краткое пособие по сквозной диагностике информационной системы
введение
Развитие информационных технологий привело к полному объединению ранее разрозненных элементов систем получения, обработки и передачи информации. Сейчас мы можем в полной мере говорить о существовании информационных систем (ИС), которые включают в себя программное обеспечение (ПО), серверы, персональные компьютеры, сети, телефоны, системы видеоконференций и безопасности и т.д. Таким образом, ИС – это совокупность всех элементов, предназначенных для обеспечения работы приложения.
Бурное развитие и усложнение информационных технологий привело к тому, что обслуживающий персонал все больше разделяется по специализациям (программисты, специалисты по сетям и электронной технике и т.д.); усложняется контроль и диагностика элементов ИС. В то же время сквозная диагностика ИС требует комплексного подхода и понимания работы всех элементов ИС.
К сожалению, данным вопросом практически никто не занимается, имеющиеся книги или описывают проблему в общих чертах, или рассказывают о задачах и методах решения применительно к конкретному оборудованию. В данном материале рассмотрены средства и методики проведения сквозной диагностики, то есть полной диагностики всех элементов и уровней ИС.
Диагностика ИС рассматривается в основном на примере Ethernet-сетей и Intel-совместимых компьютеров.
Примеры приводятся в виде задач, то есть вначале описываются симптомы проблемы, проведенные действия, полученные результаты и только в конце выводы.
элементы информационной системы
ИС состоит из взаимосвязанных элементов, которые можно с точки зрения диагностики представить в виде четырех уровней.
Элементы (уровни) ИС начиная с нижнего:
1. пассивное оборудование;
2. активное оборудование;
3. драйверы и сервисы ОС;
4. приложение (ПО).
Очень важно понимать, что все уровни взаимосвязаны и появление проблем в каком-либо из элементов всегда проявляется на более высоких уровнях. Однако, обнаружив проблемы на уровне приложения (например, замедление работы ПО), невозможно понять, на каком уровне они возникли. Из этого следует основное правило – диагностику необходимо проводить пошагово, на всех уровнях, начиная с нижнего.
На каждом уровне применяются свои средства диагностики. Заранее стоит предостеречь – ни одно из средств не делает выводов и не говорит о причинах проблемы. Это всегда приходится делать эксперту.
уровень пассивного оборудования
Пассивным оборудованием являются:
1. магистральные кабели;
2. кабели горизонтальной подсистемы;
3. информационные розетки;
4. рабочие соединительные кабели;
5. соединительные панели;
6. коммутационные шнуры.
Диагностика пассивного оборудования проводится кабельными тестерами. Они подразделяются на 3 группы:
1. простейший тестер;
2. кабельный тестер;
3. совмещенный кабельный тестер и сетевой анализатор.
Первые определяют правильность разводки витой пары, обрывы, короткое замыкание, а также показывают расстояние до обрыва или короткого замыкания. Стоят они в десятки раз меньше, чем кабельные тестеры.
Кабельные тестеры проводят полную диагностику состояния кабельной системы и сертифицируют ее на соответствие определенной категории. Также они могут иметь минимальные функции по мониторингу сети (загрузка сегмента, ошибки и т.д.) и возможность фиксирования внешних импульсных помех. Приборы третьей группы не могут соперничать ни с тестерами, ни с сетевыми анализаторами. В первую очередь они предназначены для выявления несложных и часто встречающихся проблем.
диагностика пассивного оборудования
Методика диагностики довольно простая – достаточно нажать только одну кнопку на кабельном тестере, чтобы получить полный отчет о состоянии пассивного оборудования и соответствии его определенной категории.
На рисунке 1 представлен пример отчета тестера OMNIScanner 2.
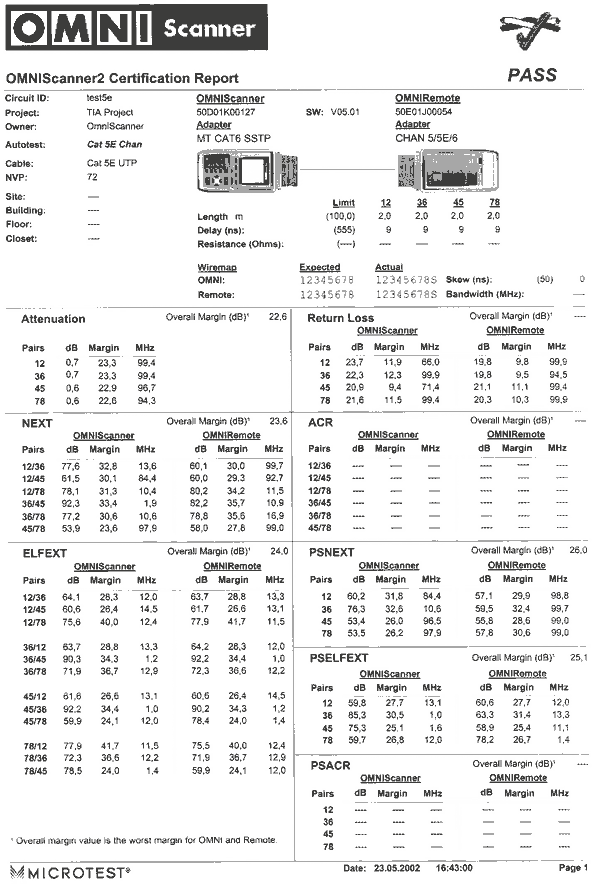
Рис. 1. Образец отчета кабельного тестера OMNIScanner 2.
В недавно построенных сетях проблемы с пассивным оборудованием практически не возникают, так как системные интеграторы стараются придерживаться стандартов и тестируют кабельную систему при сдаче. В старых сетях наиболее часто проблемы возникают при подключении компьютеров UTP-кабелем горизонтальной проводки к активному оборудованию и неправильной прокладкой и подключением коаксиальных кабелей.
Проблемы, возникающие на уровне пассивного оборудования, можно разделить на две основные группы:
1. нарушение стандартов при проектировании и установке пассивного оборудования;
2. внешнее воздействие на пассивное оборудование.
Диагностирование проблем первой группы представляет собой наиболее простую задачу, так как стандартизованы не только пассивное оборудование, но и правила его установки.
Проблемы второй группы диагностировать очень тяжело. Если в сети возникают ошибки, то с помощью доступных средств диагностики практически невозможно понять, что их вызывает. Если помеха от электроприбора накладывается на передаваемый пакет – мы просто увидим пакет с неверной суммой CRC. То же самое мы увидим и во время коллизии. Конечно, если мы увидим некий “мусор” без положенной для пакета преамбулы, можно предполагать, что это внешняя помеха. Однако существует вероятность того, что наложение пакетов произошло во время передачи преамбулы. С достаточной долей уверенности можно говорить о причинах ошибок после нагрузочного тестирования. Ошибки уровня пассивного оборудования слабо влияют на скорость работы компьютеров, и их количество не увеличивается с повышением нагрузки тестирования. Если ошибки вызваны более высокими уровнями – скорость работы компьютеров в сети падает катастрофически.
Импульсные помехи на кабеле без подключенного активного оборудования может обнаруживать OMNIScanner 2. Он регистрирует импульсы, превышающие 30 mv. Согласно тестам, проведенным компанией ITT NS&S, наводки от 38 до 123 mv в зависимости от пары начинают появляться при внешнем шуме 3 v/m. Также специалисты ITT NS&S утверждают, что при этих помехах концентратор показывал загрузку в сети более 80% (при отсутствии передачи данных). Однако по следующим причинам к данному тесту стоит относиться весьма скептически:
- компания откровенно продвигает свои экранированные кабельные системы;
- непонятно, что за кабель неэкранированной витой пары они использовали;
- концентратор не может служить измерительным устройством;
- не проверялось воздействие на передаваемые данные.
Да, в кабеле появились наводки, но остался невыясненным вопрос – как же все-таки они повлияют на реально передаваемые данные, тем более на современном оборудовании (тест проводился в 1995 году). К сожалению, никакой другой информации по внешним помехам найти не удалось, что свидетельствует о непроработанности данной проблемы. Практически невозможно ответить на вопрос: как внешние шумы повлияют на передаваемые данные. Даже если и будет зафиксировано изменение передаваемого сигнала при определенном уровне помех (для чего нужен записывающий осциллограф) – нельзя сказать, что точно такие же помехи вызовут сбой на другой кабельной системе с другим активным оборудованием. Мои эксперименты с OMNIScanner 2 показали, что в то время, когда OMNIScanner 2 регистрировал импульсные шумы, аппаратный анализатор WinPharaoh не зафиксировал никаких ошибок при передачи данных.
