести свою лепту в торжество прогресса и доброй воли, составив памятку для ... подробнее
хостинг-провайдеры и их клиенты – попытка диалога
2008/01‣мнение
Быстро развивающиеся технологии и отсутствие жестких стандартов приводят к тому, что ожидания клиентов и возможности хостеров часто не совпадают. А для того чтобы найти компромисс, нужно понимать потребности другой стороны. Это особенно критично в хостинге, ведь хостинг – услуга технически сложная, требующая специальных знаний не только от хостера, но и от клиента. Здесь не обойтись без диалога. Чего хотят клиенты? Что нужно хостерам? Чтобы ... подробнее
изящество и неловкость Python
2008/01‣программирование
По сравнению с "золотым веком" популярности Python 1.5.2 - в течение многих лет стабильной и надежной версии языка - Python приобрел множество новых синтаксических возможностей и встроенных функций и типов. Для каждого изменения в отдельности имелось достаточно веское основание, однако в целом из-за них современный Python - уже не тот язык, который при достаточном опыте можно выучить за один вечер. Помимо этого, с некоторыми изменениями связаны ... подробнее
нам дался этот NGN!
2008/01‣решения
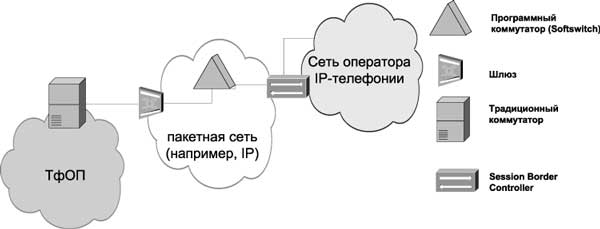
определимся с понятиями Название для технологии типа "штучка следующего поколения" вызывает много нареканий. Может сложиться ложное впечатление, что после этой "штучки" других не будет. Читатель, ты живешь на свете давно, и все эти "штучки" знаешь. Может, это маркетинговое словосочетание, как "проблема 2000", "электронный документооборот" или приснопамятные АСУ? "Птица счастья завтрашнего дня" какая-то! Кроме действительности существует ... подробнее
FreeBSD
2008/02‣software
В определенный момент времени у каждого системного администратора (ну, или у большинства) возникает вопрос: «Что бы это такого придумать, чтобы ничего не делать, а оно само работало?» Такой вопрос возник и у меня во время применения домкрата к напрочь рухнувшему серверу. Я был бы не я, если бы озадачился этим вопросом исключительно сам, не озадачив никого вокруг. И в один прекрасный день было решено проверить некоторое количество ОС и выбрать ... подробнее
крупнейшие потери данных в 2007 году
2008/02‣save ass…
2007 год наверняка останется в памяти как черный год для информационной безопасности. Но вовсе не из-за хакеров или превзошедших их по вредоносности инсайдеров, а из-за самих пользователей. Тотальная информатизация в сочетании с банальной человеческой безалаберностью породили воистину адскую смесь. За 2007 год во всем мире произошло множество масштабных утечек данных (и нужно помнить, что мы узнаем далеко не обо всех подобных инцидентах). По ... подробнее
EMC выпустила новую сетевую систему хранения
2008/02‣бизнес

Корпорация EMC выпустила новую сетевую систему хранения EMC CLARiiON AX4 – гибкую, масштабируемую сеть хранения данных (SAN). Новая система легко внедряется, расширяется и переконфигурируется в среде VMware Infrastructure и традиционных ИТ-средах без простоя приложений. Емкость системы CLARiiON AX4 масштабируется до 60 Тб и поддерживает соединение iSCSI или Fibre Channel SAN. Благодаря встроенным расширенным функциям управления и защиты ... подробнее
разработка веб-страниц с помощью google gears. Часть 1
2008/02‣программирование
В последний год становится все более яркой тенденция сращивать веб-приложения с традиционными настольными версиями программ. Конечно, это уже давно не новость. Если углубиться в историю, то первые решения такого рода появились еще во времена первого бума и последующего краха дот-комов. Но именно сейчас начинает меняться фокус приложения сил. Смотрите: раньше в качестве цели декларировалась доставка в настольную программу содержимого из ... подробнее
количество крупных ЦОД растет
2008/03‣бизнес
Корпорация Microsoft заявила о своих планах создать первый в Европе вычислительный центр для поддержки различных сетевых сервисов и приложений Microsoft. По большей части это относится к таким службам, как MSN, Windows Live и Hotmail. Для этого в ближайшем будущем Microsoft инвестирует более $500 млн. в постройку мощного дата-центра на территории Ирландии. Центр будет представлять собой группу зданий общей площадью 51,09 тыс. м2 в Дублине; на ... подробнее
