
Что за зверь Ruby, и с чем его едят? Основы Ruby
Продолжение. Начало в КГ №13
Пришло время познакомиться с Ruby поближе, узнать его сильные стороны и научиться их применять. Сегодняшняя статья — это не краткий курс языка Ruby, а лишь демонстрация его возможностей в сравнении с другими популярными языками (C++, Java, C#, Perl). Всем, кому потребуется более подробное описание Ruby, советую обратиться к учебникам на wikipedia.org, а также к классической книге "Programming Ruby. The Pragmatic Programmer's Guide" Дэва Томаса, электронная версия которой есть на ruby-lang.org. Множество полезной документации можно найти также на ruby- doc.org.
В изучении нового языка программирования для меня всегда самым интересным было то, какие типы есть у переменных, и как с ними работать. Целая серия неожиданностей ждала меня с таким нужным для любого программиста типом, как строковый. Например, при переходе с Pascal на C, к своему удивлению, обнаружил, что в языке отсутствует тип string. А при переходе с С на C++ оказалось, что string, конечно, существует, но дико неудобен в использовании и плохо совместим с С'шной эмуляцией строкового типа — "char*". О том, сколько "нежных" чувств испытал при работе с Java и C#, с их переходом от однобайтовых строк к двухбайтовым — вообще молчу. Не будем тянуть кота за хвост и выясним, что там со строками в Ruby. Строки — экземпляры класса String, содержат ряды однобайтовых (ура!) букв и легко преобразуются к массивам байтов. В Ruby строки используют наработки языка Perl, поэтому возможности работы с текстом поистине фантастические. Вот краткий список возможностей строк:
1. Нет ограничений на длину, которая может достигать гигантских размеров. На практике это можно использовать для чтения целого файла в одну строку.
2. Изменяемость. Строки можно расширять, уменьшать и всячески изменять. В C# и Java существует целая технология для работы со строками. Создавать и редактировать строки надо в экземпляре StringBuilder, потом преобразовывать к String... А вот в Ruby все сделано для того, чтобы удобнее было программисту, а не компилятору.
3. Любой объект можно преобразовать к строке. Для этого используются методы to_s() и inspect(), которые есть у любого класса. Обычная, в общем- то, штука для всех новых языков программирования, которую в ближайшее время в С++ включать не собираются.
4. В Ruby реализовано большое количество методов для работы с регулярными выражениями. Здесь они, правда, как и в Perl 6, называются правилами, но сущность их от этого не изменилась.
5. И, наконец, развею мрачные мысли скептиков: в Ruby есть возможность преобразовать однобайтовые кодировки к двухбайтовым, и наоборот. Это, конечно, не так удобно, как в Java и C#, но, на мой взгляд, приемлемо. Насколько мне известно, в планах Ruby 2.0 — решить проблему Unicode кардинальным образом.
Следующий после строк тип, который всегда интересовал меня больше всего — массивы. Когда после С++ я начал изучать C#, то совсем не ожидал худого, полагая, что массив — это просто индексированный набор однотипных объектов. Но в действительно объектноориентированных языках массив — это экземпляр класса, который поддерживает не только индексацию, но и редактирование коллекции, сортировку, знает ее размеры, тип и т.д. Ну что еще можно было добавить к таким интуитивно понятным вещам? Казалось бы, в C# и Java реализованы идеальные массивы, и более мечтать уж и не о чем. Ан нет! Нашлись еще гурманы ООП, у которых циклы for и foreach не вызвали эстетических ощущений.
Так появились итераторы и блоки кода, тесно связанные с контейнерами (массивами и хэшами). Вот три относительно обычных способа создания массива и один необычный:
1. a = [1,2,3,4,5,6] — перечисление в квадратных скобках всех элементов массива.
2. a = (1..6).to_a — указание диапазона и преобразование его методом to_a() к массиву.
3. a = Array.new( 6 ) — явное создание экземпляра класса Array с указанием числа элементов массива.
До сих пор все было просто и достаточно понятно. А если необходимо задать значения элементов массива по более сложному правилу? Пусть, например, по такой формуле: v = 2*i, где v — значение i-го элемента массива. Во всех языках программирования, кроме Ruby, для этого придется использовать минимум три строки кода примерно такого вида:
int[] a = new int[6];
for(int i = 0; i < a.Length; i++) {
a[i] = i * 2;
}
Как видите, здесь нет возможности применить конструкцию foreach, потому что она позволяет лишь считать содержимое элемента массива, но не установить его. А раз так, то остается открытой проблема выхода за границы массива.