Несмотря на то, что диагностирование внешних помех является достаточно сложной задачей, нахождение проблемы достаточно простое. Обычно сами администраторы предупреждают о холодильниках и электрощитах. О них следует вспомнить, когда вы провели полную диагностику и не нашли причин ошибок в сети. Недопущение подобных проблем еще более простое – следуйте стандартам на установку пассивного оборудования.
Теперь приведем несколько примеров – будут описаны реальные случаи проблем с пассивным оборудованием.
Пример 1.Диагностика сети на 100 пользователей, ориентированной на бухгалтерские задачи.
Проблемы в сети: периодическое пропадание связи с сервером Oracle.
этап 1
Цель: предварительное обследование.
Структура ЛВС. В результате предварительного обследования было выяснено, что в сети находится несколько серверов под управлением OS Novell, а в качестве системы управления базами данных используется Oracle. Компьютерная сеть построена с использованием только концентраторов. Существует центральный коммутационный шкаф, в котором находится концентратор 3Com SuperStack II Dual Speed Hub 500 и подключенные к нему концентраторы SynOptics. Удаленные комнаты имеют свои концентраторы, подключенные к 3Com. Таким образом, сеть существует в виде одного сегмента. К нему подключено около 100 пользователей. Кабель горизонтальной проводки обжат в вилки RJ-45 и напрямую подключен к активному оборудованию. Методика и средства. Диагностика сети проводилось во время обычной работы пользователей в сети с помощью аппаратно-программного анализатора WinPharaoh компании GNNettest. Анализатор подключался к каждому концентратору в центральном коммутационном шкафу.
Результаты. Статистическая система анализатора зафиксировала достаточно большое количество ошибок типа Bad CRC и Runt.
этап 2
Методика тестирования и средства. Тестирование сети проводилось на следующий день во время обычной работы пользователей в сети с помощью аппаратно-программного анализатора WinPharaoh компании GNNettest. Никаких изменений после первого тестирования замечено не было. Выборочно была проверена кабельная проводка с помощью PentaScanner. Исследовались линии подключения серверов, отдельных сегментов и пользователей к центральному коммутационному шкафу.
Результаты: на линии 700 был обнаружен разрыв 6-го провода витой пары, на линии 10 – 6 и 4-го.
Вывод: c большой долей вероятности можно предположить, что плохие контакты в витой паре и являются источником снижения помехоустойчивости витой пары, а соответственно и обнаруженных в ЛВС ошибок. Повреждения кабельной системы обусловлены тем, что кабельная проводка ЛВС выполнена с грубыми нарушениями стандартов.
Рекомендации: до следующих этапов диагностики необходимо полностью заменить кабельную проводку.
На самом деле довольно сложно понять, что именно вызывает ошибки в сети, однако в данном случае во время дополнительных работ по диагностике было выявлено следующее: работа компьютеров в сети не замедляется и не влияет на количество ошибок, что свидетельствует о возникновении ошибок на уровне пассивного оборудования. В любом случае, в кабельной системе были найдены проблемы, и их необходимо было устранять.
Пример 2.Диагностика городской оптической сети, объединяющей несколько крупных локальных сетей.
Цель: выявление причин крайне медленной работы компьютеров в сети.
Структура ЛВС. В результате предварительного обследования было выяснено, что сеть объединяет несколько зданий и построена с помощью повторителей, расстояние между максимально удаленными точками – 5 км.
Методика и средства. Диагностика сети проводилось во время обычной работы пользователей в сети с помощью аппаратно-программного анализатора WinPharaoh компании GNNettest. Анализатор подключался к сегменту сети.
Результаты. Статистическая система анализатора зафиксировала большое количество ошибок типа Bad CRC, ALIGNMENT и JABBER.
Вывод: превышен диаметр коллизионного домена, что вызывает повреждение и ошибки в сети.
Рекомендации: сегментировать сеть. Проводить диагностику данной сети особого смысла не было, так как после первых же вопросов о топологии выяснилось, что превышен диаметр коллизионного домена, поэтому и ожидать чего-то иного от этой сети не приходилось.
уровень активного оборудования
Под активным оборудованием условимся понимать устройства, занимающиеся передачей и приемом информации в сети. Это коммутаторы, концентраторы, маршрутизаторы, сетевые адаптеры сетевые сервисные устройства и т.д. Нас интересует только их работа на физическом и канальном уровне модели OSI, то есть работа их сетевых интерфейсов.
Проблемы активного оборудования можно разделить на две основные группы:
1. поломка оборудования;
2. неверная настройка.
Методика диагностики не зависит от того, к какой группе принадлежит проблема, но понимание этого деления необходимо для правильного решения проблемы.
Проблемы на уровне оборудования проявляются только в виде ошибочных сетевых пакетов. Для их выявления необходим сетевой анализатор. Сетевые анализаторы подразделяются на программные и программно-аппаратные. Первые представляют собой программы, запускаемые на обычных компьютерах (ноутбуках). Программно-аппаратные состоят из специализированных аппаратных решений, предназначенных для диагностики сетей с различными интерфейсами, и программных средств, исполняемых на отдельном или интегрированном компьютере. И то и другое решение имеет свои плюсы и минусы.
Программные анализаторы:
- дешевле, чем аппаратные;
- имеют больший набор функций;
- проще обновляются.
Аппаратные анализаторы:
- могут иметь одновременно различные интерфейсы;
- имеют интерфейсы, с которыми не могут работать компьютеры;
- не зависят от производительности компьютера (подключаемый компьютер предназначен для отображения результатов диагностики, выполненного аппаратным интерфейсом);
- доподлинно отображают все происходящее на канальном уровне.
Методику и примеры диагностики канального уровня сетей Ethernet будем рассматривать на базе аппаратно-программного анализатора WinPharaoh компании GNNettest).
Диагностику транспортного и более высоких уровней – на базе анализатора Observer компании Network Instruments. Изображение Observer приведено на рис. 2.
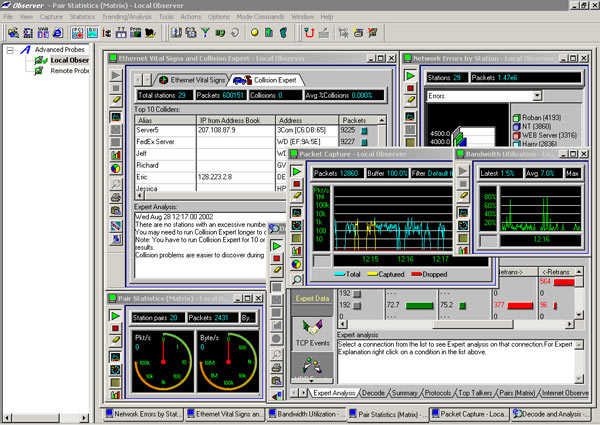
Рис. 2. Observer.
Не будем подробно останавливаться на функциях и возможностях сетевых анализаторов, определимся только с наиболее необходимыми из них для полноценной диагностики. Анализатор должен уметь:
- захватывать трафик;
- отображать трафик во время захвата;
- декодировать пакеты;
- отображать сетевые ошибки;
- проводить долговременный сбор статистики с последующим сравнением по выбранным диапазонам;
- анализировать потоки как минимум на 2 и 3 уровне модели OSI;
- фиксировать повтор передачи пакетов;
- проводить стрессовое тестирование;
- создавать отчеты;
- сигнализировать о проблемах в сети;
- снимать и протоколировать статистику с сетевых устройств по протоколам SNMP и RMON;
- показывать скорость потока и задержки от каждой из передающих сторон в реальном режиме времени;
- работать с удаленными агентами.
Если с аппаратными анализаторами все ясно, – они предназначены для того, чтобы диагностировать сети – то на некоторых вопросах в использовании программных анализаторов следует остановиться подробнее.
Для того, чтобы диагностировать сеть, ее необходимо прослушивать, то есть сетевая карта компьютера, на котором установлен анализатор, должна включаться в режим promiscuous mode (режим передачи уровню драйвера всех захваченных пакетов, а не только отправленных на данный сетевой адаптер). Но если с этим проблем практически не возникает, и карты захватывают из сети все пакеты, то с поврежденными пакетами все гораздо хуже. Сетевые карты их игнорируют, что, в принципе, абсолютно правильно. В качестве решения производители программных анализаторов предлагают вместе со своими продуктами специализированные карты. В компании Network Instruments пошли другим путем, они написали свои драйверы для распространенных сетевых карт.