межсайтовый скриптинг в примерах
2008/03‣save ass…
Что бы уметь хорошо защищаться, необходимо знать и способы атак. Эта истина известна давно, причем действует в оба конца. Каким образом можно предупредить DoS, если не знать даже, что это? Любой пользователь компьютера должен хотя бы в общих чертах знать способы атак, не говоря уже о специалисте, тем паче по информационной безопасности. Бьюсь об заклад, что все слышали словосочетание «SQL-инъекция», ну, или «РHР-инклудинг». Сегодня речь пойдет ... подробнее
проект EclipseLink
2008/03‣программирование
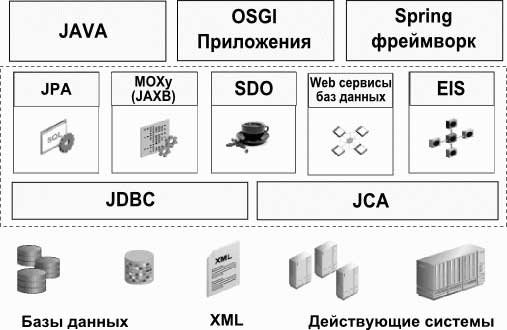
В 2007 г. на конференции EclipseCon представители корпорации Oracle анонсировали предложение о создании в сообществе Eclipse открытого (Open Source) проекта подсистемы хранения (Open Source Eclipse Persistence Project) по свободной лицензии Eclipse Public License (EPL), которая позволяет создавать коммерческие продукты. В дополнении к этому предложению корпорация Oracle преподнесла очередной подарок передав хорошо известный Java-фреймворк ... подробнее
разработка веб-страниц с помощью google gears. Часть 2
2008/03‣программирование
Сегодня я продолжаю рассказ о google gears. В первой статье серии я рассказал о новой идее организации веб-приложений, легшей в основу технологии google gears. Тогда же в качестве примера я решил показать, как создать небольшое приложение “записная книжка”. Затем мне пришлось сделать небольшое отступление от собственно gears и рассказать о sqlite — базе данных, где gears хранит пользовательскую информацию. Сегодня пришло время собрать эти ... подробнее
Дорогой Chief Security Officer!
2008/04‣PRIcall
Мы заработали на твоей сети уже столько денег, что решили написать благодарность. о тебе Мы видим тебя периодически на конференциях. Ты внимательно слушаешь и записываешь умные мысли, которые говорят вендоры, но мы тебе очень благодарны, что ты не применяешь то, что тебе говорят на практике. Правда, чаще всего мы тебя видим во время конференций в барах и ресторанах, особенно если конференция проходит где-нибудь на берегу моря. о защите в ... подробнее
cоциальные сети на краю заката?
2008/04‣бизнес
Рейтинговое агентство Nielsen Online озадачило неожиданной новостью: в январе 2008 года наблюдался беспрецедентный спад пользовательского интереса к социальной сети Facebook. Посещаемость сайта, в частности, британскими пользователями снизилась в это время на 5% по сравнению с декабрем 2007 года. Попросту говоря, в январе администрация Facebook недосчиталась 400.000 заходов на свой сайт. Случайность или новая тенденция? Еще год назад эта ... подробнее
IT-индустрия: дрожь в коленках
2008/04‣бизнес
Общая нервозность в мировой экономике наконец передалась и IT-индустрии. Чтобы убедиться в этом, достаточно посмотреть на индексы NASDAQ. Одни идут вверх, другие — вниз, но ведь все они взаимосвязаны... Вот только что-то на этот раз на редкость много новостей связано с Microsoft. Минувший месяц в центре внимания оставался конфликт, в который стремительно перерастает попытка Microsoft купить компанию Yahoo. Произошло сразу несколько заметных ... подробнее
о важности принятия правильных управленческих решений
2008/04‣бизнес
Взгляды на компанию, сверху и снизу, диаметрально противоположны: сверху видны только цифры, снизу видны только туманные цели компании. Истинные цели боссов практически никогда не совпадают с тем, чего ждут от сильных мира сего простые смертные. За красивыми цифрами капитализации практически всегда стоят сотни уволенных сотрудников. Оставшиеся, не понимая «за что?», стеклянными от ужаса глазами смотрят на раздающиеся из кабинетов, обставленных ... подробнее
Comcast подозревают в хакерских методах борьбы с пользователями
2008/04‣технологии
Comcast - второй по величине провайдер доступа к глобальной сети в США. Во многих районах страны это единственный, или один из двух, поставщик услуг кабельного телевидения и широкополосного интернета. Ориентировочно в мае 2007 года Comcast произвел модернизацию своего оборудования и программного обеспечения, после чего в прессе начали мелькать сообщения о появлении у некоторых клиентов определенных проблем со связью. Наиболее известными стали ... подробнее
Как украсть миллион?
