обработка запросов в Apache
Обработка НТТР-запросов - это основная задача большинства сетевых программ. В этой статье мы расскажем об обработке запросов в Apache, и о том, как модули могут вставлять собственные хуки в обработку запроса при создании различных прикладных программ и компонентов. Статья должна помочь разработчикам в освоении работы с модулями Apache, и дать необходимые знания для лучшей работы с документированным API и кодом Apache.
введение
В архитектуру Apache входит: простое ядро, платформо-зависимый уровень (APR) и модули. Любое приложение для Apache - даже простейшее, обсуживающее дефолтовую страницу Apache "It worked" - использует несколько модулей. Пользователи Apache не нуждаются в знании этого, но для разработчика программ понимание модулей и API модуля Apache является ключом к работе с Apache. Большинство модулей (но не все), связаны с различными аспектами обработки НТТР-запроса. Достаточно редко встречается, что модулю необходимо работать с каждым аспектом НТТР: как это делает httpd (Apache). Преимущество модульного подхода заключается в том, что он позволяет фокусировать модуль на специфическую задачу, игнорируя при этом другие аспекты НТТР, не касающиеся данной задачи.
генерация контента
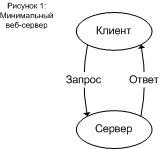
Рис. 1.
Простейшая формулировка понятия «веб-сервер» - программа, ожидающая НТТР-запросы и возвращающая ответы при получении запроса (на рисунке 1 – схема работы простейшего веб-сервера). Это основная задача Apache, так называемое ядро веб-сервера. Для каждого HTTP-запроса должен запускаться генератор контента. Некоторые модули могут регистрировать генераторы контента, определяя функции, ссылающиеся на обработчик, который может быть сконфигурирован директивами SetHandler или AddHandler в httpd.conf. Те запросы, для которых не предоставляется генератор в виде некоторого модуля, обрабатываются стандартным генератором, который просто возвращает запрошенный файл напрямую из файловой системы. Модули, которые реализуют один или более генераторов контента, известны как генераторы контента или обрабатывающие модули.
фазы обработки запроса
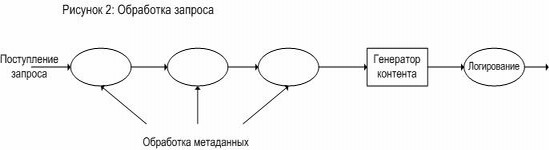
Рис. 2.
В принципе, генератор контента может использовать все функции веб-сервера: например, CGI-программа получает запрос, генерирует ответ и может получить полный контроль над тем, что случится за это время. Но, по аналогии с другими веб-серверами, Apache разбивает запрос на разные фазы. Так, например, он проверяет, авторизован ли пользователь для работы, перед тем, как генератор контента выдаст результат.
Вот несколько фаз обработки запроса до момента генерации контента (см. рис. 2). Они используются для проверки и, возможно, изменений заголовков запроса, и определяют, что делать с запросом. Например:
1. URL запроса нужно сравнить с данными конфигурации, чтобы определить, какой генератор контента должен использоваться.
2. Надо определить файл, на который ссылается URL запроса. URL может обращаться как к статистическому файлу, так и к CGI-скрипту или к чему-либо еще, что может использоваться для генерации контента.
3. Если контент доступен, то mod_negotiation найдет ту версию ресурса, которая лучше подходит к настройкам браузера. Например, страницы справки Apache выводятся на том языке, на котором поступил запрос от браузера.
4. Правила доступа и идентификации модулей проверяются на соответствие правилам доступа сервера, и определяется, имеет ли право пользователь получить то, что он запросил.
5. mod_alias или mod_rewrite могут изменить URL в запросе.
В добавление, есть еще фаза логирования запроса, которая исполняется после того, как генератор контента пошлет браузеру ответ.
Модуль может внедрить свои собственные обработчики в любой из этих хуков. Модули, обрабатывающие данные на фазах до генерации контента, известны как модули метаданных. Те, которые работают с логированием, известны как модули логирования.
ось данных и фильтров
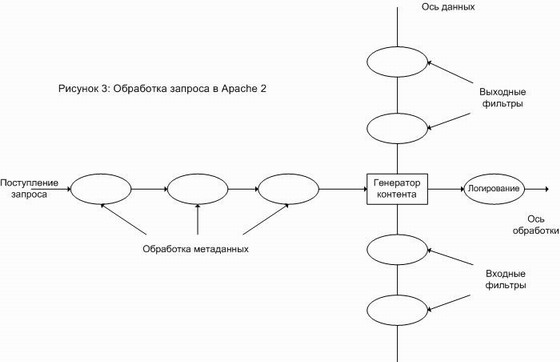
Рис. 3.