Существует еще одна проблема. Дело в том, что программный анализатор обрабатывает поступающие из сети данные программно, то есть производительность анализатора зависит от мощности компьютера. Кстати, во время тестирования программных анализаторов с помощью аппаратного выяснилось, что их производительность очень сильно зависит от них самих. Например, Network Monitor показывал загрузку 10Мбит/с сегмента - 60% при 100% нагрузке от аппаратного анализатора, в то время как на этом же компьютере (Windows NT, PII-266, ОЗУ 64М) Observer показал загрузку 100Мбит/с сегмента - 80% при 100% нагрузке. Мощности современных компьютеров достаточно для полной дешифровки и экспертного анализа сетевого трафика канала 100Мбит/с и даже 1000Мбит/с.
диагностика в коммутируемой сети
Диагностика в коммутируемой сети имеет свои особенности, та как подключившись к порту сетевого оборудования, мы можем прослушивать данные, передаваемые только с этого или на этот порт. Для прослушивания данных, передаваемых через другие порты на сетевом оборудовании необходимо включать режим зеркального отображения если, конечно, такая функция в оборудовании есть.
Возможности режима зеркалирования могут отличаться для разного оборудования. Порт, включенный на прослушивание данных с другого порта, может перейти в блокированный режим, и выполнять только функции прослушивания. Некоторое оборудование может позволять перенаправлять данные сразу из нескольких прослушиваемых портов, что, правда, не совсем корректно, и может вызвать потерю части данных. Ошибки, зафиксированные прослушиваемым портом, могут перенаправляться или уничтожаться.
Однако обычно достаточно просмотреть статистику работы портов. Практически любое управляемое активное сетевое оборудование позволяет это сделать при помощи протоколов SNMP (Simple Network Management Protocol - простой протокол сетевого управления) и RMON (Remote MONitoring – удаленный мониторинг). Рассмотрим их возможности, применяемые в диагностике.
По протоколу SNMP можно получить сведения о настройках оборудования, информацию о работе портов. А также можно узнать общее количество широковещательных пакетов, байтов, ошибок, пакетов и отброшенных не ошибочных пакетов за время работы агента SNMP.
SNMP не показывает загрузку канала в процентном отношении. Некоторые средства мониторинга самостоятельно ее рассчитывают на основе данных о принятых и переданных байтах.
В отличие от протокола SNMP, предназначенного в основном для управления, его расширение – протокол RMON – фактически является сетевым анализатором и позволяет собирать большое количество информации о передаваемых данных и работоспособности портов. RMON состоит из 19 групп. Наиболее необходимая при диагностике сети – первая группа (статистика). Из группы статистики мы можем получить следующую информацию о работе порта (общее количество за время работы агента RMON):
- проигнорированных событий – etherStatsDropEvents;
- принятых из сети байт – etherStatsOctets;
- полученных пакетов – etherStatsPkts;
- широковещательных пакетов – etherStatsBroadcastPkts;
- многоадресных пакетов – etherStatsMulticastPkts;
- ошибок CRC – etherStatsCRCAlignErrors;
- пакетов нестандартной длины – etherStatsUndersizePkts и etherStatsOversizePkts;
- пакетов менее 64 байт и ошибкой CRC – etherStatsFragments;
- пакетов более 1518 байт и ошибкой CRC – etherStatsJabbers;
- коллизий – etherStatsCollisions;
- пакетов размером 64 байта – etherStatsPkts64Octets;
- пакетов размером от 65 до 127 байт – etherStatsPkts65to127Octets;
- пакетов размером от 128 до 255 байт – etherStatsPkts128to255Octets;
- пакетов размером от 256 до 511 байт – etherStatsPkts256to511Octets;
- пакетов размером от 512 до 1023 байт – etherStatsPkts512to1023Octets;
- пакетов размером от 1024 до 1518 байт – etherStatsPkts1024to1518Octets.
К сожалению, из-за ограниченных функциональных возможностей сетевое оборудование обычно поддерживает не более четырех групп. А группы после десятой относятся к информации транспортного уровня и оборудованием, работающим только на канальном уровне, поддерживаться не могут.
Также начинает внедряться и новый протокол – SMON (Switch Monitoring), собирающий информацию о работоспособности и передачи данных на уровне интеллектуального ядра устройства.
классификация сбоев работы сетей Ethernet
Четкое деление и классификация сбоев передачи в сетях Ethernet имеет очень важное значение для проведения диагностики, что будет показано на опытах и примерах ниже.
Сбои в сетях Ethernet можно разделить на две группы. Это сбой, в результате которого произошло либо повреждение пакета, либо возникновение нестандартного пакета.
Дальнейшую детализацию лучше всего отобразить в табличном виде (таблица 2).
Таблица 2. Классификация сбоев передачи в сетях Ethernet.
Примечание: в случае, если размер пакета не кратен 8, дополнительно фиксируется ошибка выравнивания – Alignment Error. Такая ошибка может встречаться при всех типах повреждения пакетов.
Классификация приведена согласно стандарту RFC 1757 “Remote Network Monitoring Management Information Base”. В качестве примера на рис. 3. приведен фрагмент таблицы etherStatsTable статистики RMON коммутатора 3Com SuperStack II 3300.
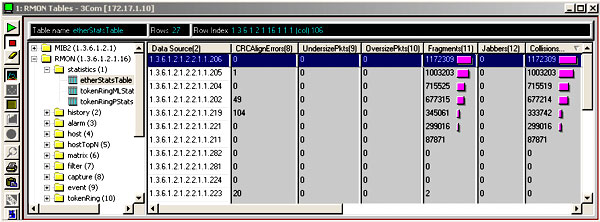
Рис. 3. Фрагмент таблицы etherStatsTable статистики RMON коммутатора 3Com SuperStack II 3300.
Повреждение пакета всегда проявляется в виде ошибки контрольной суммы, а вот понять, в результате чего пакет был поврежден – задача сложная и нетривиальная.
Повреждение пакетов может произойти в следующих случаях:
1. в результате наложения пакетов во время нормальной работы сети;
2. если сетевой интерфейс оборудования перестал прослушивать сеть перед передачей;
3. если работающие друг с другом сетевые интерфейсы установлены в разные режимы (FullDuplex< - >HalfDuplex);
4. если превышен диаметр коллизионного сегмента;
5. при повреждении пассивного оборудования;
6. от внешних помех.
Во всех этих случаях сетевой анализатор зафиксирует в сети пакет с неверной контрольной суммой.
различия ошибок повреждения пакетов
Коллизия – столкновение пакетов при одновременной передаче пакетов в сеть двумя или более станциями в одном сегменте, произошедшее во время нормальной работы сети.
Коллизия не является результатом сбоя работы сети. Возникновение ситуации наложения пакетов в сети подразумевается протоколом Carrier Sense, Multiple Access with Collision Detection (CSMA/CD). Самое главное отличие коллизии от ошибки в том, что коллизия обрабатывается и исправляется средствами сетевого интерфейса. В то время как при любом повреждении пакета в результате сбоя работы сети (сбои на физическом уровне; передача данных не соответствует протоколу CSMA/CD или стандартам физического уровня), можно говорить, что в сети произошла ошибка, которая с большой долей вероятности будет обрабатываться транспортным уровнем (по классификации модели OSI).
Сложность установления факта, что произошла именно коллизия, связана с функциональными особенностями работы Ethernet сетей.
Анализатор, подключенный к порту 10BASE-5/10BASE-2 в режиме прослушивания, фиксирует коллизию только в случае, если три или более станций начали одновременную передачу; в режиме передачи – сравнивает передаваемые данные с принимаемыми, и при их различии фиксирует коллизию. Порт повторителя 10BASE-5/10BASE-2 должен зафиксировать коллизию если две или больше станций начали одновременную передачу.
Порт 10BASE-T/100BASE-T фиксирует коллизию только в том случае, если во время передачи у него на приемном порту появился сигнал. Соответственно анализатор сети 10BASE-T/100BASE-T, работающий в режиме прослушивания, даже теоретически не может зафиксировать коллизию.