2008/04‣save ass…
Защита данных становится бизнес-задачей №1 Инциденты в области утечки данных не так часто становятся достоянием широкой общественности. Однако пример, произошедший в прошлом месяце, поражает своим масштабом и беспечностью госорганизации, оперирующей персональными данными граждан. Речь идёт об утере двух компьютерных дисков, содержащих персональную информацию обо всех получателях детских пособий в Великобритании — а это 25 млн человек и 7,25 ... подробнее
Windows против Linux – психологический портрет участников форумов
2008/04‣PRIcall
О сколько сломано мечей и шлемов, в наших битвах?! О сколько в навь ушло и отроков, и сильников, и старцев?! Но истины, в чьих поисках идет сраженье, как не было, так нет… В разгаре боя, истины не ищут, она лишь повод…дабы состязаться… Ее увидеть можно, лишь со стороны… Те, кто интересуется компьютерными и околокомпьютерными новостями, те, кто по роду своей деятельности часто общается с персональными (и не только) компьютерами, даже те, кто ... подробнее
ARP-spoofing: старая песня на новый лад
2008/04‣технологии
Об arp-спуфинге известно уже давно. С момента публикации первых материалов по этой проблеме прошло много лет. Было написано много программ как реализующих данный тип атак, так и призванных защитить от этих самых атак. А с недавних пор такую защиту стали внедрять и в персональные межсетевые экраны. Казалось бы: тема исчерпала себя. Однако полигон для работы мозгов все же остается... суть вопроса В этой статье мы рассмотрим атаку типа ... подробнее
Mikrotik – еще одна ОС для маршрутизаторов на основе Linux
2008/04‣software
вступление Любая вещь должна быть функциональной и надежной. Это касается как шариковой ручки, так и больших и сложных систем, в которых участвует не один десяток различных компонентов и где от работы одного зависит работа остальных. В большинстве случаев в таких сложных системах наблюдаются сбои, несмотря на то, что они построены на хорошо отлаженных структурных единицах. Примеры, противоположные этому, встречаются достаточно редко, но сам ... подробнее
нормативное правовое и методическое регулирование работы и обеспечения сохранности электронных документов и информационных ресурсов
2008/05‣закон и порядок
введение Применение современных информационных технологий позволило человечеству начать перевод накопленной им информации в электронную форму и создание новых видов информационных ресурсов (ИР) и электронных документов (ЭД), без использования которых немыслимо становление современного информационного общества. После перевода в электронную форму и интеграции в единую систему, ИР приобретают качественно иной статус, обеспечивающий более ... подробнее
в России запускают ICQ-TV
2008/05‣бизнес
Российская медиакомпания Gameland подписала соглашение с американской корпорацией AOL о совместном запуске в России ICQ-TV. Об этом журналистам рассказал директор по развитию Gameland Павел Романовский. Специально для реализации проекта ICQ-TV партнеры создали совместное предприятие. Уже сейчас для пользователей запущенной в ноябре 2007 года шестой версии ICQ в тестовом режиме доступна услуга просмотра музыкальных клипов, трейлеров к ... подробнее
беспроводные амбиции Google
2008/05‣бизнес
Еще несколько лет назад компания Google декларировала исключительно намерение «упорядочить всю информацию в мире». Теперь, похоже, амбиции интернет-гиганта простираются намного дальше — и преимущественно в телекоммуникационную индустрию. 19 марта в США завершился исторический для телекоммуникационной отрасли страны аукцион — публичная распродажа аналоговых телечастот. Эти частоты (700-мегагерцевый диапазон) высвобождаются после того, как в ... подробнее
WiMAX: уже в России, скоро и во всем СНГ
2008/05‣технологии
Беспроводные коммуникации становятся все более привлекательным бизнесом. Уже в нынешнем году в России, вполне вероятно, заработают первые сети широкополосного мобильного доступа в интернет по технологии WiMAX. Но вначале следует разобраться: чем они будут принципиально отличаться от уже существующих сетей фиксированного WiMAX-доступа и от сетей сотовой связи третьего поколения (3G)? Российский опыт обязательно следует изучить хотя бы потому, ... подробнее
cетевые шредеры
2008/05‣технологии
Исследователи из Вашингтонского университета запустили систему "Хаббл", названную в честь самой известной орбитальной обсерватории. Тезка телескопа обозревает не космос, а интернет, ища там черные дыры. Но не зоны сверхвысокой гравитации, а случаи бесследного исчезновения информации при путешествии ее по Сети. из Москвы в Нагасаки Одно из основных требований, предъявляемых к интернету – глобальная достижимость: возможность достичь любого ... подробнее
welcome to hell: кошмары автралийского интернета
2008/05‣PRIcall