Что мы описали выше – это, по существу, архитектура любого веб-сервера. Разница лишь в деталях, но фазы обработки запроса - метаданные- >генератор контента->логирование - являются общими.
Главное нововведение в Apache 2 - это трансформация его из простого веб-сервера (как Apache 1.3 и другие) в мощную платформу, представляющую собой цепочку фильтров (см. рис. 3). Она может быть изображена как ось данных, перпендикулярная оси обработки запроса. Запрошенные данные могут обработаться входными фильтрами до генератора контента, а ответ сервера может обработаться выходными фильтрами до отправки клиенту. Фильтры позволяют сделать предварительную фильтрацию и более эффективно представить данные обработки, отделяя эти фазы от генерации контента. Пример фильтров: включение на стороне сервера (SSI), XML и XSLT, gzip-компрессия и шифрование (SSL).
порядок обработки
Перед началом обсуждения того, как модуль внедряется в любые стадии обработки запроса/данных, давайте остановимся на одном моменте, который часто становится причиной путаницы среди начинающих разработчиков модулей Apache, а именно - на порядке обработки.
Ось обработки запроса линейная: фазы происходят в строгом порядке. Но путаница возникнет на оси данных. Для максимальной эффективности порядок меняется, поэтому генератор и фильтры не выполняются в строго заданной последовательности. Так, например, в общем, вы не сможете передать что- либо во входной фильтр и ожидать получение этого в генераторе или в выходных фильтрах.
В центре обработки находится генератор контента, который отвечает за получение данных из стека входных фильтров и помещает данные в стек выходных фильтров. Когда генератор или фильтр нуждаются в обработке запроса целиком, они должны сделать это до передачи данных вниз по цепочке (генератору или выходным фильтрам), или до возвращения данных обратно входному фильтру. Эту технику мы обсудим в другой статье.
обработка хуков
Теперь у нас есть общее представление об обработке запроса в Apache, и мы можем продолжить говорить о том, как модули становятся частью этой обработки. Структура модуля Apache описывается несколькими (необязательно) полями данных и функциями:
module AP_MODULE_DECLARE_DATA my_module = {
STANDARD20_MODULE_STUFF,
my_dir_conf,
my_dir_merge,
my_server_conf,
my_server_merge,
my_cmds,
my_hooks
} ;
Функция модуля, которая создает хуки обработки запросов, последняя в этой структуре:
static void my_hooks(apr_pool_t* pool) {
/* создание необходимых хуков обработки запроса */
}
В зависимости от того, в каких частях запроса заинтересован наш модуль, нам нужно создать соответствующие хуки. Например, модуль, который реализует генератор контента (обработчик), нуждается в хуке обработки (handler hook), наподобие:
ap_hook_handler(my_handler, NULL, NULL, APR_HOOK_MIDDLE) ;
Теперь my_handler будет вызван, когда обработка запроса дойдет до фазы генерации контента. Хуки других фаз запроса похожи. Также иногда используют один из следующих:
- ap_hook_post_read_request - первый шанс для обработки запроса после его принятия;
- ap_hook_fixups - последний шанс обработки запроса перед генерацией контента;
- ap_hook_log_transaction - хук логирования.
Между хуками post_read_request и fixups есть несколько других хуков, созданных для специфичных целей: например модули доступа и идентификации имеют хуки проверки доступа. Все хуки имеют точно такой же вид, как и хук обработки. Детальную информацию ищите в http_config.h.
Прототип обработчика любой фазы:
static int my_handler(request_rec* r) {
/* обработка запроса */
}
request_rec - это главная структура данных Apache, хранящая всех данные НТТР-запроса.
Возвращаемое значение my_handler может быть следующим:
- OK - my_handler обработал запрос успешно. Фаза обработки завершена.
- DECLINED - my_handler не заинтересован в запросе. Позволим другим обработчикам разобраться с ним.
- некоторый НТТР-код – во время обработки запроса произошла ошибка.
Это изменяет путь обработки запроса: нормальная обработка прекращена и сервер взамен возвращает ErrorDocument.