Однако даже если мы увидели, что действительно произошло наложение (искажение содержимого), а не просто получили поврежденный пакет, все равно однозначно не известно, что именно вызвало наложение, и произошло ли оно во время нормальной работы.
способы обнаружения коллизий и ошибок
В результате диагностики мы всегда видим только результат коллизии или ошибки – пакет с неверной контрольной суммой или вообще “мусор”. К тому же после наложения пакетов можно увидеть МАС-адрес только первого пакета, да и то только в том случае если наложение произошло после его заголовка. Понять, что было причиной сбоя – ошибка или коллизия, и какое именно сетевое оборудование вызвало сбой, – можно только косвенными способами.
На первый вопрос можно ответить достаточно просто. Если в сегменте нет поврежденных пакетов, превышающих 64 байта (притом, что пакеты более 64 байт используются), можно практически с полной уверенностью говорить о том, что это только коллизии. В случае, если зафиксированы даже единичные поврежденные пакеты более 64 байт, пакеты менее 64 байт тоже могут быть вызваны сбоем работы сети.
Для определения оборудования, вызывающего коллизии, GNNettest рекомендует поочередно отключать оборудование и контролировать уровень коллизий. Естественно, данный способ применим только в том случае, если других вариантов нет.
Observer для выявления коллизий и подозрительных станций создает небольшую нагрузку сети и контролирует станции, начавшие передачу
непосредственно до или после коллизии.
Искать оборудование, которое вызывает коллизии, особого смысла не имеет, так как крайне маловероятно, что коллизии будут создавать проблемы в работе сети. Как будет видно ниже из эксперимента, при уровне коллизий около 5% работоспособность сети остается на приемлемом уровне.
эксперимент по исследованию влияния коллизий и ошибок на скорость работы приложения
Были проведены два эксперимента. В первом исследовалась зависимость скорости работы приложения от коллизий, во втором – зависимость скорости работы приложения от ошибок. Несмотря на некоторый архаизм исходных данных (10-мегабитная сеть, транспортный протокол SPX), эксперимент получился достаточно поучительный.
Схема стенда приведена на рис. 4.
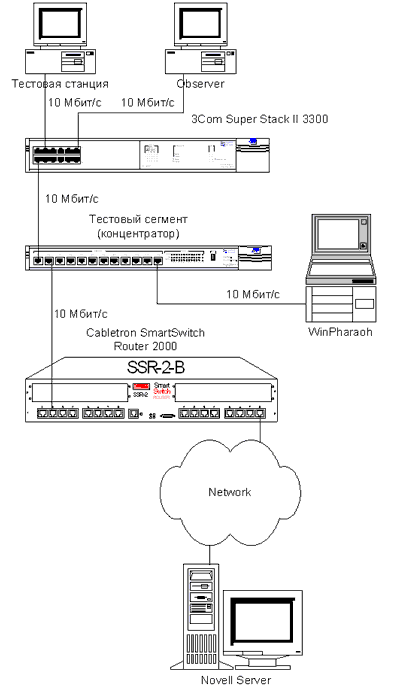
Рис. 4. Схема стенда.
В качестве тестового приложения на рабочей станции запускалась задача обращения к файловой базе на сервере Novell, транспортный протокол – SPX. Используемая задача при работе в сети только сервера и клиента загружает канал 10 Мбит/с примерно на 3,6% и выполняется в течение 1,03 мин. Для исследования коллизий между коммутаторами был создан сегмент сети Ethernet. Коммутаторы Cabletron SmartSwitch Router 2000 и 3Com Super Stack II 3300 были подключены через концентратор 10 Мбит/с. Подобный канал можно было бы создать и путем конфигурации портов коммутаторов в режим 10 Мбит/с HalfDuplex, но концентратор также предназначался для подключения аппаратно-программного анализатора WinPharaoh, с помощью которого создавалась изменяющаяся фоновая нагрузка данного сегмента сети. Для создания в сети ошибок CRC (потерь пакетов с их повтором), порт коммутатора 3Com Super Stack II 3300, подключенный к концентратору, принудительно переводился в режим 10 Мбит/с FullDuplex. Кстати, это весьма распространенная ошибка конфигурирования активного сетевого оборудования. В результате Super Stack II 3300 не “слушал” сеть, и пакеты уничтожались при столкновении с пакетами от WinPharaoh. Статистика количества коллизий и ошибок снималась с порта Super Stack II 3300, подключенного к концентратору, с помощью RMON-модуля Observer.
Нагрузка в сети создавалась искусственным образом и никак не зависела от сетевых ошибок. Если бы нагрузка создавалась реальными приложениями, она бы снижалась при появлении ошибок и коллизий. Сервер был подключен через слабо загруженную рабочую сеть, нагрузка сервера другими пользователями не контролировалась. Однако эти условия крайне мало влияли на результат тестирования, в чем можно будет убедиться далее. Тестирование проводилось поэтапно. На каждом этапе нагрузка тестового сегмента сети с помощью WinPharaoh увеличивалась на 10%, одновременно измерялась общая нагрузка тестового сегмента, которая состояла из нагрузки от WinPharaoh и нагрузки от приложения. Среднее количество коллизий и ошибок в секунду в тестовом сегменте, то есть их относительное число, измерялось с помощью опции анализатора Observer - Ethernet Vital Signs. Так как их количество во время выполнения тестовой задачи колебалось значительно, приведены минимальные и максимальные значения.
Перейдем к результатам тестирования. В первом тесте (таблица 2) видно, что при нагрузках сети до 60% время выполнения тестовой задачи росло незначительно. После 70% время выполнения тестовой задачи начинает резко расти, уменьшается нагрузка сети от тестовой задачи и начинает уменьшаться количество коллизий. Во-первых, столь большое количество коллизий, достигающее 180 в секунду при нагрузке сети 63,9%, слабо влияет на скорость работы тестового приложения. Во-вторых, относительное количество коллизий начинает снижаться после достижения пика производительности сети. Практически такой же эффект наблюдается при анализе ошибок и говорит только об одном – в результате слишком большого количества коллизий и ошибок начинает падать скорость работы приложения в сети, а соответственно, и относительное количество коллизий и ошибок.
Таблица 2. Результаты первого теста.
Во втором тесте (таблица 3) при 10% нагрузке сети время выполнения тестового задания начинает катастрофически расти, и уже при 50% нагрузке стало бессмысленным продолжать тестирование. Однако относительное количество ошибок в десятки раз меньше и на первый взгляд практически не может влиять на работу сетевых приложений.
Для понимания результатов экспериментов разберемся, как в сети отрабатываются коллизии и ошибки. В случае возникновения коллизии сетевой интерфейс сам повторяет передачу пакета, и происходит это примерно за 0,5 мсек. Повтором уничтоженных пакетов занимается по тайм-ауту транспортный уровень протокола передачи и, естественно, он не может быть столь малым, как в случае коллизии. Начальное значение тайм-аута для данного тестирования составляет примерно 0,2 сек. Данные были получены с помощью WinPharaoh при анализе захваченных пакетов. Учитывая время передачи уничтоженного пакета и обработки ошибки, суммарное время повтора составляет примерно 0,5 сек, что в тысячу раз дольше, чем для обработки коллизии. Начальные и последующие значения тайм-аута повтора на транспортном уровне зависят от протокола и могут вычисляться на основе средней скорости передачи.
Таблица 3. Результаты второго теста.
Из проведенных экспериментов видно, что коллизии мало влияют на производительность сети. Даже при уровне до 5% от всех переданных пакетов скорость работы приложения падала не значительно. В то же время при единичных случаях ошибок CRC скорость упала катастрофически, и сеть стала практически неработоспособной.
Пример 1.Поиск причин неработоспособности некоторых приложений, после переподключения компьютеров с концентратора на коммутатор.
Проблемы в сети: после переподключения отдела программистов с концентратора на коммутатор некоторые приложения на нескольких компьютерах перестали работать в сети. Проблемы были только на компьютерах с картами на одинаковых чипах.
Методика и средства. Диагностика проводилась с помощью RMON модуля анализатора Observer.
Результаты. Было зафиксировано большое количество ошибок Alignment Error на портах коммутатора. В результате более подробного разбирательства с сетевыми картами было установлено, что вероятность сбоя напрямую зависит от размера передаваемого пакета. И если пакеты размером 64 байта передавались практически без проблем, то пакеты максимальной длины практически всегда вызывали сбой на порту коммутатора. Аналогичные результаты были получены и при работе этих сетевых карт с коммутаторами разных производителей. Никаких ошибок при работе с концентраторами зафиксировано не было.