Внимание, в данном тексте используется слово дерьмо. Я считаю себя культурным человеком, но в данном случае это не ругательство. Потому что в данном случае это слово использовано здесь не в переносном, а в прямом смысле. Просто это медицинский термин, наиболее точно описывающий ситуацию. Интернет в Австралии такой дерьмовый, что даже на мировом конкурсе дерьмовости интернета он получил только третье место. Сразу после интернета в Северной Корее ... подробнее
Cisco наращивает усилия на рынке центров обработки данных
2008/05‣бизнес
Современные хранилища цифровой информации, которые часто называют центрами обработки данных (ЦОД), становятся все более сложными, в результате чего резко возрастают расходы на управление и энергоснабжение (см. сравнительную диаграмму роста расходов на управление и техническую поддержку, приобретение новых серверов, а также на электроснабжение и охлаждение, составленную аналитической компанией IDC). Руководители информационно- технологических ... подробнее
в России планируют ввести наказание за спам
2008/05‣закон и порядок
Общественная палата РФ выступила с инициативой ввести административную ответственность за рассылку спама. По данным члена Общественной палаты адвоката Павла Астахова, 90,7% почтового трафика российского Интернета в марте составил спам. Кроме того, по его словам, в Интернете стало появляться огромное количество писем, содержащих порнографию или материалы экстремистского характера. Кроме того, существенно участились случаи хакерских атак на сайты ... подробнее
Cisco выводит на рынок маршрутизаторы Cisco 880 и 860
2008/05‣hardware
Компания Cisco анонсировала новые решения, оптимизирующие работу корпоративных отделений любого размера. Cisco открыла свои платформы ISR (Integrated Services Router - интегрированный сервисный маршрутизатор) и Cisco WAAS (Wide Area Application Services - прикладные услуги для глобальных сетей) для заказчиков и внешних разработчиков. При этом у Cisco появились партнеры с новыми идеями по разработке дифференцирующих решений и услуг, отвечающих ... подробнее
Motorola представляет точку доступа стандарта 802.11n
2008/05‣hardware

Департамент комплексных мобильных решений корпорации Motorola объявил о выпуске устройства AP-7131 – точки доступа с тремя радиомодулями (Tri- Radio Access Point) стандарта 802.11n, в которой реализована адаптивная архитектура от компании Motorola. Конструкция точки доступа позволяет одновременно обеспечивать высокоскоростной клиентский доступ, осуществлять беспроводной транспорт (backhaul) трафика сети Mesh и использовать выделенный ... подробнее
некоторые вопросы использования газоразрядных приборов для защиты линий Ethernet
2008/05‣технологии
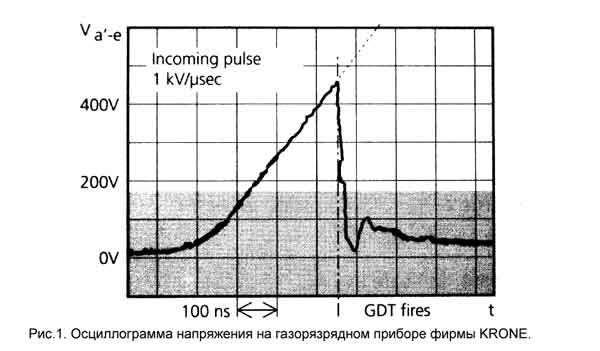
Газоразрядные приборы широко используются для защиты электронных устройств от импульсов повышенного напряжения различной природы. Этому способствует сочетание свойств: - крайне низкая проводимость в нерабочем состоянии; - высокая импульсная мощность; - низкая вносимая емкость; - низкое дифференциальное сопротивление рабочего участка вольт-амперной характеристики. Вместе с тем общеизвестны и недостатки этих приборов: - запаздывание ... подробнее
системы обнаружения компьютерных угроз
2008/05‣save ass…
Системы обнаружения сетевых вторжений и выявления признаков атак на информационные системы уже давно применяются как один из необходимых рубежей обороны информационных систем. Разработчиками систем защиты информации и консультантами в этой области активно применяются такие понятия (перенесенные из направления обеспечения физической и промышленной безопасности), как защита по периметру, стационарная и динамическая защита, стали появляться ... подробнее
системы управления версиями для программистов, и не только
2008/05‣программирование
Я полагаю, что многие из тех, кто занят в сфере информационных технологий, слышали про системы управления версиями. Вот только список тех, кто активно использует эту технологию в своей практике, гораздо короче. Часто говорят, что системы управления версиями (далее СУВ) нужны только программистам, и только тем из них, кто работает в команде. То есть когда кодом владеет не один “избранный”, а любой программист в команде может взять и внести в ... подробнее
международные стандарты, регулирующие управление документацией в организациях
2008/06‣закон и порядок
введение В современном высококонкурентном обществе разработка и внедрение технических нормативных правовых актов (ТНПА) в любой сфере деятельности является наиболее эффективным механизмом обеспечения согласованности действий и повсеместного распространения наилучших технологий и методов работы. ТНПА необходимы организациям различных форм собственности при оценке качества произведенной продукции (работ, услуг) и ее соответствия международным ... подробнее
эффективное управление системными журналами
2008/06‣sysadmin