хуки фильтров
Фильтры также регистрируются в функциях my_hooks, но API немного другой:
ap_register_output_filter("my-output-filter-name", my_output_filter,
NULL, AP_FTYPE_RESOURCE) ;
ap_register_input_filter("my-input-filter-name", my_input_filter,
NULL, AP_FTYPE_RESOURCE) ;
со следующими прототипами функций фильтров:
static apr_status_t my_output_filter(ap_filter_t* f, apr_bucket_brigade* bb) {
/* Чтение блока данных, обработка и передача следующему фильтру*/
return APR_SUCCESS ;
}
static apr_status_t my_input_filter(ap_filter_t* f, apr_bucket_brigade* bb,
ap_input_mode_t mode, apr_read_type_e block, apr_off_t nbytes) {
/* получение блока от следующего фильтра, обработка, возврат блока в bb*/
return APR_SUCCESS ;
}
Если все нормально функции фильтров возвращают APR_SUCCESS либо явно, подобно вышеперечисленным, либо как код возврата от следующего фильтра через вызов ap_pass_brigade или ap_get_brigade. Документация API находится в util_filter.h.
структура данных запроса
Центральная структура, которая описывает НТТР-запрос - это request_rec. Она создается, когда Apache принимает запрос, и она предоставляется всем функциям обработки запроса как показано выше в прототипе my_handler. В фильтре контента request_rec доступна как f->r.
request_rec - это огромная структура, содержащая - прямо или косвенно - все данные, необходимые в процессе обработки запроса. Любой обработчик метаданных работает через получение и изменение полей в request_rec; так поступают генератор контента и фильтры, также себя ведут дополнительные процессы I/О и обработчик логирования. Для полного описания, смотрите заголовочный файл httpd.h.
Мы заканчиваем эту статью, вкратце рассказав об использовании request_rec. Вам необходимо также посмотреть на API или другие статьи, где описаны детали использования этой структуры.
ответы на часто задаваемые вопросы
1. Пул запроса r->pool доступен для всех созданных ресурсов и имеет время жизни запроса.
2. Заголовки запроса и ответа доступны в r->headers_in и r->headers_out соответственно. Они имеют тип apr_table_t и обрабатываются apr_table функциями, такие как apr_table_get и apr_table_set.
3. Поле обработчика определяет, какой обработчик сейчас в действии. Генераторы контента должны проверять его и немедленно возвращать DECLINED, если он не подходит.
4. Поля input_filter и output_filter могут быть использованы как I/O-дескрипторы только в модуле-фильтре. Высокоуровневые I/O (перенесено из apache 1.x) доступны для генераторов контента, но не для фильтров.
5. Директивы конфигурации предоставляются в поле per_dir_config и могут быть получены через использование ap_get_module_config (также ap_set_module_config, хотя это должно быть весьма неуместно во время обработки запроса).
6. Другие структуры данных ядра доступны как r->connection (структура соединения), r->server (структура сервера), и т.п. Их конфигурации также доступны запросу.
7. Дополнительное поле конфигурации request_config обновляется для каждого запроса и сохраняет данные запроса между фазами обработки текущего запроса.
Ник Кью (Nick Kew), перевод ApacheDev.ru.¶
введение
В архитектуру Apache входит: простое ядро, платформо-зависимый уровень (APR) и модули. Любое приложение для Apache - даже простейшее, обсуживающее дефолтовую страницу Apache "It worked" - использует несколько модулей. Пользователи Apache не нуждаются в знании этого, но для разработчика программ понимание модулей и API модуля Apache является ключом к работе с Apache. Большинство модулей (но не все), связаны с различными аспектами обработки НТТР-запроса. Достаточно редко встречается, что модулю необходимо работать с каждым аспектом НТТР: как это делает httpd (Apache). Преимущество модульного подхода заключается в том, что он позволяет фокусировать модуль на специфическую задачу, игнорируя при этом другие аспекты НТТР, не касающиеся данной задачи.
генерация контента
Рис. 1.
Простейшая формулировка понятия «веб-сервер» - программа, ожидающая НТТР-запросы и возвращающая ответы при получении запроса (на рисунке 1 – схема работы простейшего веб-сервера). Это основная задача Apache, так называемое ядро веб-сервера. Для каждого HTTP-запроса должен запускаться генератор контента. Некоторые модули могут регистрировать генераторы контента, определяя функции, ссылающиеся на обработчик, который может быть сконфигурирован директивами SetHandler или AddHandler в httpd.conf. Те запросы, для которых не предоставляется генератор в виде некоторого модуля, обрабатываются стандартным генератором, который просто возвращает запрошенный файл напрямую из файловой системы. Модули, которые реализуют один или более генераторов контента, известны как генераторы контента или обрабатывающие модули.