Вывод. Единственным выводом в данной ситуации может быть только то, что сетевые карты неисправны и во время передачи начинают терять синхронизацию.
Примечание. Можно лишь предполагать, почему сетевые карты работали с концентраторами. Возможно, концентраторы более либерально относятся к форме и синхронизации импульсов, к тому же они выступают в роли повторителей, улучшая физические характеристики сигнала. Для того, чтобы с этим досконально разобраться, необходим записывающий осциллограф, работающий на частоте 10 МГц. Но это уже неоправданная роскошь, сетевую карту стоимостью $10 никто ремонтировать не будет, ее проще заменить.
Рекомендация: заменить сетевые карты.
продолжение следует.
Сергей Поповский, z_7@mail.ru.
Развитие информационных технологий привело к полному объединению ранее разрозненных элементов систем получения, обработки и передачи информации. Сейчас мы можем в полной мере говорить о существовании информационных систем (ИС), которые включают в себя программное обеспечение (ПО), серверы, персональные компьютеры, сети, телефоны, системы видеоконференций и безопасности и т.д. Таким образом, ИС – это совокупность всех элементов, предназначенных для обеспечения работы приложения.
Бурное развитие и усложнение информационных технологий привело к тому, что обслуживающий персонал все больше разделяется по специализациям (программисты, специалисты по сетям и электронной технике и т.д.); усложняется контроль и диагностика элементов ИС. В то же время сквозная диагностика ИС требует комплексного подхода и понимания работы всех элементов ИС.
К сожалению, данным вопросом практически никто не занимается, имеющиеся книги или описывают проблему в общих чертах, или рассказывают о задачах и методах решения применительно к конкретному оборудованию. В данном материале рассмотрены средства и методики проведения сквозной диагностики, то есть полной диагностики всех элементов и уровней ИС.
Диагностика ИС рассматривается в основном на примере Ethernet-сетей и Intel-совместимых компьютеров.
Примеры приводятся в виде задач, то есть вначале описываются симптомы проблемы, проведенные действия, полученные результаты и только в конце выводы.
элементы информационной системы
ИС состоит из взаимосвязанных элементов, которые можно с точки зрения диагностики представить в виде четырех уровней.
Элементы (уровни) ИС начиная с нижнего:
1. пассивное оборудование;
2. активное оборудование;
3. драйверы и сервисы ОС;
4. приложение (ПО).
Очень важно понимать, что все уровни взаимосвязаны и появление проблем в каком-либо из элементов всегда проявляется на более высоких уровнях. Однако, обнаружив проблемы на уровне приложения (например, замедление работы ПО), невозможно понять, на каком уровне они возникли. Из этого следует основное правило – диагностику необходимо проводить пошагово, на всех уровнях, начиная с нижнего.
На каждом уровне применяются свои средства диагностики. Заранее стоит предостеречь – ни одно из средств не делает выводов и не говорит о причинах проблемы. Это всегда приходится делать эксперту.
уровень пассивного оборудования
Пассивным оборудованием являются:
1. магистральные кабели;
2. кабели горизонтальной подсистемы;
3. информационные розетки;
4. рабочие соединительные кабели;
5. соединительные панели;
6. коммутационные шнуры.
Диагностика пассивного оборудования проводится кабельными тестерами. Они подразделяются на 3 группы:
1. простейший тестер;
2. кабельный тестер;
3. совмещенный кабельный тестер и сетевой анализатор.
Первые определяют правильность разводки витой пары, обрывы, короткое замыкание, а также показывают расстояние до обрыва или короткого замыкания. Стоят они в десятки раз меньше, чем кабельные тестеры.
Кабельные тестеры проводят полную диагностику состояния кабельной системы и сертифицируют ее на соответствие определенной категории. Также они могут иметь минимальные функции по мониторингу сети (загрузка сегмента, ошибки и т.д.) и возможность фиксирования внешних импульсных помех. Приборы третьей группы не могут соперничать ни с тестерами, ни с сетевыми анализаторами. В первую очередь они предназначены для выявления несложных и часто встречающихся проблем.
диагностика пассивного оборудования
Методика диагностики довольно простая – достаточно нажать только одну кнопку на кабельном тестере, чтобы получить полный отчет о состоянии пассивного оборудования и соответствии его определенной категории.
На рисунке 1 представлен пример отчета тестера OMNIScanner 2.
Рис. 1. Образец отчета кабельного тестера OMNIScanner 2.
В недавно построенных сетях проблемы с пассивным оборудованием практически не возникают, так как системные интеграторы стараются придерживаться стандартов и тестируют кабельную систему при сдаче. В старых сетях наиболее часто проблемы возникают при подключении компьютеров UTP-кабелем горизонтальной проводки к активному оборудованию и неправильной прокладкой и подключением коаксиальных кабелей.
Проблемы, возникающие на уровне пассивного оборудования, можно разделить на две основные группы:
1. нарушение стандартов при проектировании и установке пассивного оборудования;
2. внешнее воздействие на пассивное оборудование.
Диагностирование проблем первой группы представляет собой наиболее простую задачу, так как стандартизованы не только пассивное оборудование, но и правила его установки.
Проблемы второй группы диагностировать очень тяжело. Если в сети возникают ошибки, то с помощью доступных средств диагностики практически невозможно понять, что их вызывает. Если помеха от электроприбора накладывается на передаваемый пакет – мы просто увидим пакет с неверной суммой CRC. То же самое мы увидим и во время коллизии. Конечно, если мы увидим некий “мусор” без положенной для пакета преамбулы, можно предполагать, что это внешняя помеха. Однако существует вероятность того, что наложение пакетов произошло во время передачи преамбулы. С достаточной долей уверенности можно говорить о причинах ошибок после нагрузочного тестирования. Ошибки уровня пассивного оборудования слабо влияют на скорость работы компьютеров, и их количество не увеличивается с повышением нагрузки тестирования. Если ошибки вызваны более высокими уровнями – скорость работы компьютеров в сети падает катастрофически.
Импульсные помехи на кабеле без подключенного активного оборудования может обнаруживать OMNIScanner 2. Он регистрирует импульсы, превышающие 30 mv. Согласно тестам, проведенным компанией ITT NS&S, наводки от 38 до 123 mv в зависимости от пары начинают появляться при внешнем шуме 3 v/m. Также специалисты ITT NS&S утверждают, что при этих помехах концентратор показывал загрузку в сети более 80% (при отсутствии передачи данных). Однако по следующим причинам к данному тесту стоит относиться весьма скептически:
- компания откровенно продвигает свои экранированные кабельные системы;
- непонятно, что за кабель неэкранированной витой пары они использовали;
- концентратор не может служить измерительным устройством;
- не проверялось воздействие на передаваемые данные.
Да, в кабеле появились наводки, но остался невыясненным вопрос – как же все-таки они повлияют на реально передаваемые данные, тем более на современном оборудовании (тест проводился в 1995 году). К сожалению, никакой другой информации по внешним помехам найти не удалось, что свидетельствует о непроработанности данной проблемы. Практически невозможно ответить на вопрос: как внешние шумы повлияют на передаваемые данные. Даже если и будет зафиксировано изменение передаваемого сигнала при определенном уровне помех (для чего нужен записывающий осциллограф) – нельзя сказать, что точно такие же помехи вызовут сбой на другой кабельной системе с другим активным оборудованием. Мои эксперименты с OMNIScanner 2 показали, что в то время, когда OMNIScanner 2 регистрировал импульсные шумы, аппаратный анализатор WinPharaoh не зафиксировал никаких ошибок при передачи данных.
Несмотря на то, что диагностирование внешних помех является достаточно сложной задачей, нахождение проблемы достаточно простое. Обычно сами администраторы предупреждают о холодильниках и электрощитах. О них следует вспомнить, когда вы провели полную диагностику и не нашли причин ошибок в сети. Недопущение подобных проблем еще более простое – следуйте стандартам на установку пассивного оборудования.
Теперь приведем несколько примеров – будут описаны реальные случаи проблем с пассивным оборудованием.
Пример 1.Диагностика сети на 100 пользователей, ориентированной на бухгалтерские задачи.
Проблемы в сети: периодическое пропадание связи с сервером Oracle.
этап 1
Цель: предварительное обследование.