Файлы системного журнала являются наиболее важными и часто исследуемыми инструментами мониторинга системы. В UNIX каждая программа, которая создает журнальные файлы, либо пишет информацию непосредственно в свой журнальный файл, либо собирает информацию посредством службы syslogd. Хотя регулярный просмотр и анализ этих файлов должен быть базовой методикой, используемой системными администраторами, реальность часто отличается от желаемого. Из-за ... подробнее
повышение безопасности с помощью многоэкземплярности директорий
2008/06‣sysadmin
Если вы заинтересованы в защите от несанкционированного доступа к совместно используемым директориям (например, /tmp или /var/tmp), которые доступны на запись "всему миру", вам могут помочь подключаемые модули аутентификации Linux (PAM). При входе пользователей в систему модуль pam_namespace создает отдельное пространство имен. Это разделение выполняется на уровне операционной системы Linux, в результате пользователи оказываются защищены от ... подробнее
опыт внедрения свободного ПО в американской государственной школе
2008/06‣мнение
В прошлом учебном году я работал администратором в сельской школе в Иллинойсе. Пытаясь сэкономить школьные деньги, я внедрил OpenOffice.org, GIMP, Firefox, Thunderbird. На нескольких рабочих машинах и на паре серверов был установлен Linux. В качестве дистрибутива был выбран Ubuntu. На серверах для пробы устанавливались также OpenSUSE, Debian, Fedora и Slackware. Открытое ПО и операционные системы некоторыми были встречены с одобрением, ... подробнее
сделайте ваши страницы 404 интеллектуальными при помощи сопоставления метафонов
2008/06‣программирование
Создайте собственный обработчик сообщения об ошибке 404 для предоставления посетителям полезных ссылок и перенаправления на содержимое вашего сайта. Используйте алгоритм сопоставления метафонов (metaphone matching) и файл простых весовых оценок для перенаправления пользователей при опечатках и орфографических ошибках, а также некорректных ссылках. Настройте варианты выбора на основе содержимого вашего веб-сайта и предпочтительных для ... подробнее
тактическая эксплуатация уязвимостей
2008/06‣save ass…
При тестировании на проникновение все внимание часто сосредотачивается на уязвимостях и сервисах. В данной статье представлен тактический подход, который не связан с эксплуатацией известных уязвимостей. Используя сочетание новых инструментов и малоизвестных методов, мы проследим от начала до конца процесс компрометации организации без использования обычного набора экплойтов. Будут рассмотрены многие инструментальные средства, например, новые ... подробнее
NET-CLASS — сеть свободных знаний
2008/07‣software
Идея проекта NET-CLASS состоит в организации общественной свободной обучающей системы на основе обмена выгодой от совместного создания, накопления и использования обучающих ресурсов. NET-CLASS - форма организации данных и программ в интернет пространстве. Это не учебное заведение, а электронное учебное пособие для использования в процессе обучения. Учебный материал создают авторы и учащиеся, обучением управляют преподаватели, развитие проекта ... подробнее
Linux Vacation / Eastern Europe: взгляд изнутри
2008/07‣бизнес
Влад Шахов, крайний за организацию LVEE 2007 Интервью взято в день закрытия конференции Linux Vacation / Eastern Europe 2007. — Начнем со скептического вопроса: нужны ли в принципе такие встречи? Неужели не хватает виртуального общения? Виртуального общения не хватает. Атомизацию индивидов нужно преодолевать. Свободное ПО — это совместная работа. А совместная работа — это общение, обмен идеями. Если мы не умеем общаться и обмениваться ... подробнее
OpenInkpot: освобождая электронные книги
2008/07‣бизнес
В докладе представлен OpenInkpot — проект разработки свободного дистрибутива, ориентированного на устройства для чтения книг на базе электронных чернил. В докладе рассказывается о предпосылках к созданию проекта, о достигнутых результатах и об устройстве дистрибутива. e-ink В 2007 году на массовом рынке появились специализированные устройства для чтения с экранами на основе электронной бумаги (e-ink). Электронная бумага — тип экрана, ... подробнее
Голос спонсора: Alatys
2008/07‣бизнес
На вопросы отвечает Дмитрий Бородаенко, соучредитель и заместитель директора по развитию бизнеса - Почему вы решили поддержать Linux Vacation Eastern Europe? Тесное сотрудничество с сообществом разработчиков свободного ПО — один из главных приоритетов компании Alatys. Как человек, активно участвовавший в LVEE с самого момента основания этого мероприятия, я знаю, что LVEE — самое значимое событие года для отечественных разработчиков. Это ... подробнее
Принципиально новая система организации коллективного знания
2008/07‣бизнес
Рассматривается веб-ресурс thiblo.com, представляющий собой на данный момент сайт для ведения журналов (аналогичный ЖЖ или blogger'у) с принципиально новой системой комментирования (webmore). В планах авторов — создание в перспективе интегрированного информационного ресурса для новостей, технических, научных и политических дискуссий, а также энциклопедической информации. история Разработка на стадии экспериментального прототипа началась в ... подробнее