фазы обработки запроса
Рис. 2.
В принципе, генератор контента может использовать все функции веб-сервера: например, CGI-программа получает запрос, генерирует ответ и может получить полный контроль над тем, что случится за это время. Но, по аналогии с другими веб-серверами, Apache разбивает запрос на разные фазы. Так, например, он проверяет, авторизован ли пользователь для работы, перед тем, как генератор контента выдаст результат.
Вот несколько фаз обработки запроса до момента генерации контента (см. рис. 2). Они используются для проверки и, возможно, изменений заголовков запроса, и определяют, что делать с запросом. Например:
1. URL запроса нужно сравнить с данными конфигурации, чтобы определить, какой генератор контента должен использоваться.
2. Надо определить файл, на который ссылается URL запроса. URL может обращаться как к статистическому файлу, так и к CGI-скрипту или к чему-либо еще, что может использоваться для генерации контента.
3. Если контент доступен, то mod_negotiation найдет ту версию ресурса, которая лучше подходит к настройкам браузера. Например, страницы справки Apache выводятся на том языке, на котором поступил запрос от браузера.
4. Правила доступа и идентификации модулей проверяются на соответствие правилам доступа сервера, и определяется, имеет ли право пользователь получить то, что он запросил.
5. mod_alias или mod_rewrite могут изменить URL в запросе.
В добавление, есть еще фаза логирования запроса, которая исполняется после того, как генератор контента пошлет браузеру ответ.
Модуль может внедрить свои собственные обработчики в любой из этих хуков. Модули, обрабатывающие данные на фазах до генерации контента, известны как модули метаданных. Те, которые работают с логированием, известны как модули логирования.
ось данных и фильтров
Рис. 3.
Что мы описали выше – это, по существу, архитектура любого веб-сервера. Разница лишь в деталях, но фазы обработки запроса - метаданные- >генератор контента->логирование - являются общими.
Главное нововведение в Apache 2 - это трансформация его из простого веб-сервера (как Apache 1.3 и другие) в мощную платформу, представляющую собой цепочку фильтров (см. рис. 3). Она может быть изображена как ось данных, перпендикулярная оси обработки запроса. Запрошенные данные могут обработаться входными фильтрами до генератора контента, а ответ сервера может обработаться выходными фильтрами до отправки клиенту. Фильтры позволяют сделать предварительную фильтрацию и более эффективно представить данные обработки, отделяя эти фазы от генерации контента. Пример фильтров: включение на стороне сервера (SSI), XML и XSLT, gzip-компрессия и шифрование (SSL).
порядок обработки
Перед началом обсуждения того, как модуль внедряется в любые стадии обработки запроса/данных, давайте остановимся на одном моменте, который часто становится причиной путаницы среди начинающих разработчиков модулей Apache, а именно - на порядке обработки.
Ось обработки запроса линейная: фазы происходят в строгом порядке. Но путаница возникнет на оси данных. Для максимальной эффективности порядок меняется, поэтому генератор и фильтры не выполняются в строго заданной последовательности. Так, например, в общем, вы не сможете передать что- либо во входной фильтр и ожидать получение этого в генераторе или в выходных фильтрах.
В центре обработки находится генератор контента, который отвечает за получение данных из стека входных фильтров и помещает данные в стек выходных фильтров. Когда генератор или фильтр нуждаются в обработке запроса целиком, они должны сделать это до передачи данных вниз по цепочке (генератору или выходным фильтрам), или до возвращения данных обратно входному фильтру. Эту технику мы обсудим в другой статье.
обработка хуков
Теперь у нас есть общее представление об обработке запроса в Apache, и мы можем продолжить говорить о том, как модули становятся частью этой обработки. Структура модуля Apache описывается несколькими (необязательно) полями данных и функциями:
module AP_MODULE_DECLARE_DATA my_module = {
STANDARD20_MODULE_STUFF,
my_dir_conf,
my_dir_merge,
my_server_conf,
my_server_merge,
my_cmds,
my_hooks
} ;
Функция модуля, которая создает хуки обработки запросов, последняя в этой структуре:
static void my_hooks(apr_pool_t* pool) {
/* создание необходимых хуков обработки запроса */
}
В зависимости от того, в каких частях запроса заинтересован наш модуль, нам нужно создать соответствующие хуки. Например, модуль, который реализует генератор контента (обработчик), нуждается в хуке обработки (handler hook), наподобие:
ap_hook_handler(my_handler, NULL, NULL, APR_HOOK_MIDDLE) ;
Теперь my_handler будет вызван, когда обработка запроса дойдет до фазы генерации контента. Хуки других фаз запроса похожи. Также иногда используют один из следующих:
- ap_hook_post_read_request - первый шанс для обработки запроса после его принятия;
- ap_hook_fixups - последний шанс обработки запроса перед генерацией контента;
- ap_hook_log_transaction - хук логирования.