Структура ЛВС. В результате предварительного обследования было выяснено, что в сети находится несколько серверов под управлением OS Novell, а в качестве системы управления базами данных используется Oracle. Компьютерная сеть построена с использованием только концентраторов. Существует центральный коммутационный шкаф, в котором находится концентратор 3Com SuperStack II Dual Speed Hub 500 и подключенные к нему концентраторы SynOptics. Удаленные комнаты имеют свои концентраторы, подключенные к 3Com. Таким образом, сеть существует в виде одного сегмента. К нему подключено около 100 пользователей. Кабель горизонтальной проводки обжат в вилки RJ-45 и напрямую подключен к активному оборудованию. Методика и средства. Диагностика сети проводилось во время обычной работы пользователей в сети с помощью аппаратно-программного анализатора WinPharaoh компании GNNettest. Анализатор подключался к каждому концентратору в центральном коммутационном шкафу.
Результаты. Статистическая система анализатора зафиксировала достаточно большое количество ошибок типа Bad CRC и Runt.
этап 2
Методика тестирования и средства. Тестирование сети проводилось на следующий день во время обычной работы пользователей в сети с помощью аппаратно-программного анализатора WinPharaoh компании GNNettest. Никаких изменений после первого тестирования замечено не было. Выборочно была проверена кабельная проводка с помощью PentaScanner. Исследовались линии подключения серверов, отдельных сегментов и пользователей к центральному коммутационному шкафу.
Результаты: на линии 700 был обнаружен разрыв 6-го провода витой пары, на линии 10 – 6 и 4-го.
Вывод: c большой долей вероятности можно предположить, что плохие контакты в витой паре и являются источником снижения помехоустойчивости витой пары, а соответственно и обнаруженных в ЛВС ошибок. Повреждения кабельной системы обусловлены тем, что кабельная проводка ЛВС выполнена с грубыми нарушениями стандартов.
Рекомендации: до следующих этапов диагностики необходимо полностью заменить кабельную проводку.
На самом деле довольно сложно понять, что именно вызывает ошибки в сети, однако в данном случае во время дополнительных работ по диагностике было выявлено следующее: работа компьютеров в сети не замедляется и не влияет на количество ошибок, что свидетельствует о возникновении ошибок на уровне пассивного оборудования. В любом случае, в кабельной системе были найдены проблемы, и их необходимо было устранять.
Пример 2.Диагностика городской оптической сети, объединяющей несколько крупных локальных сетей.
Цель: выявление причин крайне медленной работы компьютеров в сети.
Структура ЛВС. В результате предварительного обследования было выяснено, что сеть объединяет несколько зданий и построена с помощью повторителей, расстояние между максимально удаленными точками – 5 км.
Методика и средства. Диагностика сети проводилось во время обычной работы пользователей в сети с помощью аппаратно-программного анализатора WinPharaoh компании GNNettest. Анализатор подключался к сегменту сети.
Результаты. Статистическая система анализатора зафиксировала большое количество ошибок типа Bad CRC, ALIGNMENT и JABBER.
Вывод: превышен диаметр коллизионного домена, что вызывает повреждение и ошибки в сети.
Рекомендации: сегментировать сеть. Проводить диагностику данной сети особого смысла не было, так как после первых же вопросов о топологии выяснилось, что превышен диаметр коллизионного домена, поэтому и ожидать чего-то иного от этой сети не приходилось.
уровень активного оборудования
Под активным оборудованием условимся понимать устройства, занимающиеся передачей и приемом информации в сети. Это коммутаторы, концентраторы, маршрутизаторы, сетевые адаптеры сетевые сервисные устройства и т.д. Нас интересует только их работа на физическом и канальном уровне модели OSI, то есть работа их сетевых интерфейсов.
Проблемы активного оборудования можно разделить на две основные группы:
1. поломка оборудования;
2. неверная настройка.
Методика диагностики не зависит от того, к какой группе принадлежит проблема, но понимание этого деления необходимо для правильного решения проблемы.
Проблемы на уровне оборудования проявляются только в виде ошибочных сетевых пакетов. Для их выявления необходим сетевой анализатор. Сетевые анализаторы подразделяются на программные и программно-аппаратные. Первые представляют собой программы, запускаемые на обычных компьютерах (ноутбуках). Программно-аппаратные состоят из специализированных аппаратных решений, предназначенных для диагностики сетей с различными интерфейсами, и программных средств, исполняемых на отдельном или интегрированном компьютере. И то и другое решение имеет свои плюсы и минусы.
Программные анализаторы:
- дешевле, чем аппаратные;
- имеют больший набор функций;
- проще обновляются.
Аппаратные анализаторы:
- могут иметь одновременно различные интерфейсы;
- имеют интерфейсы, с которыми не могут работать компьютеры;
- не зависят от производительности компьютера (подключаемый компьютер предназначен для отображения результатов диагностики, выполненного аппаратным интерфейсом);
- доподлинно отображают все происходящее на канальном уровне.
Методику и примеры диагностики канального уровня сетей Ethernet будем рассматривать на базе аппаратно-программного анализатора WinPharaoh компании GNNettest).
Диагностику транспортного и более высоких уровней – на базе анализатора Observer компании Network Instruments. Изображение Observer приведено на рис. 2.
Рис. 2. Observer.
Не будем подробно останавливаться на функциях и возможностях сетевых анализаторов, определимся только с наиболее необходимыми из них для полноценной диагностики. Анализатор должен уметь:
- захватывать трафик;
- отображать трафик во время захвата;
- декодировать пакеты;
- отображать сетевые ошибки;
- проводить долговременный сбор статистики с последующим сравнением по выбранным диапазонам;
- анализировать потоки как минимум на 2 и 3 уровне модели OSI;
- фиксировать повтор передачи пакетов;
- проводить стрессовое тестирование;
- создавать отчеты;
- сигнализировать о проблемах в сети;
- снимать и протоколировать статистику с сетевых устройств по протоколам SNMP и RMON;
- показывать скорость потока и задержки от каждой из передающих сторон в реальном режиме времени;
- работать с удаленными агентами.
Если с аппаратными анализаторами все ясно, – они предназначены для того, чтобы диагностировать сети – то на некоторых вопросах в использовании программных анализаторов следует остановиться подробнее.
Для того, чтобы диагностировать сеть, ее необходимо прослушивать, то есть сетевая карта компьютера, на котором установлен анализатор, должна включаться в режим promiscuous mode (режим передачи уровню драйвера всех захваченных пакетов, а не только отправленных на данный сетевой адаптер). Но если с этим проблем практически не возникает, и карты захватывают из сети все пакеты, то с поврежденными пакетами все гораздо хуже. Сетевые карты их игнорируют, что, в принципе, абсолютно правильно. В качестве решения производители программных анализаторов предлагают вместе со своими продуктами специализированные карты. В компании Network Instruments пошли другим путем, они написали свои драйверы для распространенных сетевых карт.
Существует еще одна проблема. Дело в том, что программный анализатор обрабатывает поступающие из сети данные программно, то есть производительность анализатора зависит от мощности компьютера. Кстати, во время тестирования программных анализаторов с помощью аппаратного выяснилось, что их производительность очень сильно зависит от них самих. Например, Network Monitor показывал загрузку 10Мбит/с сегмента - 60% при 100% нагрузке от аппаратного анализатора, в то время как на этом же компьютере (Windows NT, PII-266, ОЗУ 64М) Observer показал загрузку 100Мбит/с сегмента - 80% при 100% нагрузке. Мощности современных компьютеров достаточно для полной дешифровки и экспертного анализа сетевого трафика канала 100Мбит/с и даже 1000Мбит/с.
диагностика в коммутируемой сети
Диагностика в коммутируемой сети имеет свои особенности, та как подключившись к порту сетевого оборудования, мы можем прослушивать данные, передаваемые только с этого или на этот порт. Для прослушивания данных, передаваемых через другие порты на сетевом оборудовании необходимо включать режим зеркального отображения если, конечно, такая функция в оборудовании есть.
Возможности режима зеркалирования могут отличаться для разного оборудования. Порт, включенный на прослушивание данных с другого порта, может перейти в блокированный режим, и выполнять только функции прослушивания. Некоторое оборудование может позволять перенаправлять данные сразу из нескольких прослушиваемых портов, что, правда, не совсем корректно, и может вызвать потерю части данных. Ошибки, зафиксированные прослушиваемым портом, могут перенаправляться или уничтожаться.