Мультисервисные сети - настоящее и будущее
2008/07‣бизнес
В докладе дается понятие о мультисервисных сетях, раскрывается картина сетей ISP в Беларуси на сегодняшний день, оцениваются перспективы технологии. Основной задачей любого оператора связи является увеличение дохода с клиента (ARPU, average revenue per user). Для этого оператору приходится внедрять новые дополнительные услуги — IPTV, Video on Demand, IP-телефонию и ряд других, менее известных, но при этом не менее значимых услуг. Для того, ... подробнее
Debian: локальный репозитарий пакетов на основе архива исходников
2008/07‣бизнес
Рассказывается краткая история создания проекта Debian, принципы и цели проекта, динамика роста дистрибутива и сообщества. Приводится количественная оценка объёма и стоимости проекта. Описывается устройство дистрибутива и архива Debian, основные команды управления пакетами, а также пример создания локального зеркала исходников Debian и репозитория на его основе. история Этот проект был начат Яном Мёрдоком (Ian Murdock) 16 августа 1993г. В ... подробнее
Использование открытого программного обеспечения в учебных заведениях города Львова
2008/07‣бизнес
В докладе рассмотрено состояние использования открытого программного обеспечения в учебном процессе образовательных учреждений г. Львова. В двухтысячном году члену Львовской группы пользователей ОС Linux Злобину Г.Г. удалось убедить депутатов Львовского горсовета отказаться от приобретения классов учебной компьютерной техники с ОС Microsoft Windows. За счет экономии средств городской отдел образования смог приобрести дополнительно 10 классов ... подробнее
Использование в Linux САПР, ориентированных на машиностроение
2008/07‣бизнес
Рассматриваются варианты использования в ОС Linux систем автоматизированного проектирования, работающих с трехмерной графикой. какие бывают САПР Выбирая тот или иной программный продукт, следует четко представлять круг решаемых им задач: - если производство не является, мягко говоря, наукоемким, то вполне достаточным будет использование лишь 2D САПР (большинство мелких частных предприятий машиностроительного профиля, деревообработки, ... подробнее
Linux Terminal Server Project
2008/07‣бизнес
Преимущества использования терминальных технологий для целей миграции на свободное ПО и повторного использования морально устаревшего «железа». Участие в проектах ALT Linux и LTSP: порознь и вместе. ALTSP как уникальный сплав «лучшего из двух миров» – LTSP4/5. предыстория Когда компьютеры были большими, а их количество - маленьким, на одной системе в нескольких десятках килобайт работало несколько пользователей. Времена менялись, 640К ... подробнее
X Window System - взгляд в будущее
2008/07‣бизнес
Компьютерная графика становится частью нашей жизни. Сейчас любая универсальная ОС, не важно где она используется - в качестве домашней мультимедийной станции, в киноиндустрии, проектировании, в научной визуализации или при создании игр - не может обойтись без хорошей графической компоненты. В UNIX (исключая MacOS X с технологией Quartz Extreme, которая без всякого X Server напрямую выводит графику с помощью OpenGL) используется система X ... подробнее
Организация процесса разработки программных продуктов с использованием свободного ПО
2008/07‣бизнес
В докладе автор делится собственным опытом разработки программных продуктов и организации рабочего процесса при помощи свободного ПО. Кратко рассмотрены основные принципы разработки, организации командной работы и распределения задач, а так же контроля над версиями и цельностью исходного кода. Доклад может быть интересен как планирующим разрабатывать ПО, так и уже занимающимся разработкой. основы организации разработки ПО На этапе ... подробнее
Sun Studio Performance Analyser
2008/07‣бизнес
Выполнен обзор возможностей Sun Studio Performance Analyser. Рассмотрены анализ и оптимизация "родных"(С/C++/Fortran) и кроссплатформенных (Java) приложений на Solaris/OpenSolaris/Linux OC. Нередко перед разработчиком встает вопрос - "почему моя программа работает недостаточно быстро?" В этот момент необходим эффективный способ избавиться от тормозящих факторов. Даже в несложной программе таких составляющих достаточно: неэффективный ... подробнее
udev - реализация devfs в пользовательском пространстве
2008/07‣бизнес
введение ОС Linux используется на множестве различных платформ начиная от мобильных устройств и заканчивая суперкомпьютерами. Количество различного оборудования постоянно растет. Каждое устройство использует определённые ресурсы машины. Linux нужен был механизм, который бы эти ресурсы распределял. Существует технология Plug-and-Play для распределения ресурсов устройствам. Для "горячего" подключения (без перезагрузки) используется термин ... подробнее