Между хуками post_read_request и fixups есть несколько других хуков, созданных для специфичных целей: например модули доступа и идентификации имеют хуки проверки доступа. Все хуки имеют точно такой же вид, как и хук обработки. Детальную информацию ищите в http_config.h.
Прототип обработчика любой фазы:
static int my_handler(request_rec* r) {
/* обработка запроса */
}
request_rec - это главная структура данных Apache, хранящая всех данные НТТР-запроса.
Возвращаемое значение my_handler может быть следующим:
- OK - my_handler обработал запрос успешно. Фаза обработки завершена.
- DECLINED - my_handler не заинтересован в запросе. Позволим другим обработчикам разобраться с ним.
- некоторый НТТР-код – во время обработки запроса произошла ошибка.
Это изменяет путь обработки запроса: нормальная обработка прекращена и сервер взамен возвращает ErrorDocument.
хуки фильтров
Фильтры также регистрируются в функциях my_hooks, но API немного другой:
ap_register_output_filter("my-output-filter-name", my_output_filter,
NULL, AP_FTYPE_RESOURCE) ;
ap_register_input_filter("my-input-filter-name", my_input_filter,
NULL, AP_FTYPE_RESOURCE) ;
со следующими прототипами функций фильтров:
static apr_status_t my_output_filter(ap_filter_t* f, apr_bucket_brigade* bb) {
/* Чтение блока данных, обработка и передача следующему фильтру*/
return APR_SUCCESS ;
}
static apr_status_t my_input_filter(ap_filter_t* f, apr_bucket_brigade* bb,
ap_input_mode_t mode, apr_read_type_e block, apr_off_t nbytes) {
/* получение блока от следующего фильтра, обработка, возврат блока в bb*/
return APR_SUCCESS ;
}
Если все нормально функции фильтров возвращают APR_SUCCESS либо явно, подобно вышеперечисленным, либо как код возврата от следующего фильтра через вызов ap_pass_brigade или ap_get_brigade. Документация API находится в util_filter.h.
структура данных запроса
Центральная структура, которая описывает НТТР-запрос - это request_rec. Она создается, когда Apache принимает запрос, и она предоставляется всем функциям обработки запроса как показано выше в прототипе my_handler. В фильтре контента request_rec доступна как f->r.
request_rec - это огромная структура, содержащая - прямо или косвенно - все данные, необходимые в процессе обработки запроса. Любой обработчик метаданных работает через получение и изменение полей в request_rec; так поступают генератор контента и фильтры, также себя ведут дополнительные процессы I/О и обработчик логирования. Для полного описания, смотрите заголовочный файл httpd.h.
Мы заканчиваем эту статью, вкратце рассказав об использовании request_rec. Вам необходимо также посмотреть на API или другие статьи, где описаны детали использования этой структуры.
ответы на часто задаваемые вопросы
1. Пул запроса r->pool доступен для всех созданных ресурсов и имеет время жизни запроса.
2. Заголовки запроса и ответа доступны в r->headers_in и r->headers_out соответственно. Они имеют тип apr_table_t и обрабатываются apr_table функциями, такие как apr_table_get и apr_table_set.
3. Поле обработчика определяет, какой обработчик сейчас в действии. Генераторы контента должны проверять его и немедленно возвращать DECLINED, если он не подходит.
4. Поля input_filter и output_filter могут быть использованы как I/O-дескрипторы только в модуле-фильтре. Высокоуровневые I/O (перенесено из apache 1.x) доступны для генераторов контента, но не для фильтров.
5. Директивы конфигурации предоставляются в поле per_dir_config и могут быть получены через использование ap_get_module_config (также ap_set_module_config, хотя это должно быть весьма неуместно во время обработки запроса).
6. Другие структуры данных ядра доступны как r->connection (структура соединения), r->server (структура сервера), и т.п. Их конфигурации также доступны запросу.
7. Дополнительное поле конфигурации request_config обновляется для каждого запроса и сохраняет данные запроса между фазами обработки текущего запроса.
Ник Кью (Nick Kew), перевод ApacheDev.ru.¶
Сетевые решения. Статья была опубликована в номере 05 за 2005 год в рубрике программирование