Однако обычно достаточно просмотреть статистику работы портов. Практически любое управляемое активное сетевое оборудование позволяет это сделать при помощи протоколов SNMP (Simple Network Management Protocol - простой протокол сетевого управления) и RMON (Remote MONitoring – удаленный мониторинг). Рассмотрим их возможности, применяемые в диагностике.
По протоколу SNMP можно получить сведения о настройках оборудования, информацию о работе портов. А также можно узнать общее количество широковещательных пакетов, байтов, ошибок, пакетов и отброшенных не ошибочных пакетов за время работы агента SNMP.
SNMP не показывает загрузку канала в процентном отношении. Некоторые средства мониторинга самостоятельно ее рассчитывают на основе данных о принятых и переданных байтах.
В отличие от протокола SNMP, предназначенного в основном для управления, его расширение – протокол RMON – фактически является сетевым анализатором и позволяет собирать большое количество информации о передаваемых данных и работоспособности портов. RMON состоит из 19 групп. Наиболее необходимая при диагностике сети – первая группа (статистика). Из группы статистики мы можем получить следующую информацию о работе порта (общее количество за время работы агента RMON):
- проигнорированных событий – etherStatsDropEvents;
- принятых из сети байт – etherStatsOctets;
- полученных пакетов – etherStatsPkts;
- широковещательных пакетов – etherStatsBroadcastPkts;
- многоадресных пакетов – etherStatsMulticastPkts;
- ошибок CRC – etherStatsCRCAlignErrors;
- пакетов нестандартной длины – etherStatsUndersizePkts и etherStatsOversizePkts;
- пакетов менее 64 байт и ошибкой CRC – etherStatsFragments;
- пакетов более 1518 байт и ошибкой CRC – etherStatsJabbers;
- коллизий – etherStatsCollisions;
- пакетов размером 64 байта – etherStatsPkts64Octets;
- пакетов размером от 65 до 127 байт – etherStatsPkts65to127Octets;
- пакетов размером от 128 до 255 байт – etherStatsPkts128to255Octets;
- пакетов размером от 256 до 511 байт – etherStatsPkts256to511Octets;
- пакетов размером от 512 до 1023 байт – etherStatsPkts512to1023Octets;
- пакетов размером от 1024 до 1518 байт – etherStatsPkts1024to1518Octets.
К сожалению, из-за ограниченных функциональных возможностей сетевое оборудование обычно поддерживает не более четырех групп. А группы после десятой относятся к информации транспортного уровня и оборудованием, работающим только на канальном уровне, поддерживаться не могут.
Также начинает внедряться и новый протокол – SMON (Switch Monitoring), собирающий информацию о работоспособности и передачи данных на уровне интеллектуального ядра устройства.
классификация сбоев работы сетей Ethernet
Четкое деление и классификация сбоев передачи в сетях Ethernet имеет очень важное значение для проведения диагностики, что будет показано на опытах и примерах ниже.
Сбои в сетях Ethernet можно разделить на две группы. Это сбой, в результате которого произошло либо повреждение пакета, либо возникновение нестандартного пакета.
Дальнейшую детализацию лучше всего отобразить в табличном виде (таблица 2).
Таблица 2. Классификация сбоев передачи в сетях Ethernet.
| Результат | Тип сбоя | Причина сбоя |
| повреждение пакета | Fragment ошибка контрольной суммы, пакет менее 64 Байт | коллизия |
| сбойная работа сети | ||
| CRC Error ошибка контрольной суммы, пакет больше 64 Байт | ||
| Jabber ошибка контрольной суммы, пакет больше 1518 Байт | ||
| нестандартный пакет | Undersize верная контрольная сумма, пакет менее 64 Байт | сбойная работа оборудования |
| Oversize верная контрольная сумма, пакет больше 1518 Байт |
Примечание: в случае, если размер пакета не кратен 8, дополнительно фиксируется ошибка выравнивания – Alignment Error. Такая ошибка может встречаться при всех типах повреждения пакетов.
Классификация приведена согласно стандарту RFC 1757 “Remote Network Monitoring Management Information Base”. В качестве примера на рис. 3. приведен фрагмент таблицы etherStatsTable статистики RMON коммутатора 3Com SuperStack II 3300.
Рис. 3. Фрагмент таблицы etherStatsTable статистики RMON коммутатора 3Com SuperStack II 3300.
Повреждение пакета всегда проявляется в виде ошибки контрольной суммы, а вот понять, в результате чего пакет был поврежден – задача сложная и нетривиальная.
Повреждение пакетов может произойти в следующих случаях:
1. в результате наложения пакетов во время нормальной работы сети;
2. если сетевой интерфейс оборудования перестал прослушивать сеть перед передачей;
3. если работающие друг с другом сетевые интерфейсы установлены в разные режимы (FullDuplex< - >HalfDuplex);
4. если превышен диаметр коллизионного сегмента;
5. при повреждении пассивного оборудования;
6. от внешних помех.
Во всех этих случаях сетевой анализатор зафиксирует в сети пакет с неверной контрольной суммой.
различия ошибок повреждения пакетов
Коллизия – столкновение пакетов при одновременной передаче пакетов в сеть двумя или более станциями в одном сегменте, произошедшее во время нормальной работы сети.
Коллизия не является результатом сбоя работы сети. Возникновение ситуации наложения пакетов в сети подразумевается протоколом Carrier Sense, Multiple Access with Collision Detection (CSMA/CD). Самое главное отличие коллизии от ошибки в том, что коллизия обрабатывается и исправляется средствами сетевого интерфейса. В то время как при любом повреждении пакета в результате сбоя работы сети (сбои на физическом уровне; передача данных не соответствует протоколу CSMA/CD или стандартам физического уровня), можно говорить, что в сети произошла ошибка, которая с большой долей вероятности будет обрабатываться транспортным уровнем (по классификации модели OSI).
Сложность установления факта, что произошла именно коллизия, связана с функциональными особенностями работы Ethernet сетей.
Анализатор, подключенный к порту 10BASE-5/10BASE-2 в режиме прослушивания, фиксирует коллизию только в случае, если три или более станций начали одновременную передачу; в режиме передачи – сравнивает передаваемые данные с принимаемыми, и при их различии фиксирует коллизию. Порт повторителя 10BASE-5/10BASE-2 должен зафиксировать коллизию если две или больше станций начали одновременную передачу.
Порт 10BASE-T/100BASE-T фиксирует коллизию только в том случае, если во время передачи у него на приемном порту появился сигнал. Соответственно анализатор сети 10BASE-T/100BASE-T, работающий в режиме прослушивания, даже теоретически не может зафиксировать коллизию.
Однако даже если мы увидели, что действительно произошло наложение (искажение содержимого), а не просто получили поврежденный пакет, все равно однозначно не известно, что именно вызвало наложение, и произошло ли оно во время нормальной работы.
способы обнаружения коллизий и ошибок
В результате диагностики мы всегда видим только результат коллизии или ошибки – пакет с неверной контрольной суммой или вообще “мусор”. К тому же после наложения пакетов можно увидеть МАС-адрес только первого пакета, да и то только в том случае если наложение произошло после его заголовка. Понять, что было причиной сбоя – ошибка или коллизия, и какое именно сетевое оборудование вызвало сбой, – можно только косвенными способами.
На первый вопрос можно ответить достаточно просто. Если в сегменте нет поврежденных пакетов, превышающих 64 байта (притом, что пакеты более 64 байт используются), можно практически с полной уверенностью говорить о том, что это только коллизии. В случае, если зафиксированы даже единичные поврежденные пакеты более 64 байт, пакеты менее 64 байт тоже могут быть вызваны сбоем работы сети.
Для определения оборудования, вызывающего коллизии, GNNettest рекомендует поочередно отключать оборудование и контролировать уровень коллизий. Естественно, данный способ применим только в том случае, если других вариантов нет.
Observer для выявления коллизий и подозрительных станций создает небольшую нагрузку сети и контролирует станции, начавшие передачу
непосредственно до или после коллизии.
Искать оборудование, которое вызывает коллизии, особого смысла не имеет, так как крайне маловероятно, что коллизии будут создавать проблемы в работе сети. Как будет видно ниже из эксперимента, при уровне коллизий около 5% работоспособность сети остается на приемлемом уровне.