Pkgsrc - многоплатформная система управления программными пакетами
2008/07‣бизнес
что такое pkgsrc? Pkgsrc (Package Source) это система управления пакетами, изначально разработанная для NetBSD. С тех пор она была перенесена на многие операционные системы, включая Linux, Solaris, AIX, OSF/1, DragonflyBSD и даже MS Windows для ее подсистемы Interix. Pkgsrc представляет собой хорошо организованную структуру каталогов и Makefile-ов, использующихся для установки программ вместе с зависимостями из исходных текстов программ или ... подробнее
Использование математической программы Scilab в учебном процессе в БРУ и МГУ им. А.А. Кулешова
2008/07‣бизнес
Излагается опыт использования математической программы Scilab в учебном процессе на кафедре "Физические методы контроля" Белорусско-Российского университета в дипломном проектировании и подготовке магистерской диссертации, а также на кафедре "Экспериментальная и теоретическая физика" МГУ им. А.А. Кулешова при разработке лабораторных работ и работе над кандидатской диссертацией. Дается оценка такого использования совместно с другим открытым ... подробнее
Платформа разработчика OpenMoko
2008/07‣бизнес
В работе выполнен обзор проекта OpenMoko, рассмотрены особенности интерфейса, связанные со спецификой устройств ввода-вывода. Рассмотрены способы разработки и отладки программ для платформы OpenMoko, в том числе на настольном компьютере. Мобильные устройства характеризуются большим разнообразием устройств ввода (ограниченный набор кнопок, сенсорный экран, внешняя клавиатура и т.д.), ограниченным пространством на экране - на PC наоборот ... подробнее
Использование Open Source проектов для обеспечения качества ПО
2008/07‣бизнес
В докладе рассмотрена возможность использования проектов open source для обеспечения качества ПО. Выделены основные особенности систем отслеживания дефектов (bug/issue tracking systems) и систем управления процессом разработки. Одна из главных задач, которая стоит перед индустрией программных средств — это обеспечение качества выпускаемых ПС. В настоящий момент имеется достаточно много специальных инструментов обеспечения качества, которые в ... подробнее
Глобальное применение Open Source и Freeware систем в корпоративной среде
2008/07‣бизнес
Рассматривается опыт использования открытого и бесплатного ПО на всех уровнях (от серверов и глобальной сети до рабочих мест) для построения и эксплуатации корпоративных информационных систем. введение Открытое ПО в силу своей специфики позволяет максимально оптимизировать систему под имеющуюся аппаратуру и желаемые характеристики, т.е. получить наилучшее соотношение цена/качество, что дает возможность, в свою очередь, либо снизить ... подробнее
Оценка Open Source проекта по CMMI
2008/07‣бизнес
В последнее время Открытое ПО становится всё популярнее. Правительства многих стран, крупные корпорации стали рассматривать Linux, OpenOffice.org и другое свободное ПО как достойную альтернативу коммерческим программам. Однако сам процесс создания свободного ПО изучен достаточно плохо. Пожалуй, единственная широко известная работа по данной тематике - «Собор и Базар» Эрика Рэймонда [1]. К сожалению, данная работа была написана 10 лет назад и ... подробнее
Разработка локализованного многофункционального дистрибутива Linux для научных и образовательных учреждений с ориентацией на максимальную простоту внедрения
2008/07‣бизнес
Рассматривается метод создания специализированного сборника свободного программного обеспечения, способного работать как с LiveCD, так и с локального диска, а также загружать бездисковые узлы через сеть . Работая с дистрибутивом Gentoo несколько последних лет, я столкнулся с, можно сказать, "некоторым неудобством" его установки в новом месте и демонстрации возможностей в среде, где обычного знакомого программного окружения нет. Мне хотелось ... подробнее
Автоматизация задач на серверах. Опыт поддержки однотипных *NIX серверов
2008/07‣бизнес
Системные инженеры регулярно сталкиваются с проблемой нехватки времени. Количество серверов возрастает, а времени на их поддержку остается все меньше. Возникает вполне разумное желание автоматизировать часть работы по их обслуживанию, централизовать управление группами серверов. Реализовать это можно, используя написанные собственноручно решения и выделяя время на их поддержку, либо можно использовать готовые решения, имеющие нужную ... подробнее
наши спонсоры: SaM Solutions
2008/07‣бизнес
Компания SaM Solutions традиционно выступает в качестве спонсора научно-практической конференции по разработке и внедрению свободного программного обеспечения Linux Vacation/Eastern Europe (LVEE). Не стал исключением и 2008 год. Стремление SaM Solutions отвечать требованиям времени и соответствовать высокому мировому уровню разработок в сфере IT обусловливает то, что одним из направлений деятельности компании SaM Solutions является направление ... подробнее