эксперимент по исследованию влияния коллизий и ошибок на скорость работы приложения
Были проведены два эксперимента. В первом исследовалась зависимость скорости работы приложения от коллизий, во втором – зависимость скорости работы приложения от ошибок. Несмотря на некоторый архаизм исходных данных (10-мегабитная сеть, транспортный протокол SPX), эксперимент получился достаточно поучительный.
Схема стенда приведена на рис. 4.
Рис. 4. Схема стенда.
В качестве тестового приложения на рабочей станции запускалась задача обращения к файловой базе на сервере Novell, транспортный протокол – SPX. Используемая задача при работе в сети только сервера и клиента загружает канал 10 Мбит/с примерно на 3,6% и выполняется в течение 1,03 мин. Для исследования коллизий между коммутаторами был создан сегмент сети Ethernet. Коммутаторы Cabletron SmartSwitch Router 2000 и 3Com Super Stack II 3300 были подключены через концентратор 10 Мбит/с. Подобный канал можно было бы создать и путем конфигурации портов коммутаторов в режим 10 Мбит/с HalfDuplex, но концентратор также предназначался для подключения аппаратно-программного анализатора WinPharaoh, с помощью которого создавалась изменяющаяся фоновая нагрузка данного сегмента сети. Для создания в сети ошибок CRC (потерь пакетов с их повтором), порт коммутатора 3Com Super Stack II 3300, подключенный к концентратору, принудительно переводился в режим 10 Мбит/с FullDuplex. Кстати, это весьма распространенная ошибка конфигурирования активного сетевого оборудования. В результате Super Stack II 3300 не “слушал” сеть, и пакеты уничтожались при столкновении с пакетами от WinPharaoh. Статистика количества коллизий и ошибок снималась с порта Super Stack II 3300, подключенного к концентратору, с помощью RMON-модуля Observer.
Нагрузка в сети создавалась искусственным образом и никак не зависела от сетевых ошибок. Если бы нагрузка создавалась реальными приложениями, она бы снижалась при появлении ошибок и коллизий. Сервер был подключен через слабо загруженную рабочую сеть, нагрузка сервера другими пользователями не контролировалась. Однако эти условия крайне мало влияли на результат тестирования, в чем можно будет убедиться далее. Тестирование проводилось поэтапно. На каждом этапе нагрузка тестового сегмента сети с помощью WinPharaoh увеличивалась на 10%, одновременно измерялась общая нагрузка тестового сегмента, которая состояла из нагрузки от WinPharaoh и нагрузки от приложения. Среднее количество коллизий и ошибок в секунду в тестовом сегменте, то есть их относительное число, измерялось с помощью опции анализатора Observer - Ethernet Vital Signs. Так как их количество во время выполнения тестовой задачи колебалось значительно, приведены минимальные и максимальные значения.
Перейдем к результатам тестирования. В первом тесте (таблица 2) видно, что при нагрузках сети до 60% время выполнения тестовой задачи росло незначительно. После 70% время выполнения тестовой задачи начинает резко расти, уменьшается нагрузка сети от тестовой задачи и начинает уменьшаться количество коллизий. Во-первых, столь большое количество коллизий, достигающее 180 в секунду при нагрузке сети 63,9%, слабо влияет на скорость работы тестового приложения. Во-вторых, относительное количество коллизий начинает снижаться после достижения пика производительности сети. Практически такой же эффект наблюдается при анализе ошибок и говорит только об одном – в результате слишком большого количества коллизий и ошибок начинает падать скорость работы приложения в сети, а соответственно, и относительное количество коллизий и ошибок.
Таблица 2. Результаты первого теста.
| № | Время выполнения тестовой задачи, мин. | Нагрузка тестового сегмента сети, создаваемая анализатором, % | Нагрузка тестового сегмента сети (анализатор + приложение), % | Среднее количество коллизий в секунду |
| 1 | 1,03 | 10 | 13,8 | 29 |
| 2 | 1,03 | 20 | 23,8 | 60-64,8 |
| 3 | 1,03 | 30 | 33,9 | 77-96 |
| 4 | 1,03 | 40 | 44 | 135-148 |
| 5 | 1,03 | 50 | 54 | 150-170 |
| 6 | 1,10 | 60 | 63,9 | 160-181 |
| 7 | 1,38 | 70 | 73,4 | 138-201 |
| 8 | 2,55 | 80 | 81,2 | 120-150 |
| 9 | 9 | 90 | 90,7 | 68-95 |
| 10 | 17,4 | 99 | 97,8 | 40-60 |
Во втором тесте (таблица 3) при 10% нагрузке сети время выполнения тестового задания начинает катастрофически расти, и уже при 50% нагрузке стало бессмысленным продолжать тестирование. Однако относительное количество ошибок в десятки раз меньше и на первый взгляд практически не может влиять на работу сетевых приложений.
Для понимания результатов экспериментов разберемся, как в сети отрабатываются коллизии и ошибки. В случае возникновения коллизии сетевой интерфейс сам повторяет передачу пакета, и происходит это примерно за 0,5 мсек. Повтором уничтоженных пакетов занимается по тайм-ауту транспортный уровень протокола передачи и, естественно, он не может быть столь малым, как в случае коллизии. Начальное значение тайм-аута для данного тестирования составляет примерно 0,2 сек. Данные были получены с помощью WinPharaoh при анализе захваченных пакетов. Учитывая время передачи уничтоженного пакета и обработки ошибки, суммарное время повтора составляет примерно 0,5 сек, что в тысячу раз дольше, чем для обработки коллизии. Начальные и последующие значения тайм-аута повтора на транспортном уровне зависят от протокола и могут вычисляться на основе средней скорости передачи.
Таблица 3. Результаты второго теста.
| № | Время выполнения тестовой задачи, мин. | Нагрузка тестового сегмента сети, создаваемая анализатором, % | Нагрузка тестового сегмента сети (анализатор + приложение), % | Среднее количество ошибок CRC в секунду |
| 1 | 2 | 10 | 12 | 4,6-7,2 |
| 2 | 3,08 | 20 | 21,3 | 4,5-7,2 |
| 3 | 4,26 | 30 | 31 | 4,5-7,7 |
| 4 | 10,42 | 40 | 40,5 | 0,7-5,7 |
| 5 | 25,40 | 50 | 50,4 | 0,5-4,3 |
| 6 | - | - | - | - |
| 7 | - | - | - | - |
| 8 | - | - | - | - |
| 9 | - | - | - | - |
| 10 | - | - | - | - |
Из проведенных экспериментов видно, что коллизии мало влияют на производительность сети. Даже при уровне до 5% от всех переданных пакетов скорость работы приложения падала не значительно. В то же время при единичных случаях ошибок CRC скорость упала катастрофически, и сеть стала практически неработоспособной.
Пример 1.Поиск причин неработоспособности некоторых приложений, после переподключения компьютеров с концентратора на коммутатор.
Проблемы в сети: после переподключения отдела программистов с концентратора на коммутатор некоторые приложения на нескольких компьютерах перестали работать в сети. Проблемы были только на компьютерах с картами на одинаковых чипах.
Методика и средства. Диагностика проводилась с помощью RMON модуля анализатора Observer.
Результаты. Было зафиксировано большое количество ошибок Alignment Error на портах коммутатора. В результате более подробного разбирательства с сетевыми картами было установлено, что вероятность сбоя напрямую зависит от размера передаваемого пакета. И если пакеты размером 64 байта передавались практически без проблем, то пакеты максимальной длины практически всегда вызывали сбой на порту коммутатора. Аналогичные результаты были получены и при работе этих сетевых карт с коммутаторами разных производителей. Никаких ошибок при работе с концентраторами зафиксировано не было.
Вывод. Единственным выводом в данной ситуации может быть только то, что сетевые карты неисправны и во время передачи начинают терять синхронизацию.
Примечание. Можно лишь предполагать, почему сетевые карты работали с концентраторами. Возможно, концентраторы более либерально относятся к форме и синхронизации импульсов, к тому же они выступают в роли повторителей, улучшая физические характеристики сигнала. Для того, чтобы с этим досконально разобраться, необходим записывающий осциллограф, работающий на частоте 10 МГц. Но это уже неоправданная роскошь, сетевую карту стоимостью $10 никто ремонтировать не будет, ее проще заменить.
Рекомендация: заменить сетевые карты.
продолжение следует.
Сергей Поповский, z_7@mail.ru.
Сетевые решения. Статья была опубликована в номере 08 за 2005 год в рубрике лабораторная работа