Свободное ПО как образ жизни
2008/07‣бизнес

Даниэль Надь, Будапешт, консультант по информационной безопасности — Расскажите о себе и своем опыте работы со свободным ПО. — Я живу и работаю в Будапеште, в Венгрии. Со свободным ПО я познакомился примерно в 1995 году. Тогда отчасти из бюджетных, отчасти из других соображений у нас в университете начали развертывать рабочие станции под Linux, и мне очень понравилось, что то, что есть в университете, я просто могу взять домой и ... подробнее
как оседлать волну унифицированных коммуникаций и избежать при этом акул
2008/08‣технологии
Групповая работа (collaboration) у всех на слуху, и все чаще - на рабочем столе. Если вы настроены на серьезную работу, эта технология помогает вам и другим сотрудникам буквально каждый день развивать бизнес, повышать производительность и успешно завершать проекты. Если вы живете и работаете в быстроразвивающихся странах, эта технология помогает воспользоваться всеми преимуществами, которые предоставляет бизнесмену растущая экономика. Для ... подробнее
правовые проблемы программ формирования электронных правительств в Республике Беларусь и Российской Федерации
2008/08‣закон и порядок
Стремление обществ видеть деятельность госорганов на различных уровнях более прозрачной и эффективной отражает популярность программ формирования и развития электронных правительств в ряде стран на этапе их перехода к информационному обществу. Глобальными целями формирования и развития программ э-правительства в мире являются значительное улучшение ситуации с: - доверием гражданина к государству; - качеством принимаемых госорганами решений; - ... подробнее
кодогенерация как высшая форма сopy/paste
2008/08‣success story
Несколько лет назад в одной беседе о технических горизонтах мой собеседник затронул тему кодогенерации. При этом демонстрировалась книга, привезенная из дальнего зарубежья. Второе упоминание попалось двумя годами позднее, в уже ставшей классической книге Эрика Реймонда "Дао программирования в Unix". Оба этих случая осели на задворках сознания, но я продолжал считать что кодогенерация - удел богов, трансцендентные техники просветленных гуру. ... подробнее
Cisco WAAS: доставка централизованных приложений мобильным пользователям
2008/08‣решения
По данным аналитической компании IDC, к 2009 году четверть мировой рабочей силы станет мобильной. Рынок мобильных приложений развивается бурными темпами, удовлетворяя растущий спрос. Предприятия виртуализируют корпоративные приложения, концентрируя их в центрах обработки данных (ЦОД) для доставки мобильным пользователям по сети. В локальных сетях (LAN) большинство приложений работает достаточно хорошо и быстро, но этого не скажешь про ... подробнее
"Черус" реконструирует системы электроснабжения для "Альфа-Банка"
2008/08‣success story
Компания "Черус" завершила реконструкцию систем электроснабжения в центральном вычислительном центре "Альфа-Банка". На протяжении 1,5 лет компания "Черус" выполняла работы по реконструкции систем электроснабжения в ряде офисов "Альфа-Банка", расположенных в Москве и Московской области. Наиболее масштабным объектом, для которого была спроектирована новая система электроснабжения и проведена реконструкция, является центральный вычислительный ... подробнее
камеры JVC помогли переводчикам встреч «большой восьмерки»
2008/08‣success story
На состоявшейся в Японии встрече руководителей государств "восьмерки" в центре внимания участников оказались поворотные камеры ТК-С686Е "день- ночь" компании JVC Professional. По отзывам организаторов встречи ТК-С686Е справилась с задачами на высшую оценку. Эти камеры были установлены в центре каждого зала и осуществляли трансляцию изображений выступающих на мониторы переводчиков-синхронистов. Высокое качество видео с камеры обеспечивала ее ... подробнее
умные здания могут сократить потребление энергии
2008/08‣технологии
Умные здания (smart buildings) не только экономят средства владельцев и жильцов, но и вносят существенный вклад в охрану окружающей среды. Идея "умных зданий" обсуждается не первый год, однако ее практическая реализация долгое время тормозилась отсутствием стандартной коммуникационной инфраструктуры, говорит Марк Голан (Mark Golan), руководитель отдела "подключенной недвижимости" компании Cisco. Зато сегодня IP-сети вполне способны стать ... подробнее
AtomPark Software объявляет о выходе новой версии StaffCop 2.5
2008/08‣бизнес
Компания AtomPark Software объявляет о выходе новой версии программы StaffCop 2.5. Программа StaffCop позволяет наблюдать за компьютерами и собирать статистику об активности. После установки StaffCop станет возможным получать детализированные отчеты об использовании компьютера и любых подключаемых к нему устройств, а также подробную статистику по веб-сайтам, которые посещают в рабочее время сотрудники. В новой версии реализована возможность ... подробнее