Посмотрим теперь, как эта задача решается на Ruby.
a = Array.new( 6 ) { | i | i * 2 }
Вот так, одной строкой кода вместо трех. Конструктор класса Array реализует технологию итератор — блок кода. Поэтому при создании экземпляра Array конструктор проходит по каждому созданному элементу и вызывает для него код, заключенный в фигурных скобках, передавая параметром индекс элемента. Этот параметр для блока кода в фигурных скобках принимается переменной в вертикальных разделителях — " | i | ". Значение, которое вернет блок кода, будет присвоено текущему элементу массива. Напомню: в предыдущей части статьи я рассказывал о том, что любой участок кода возвращает какое-то значение, поэтому оператор return в Ruby хоть и существует, но, как правило, не используется за ненадобностью.
А вот еще одна часто решаемая задача: индексация с конца массива. Вот как выглядит доступ к последнему элементу массива на C#.
v = a[ a.Length — 1]
Эта распространенная конструкция в Ruby имеет сокращенный вид:
v = a[ -1 ]
Отрицательное индексирование — просто удобное сокращение классической записи. А как в Ruby с типизацией? На стадии компиляции ее нет. Хорошо это или плохо — вопрос весьма спорный. В C#, например, типизация тотальная и не позволяет программисту привести объект одного типа к другому. В Perl типизации, как и в Ruby, нет. Просто в зависимости от контекста значение "32" может быть воспринято и как строка, и как число, и как символ пробела, и вообще как что угодно. Такая динамическая типизация чревата проблемами, если программист использует объект класса А как экземпляр класса Б, но зато дает определенные возможности. Так, например, в массивах могут храниться объекты вообще любых типов:
a = [1, 2, "abc", 'd', [3, 4, 5], { 'qaz' => 'wsd', 1 => 2} ]
Здесь мы создали массив, в котором два числа, две строки, массив из трех чисел и хэш из двух пар ключ-значение. Все переменные в Ruby имеют ссылочный тип. Т.е. каждая переменная указывает на объект в памяти. Для клонирования объектов, как и в Java, и в C#, используется специальный метод — clone(). Теперь посмотрим, что в Ruby придумано для реализации ключевой технологии ООП — инкапсуляции. А проще говоря: как в Ruby создаются классы. По идее, ничего особенно революционного здесь придумать уже невозможно. Технология ООП развивается уже не первый десяток лет, и был когда-то SmallTalk... Чем еще можно удивить искушенного программиста? Пожалуй, самая спорная и развивающаяся в синтаксисе языков программирования часть — свойства классов. Если говорить формально, то закрытые переменные класса будем считать его состоянием, а открытые — свойствами. Помните, из далекого Object Pascal, были такие переменные: readable, writeable? Это то самое, что в Java называется getter/setter, а на самом деле — просто методы с префиксами get и set для работы с закрытыми переменными. Первым языком, в котором мне понравилась реализация свойств, был C#. Свойства в C# выглядят как открытые переменные, но на самом деле — просто методы, обеспечивающие правильную инкапсуляцию данных.
Пример:
public int Num {
get {return num; }
set { num = value; }
}
Ruby и здесь на полшага впереди. Вот как выглядит свойство Num в Ruby, написанное в стиле C#:
def Num
@num
end
def Num= (num)
@num = num
end
Но давайте внимательно посмотрим на этот код и подумаем: что в нем лишнее? Если свойство создается лишь для обеспечения инкапсуляции, но при обращении к переменной не происходит никакой дополнительной обработки, то вполне можно было бы написать некий макрос для уменьшения кода. Вот как это делается на Ruby сразу для нескольких переменных:
attr_reader :num, :str, :abc
attr_writer :num, :str, :abc
Улавливаете мысль? Количество исходника опять сокращается в разы, потому что не нужно писать сотни строк совершенно рутинного кода. Отсюда же появляется понятие "виртуального атрибута". Раз реальный атрибут — метод-обертка над переменной, то виртуальный атрибут — метод, возвращающий значение несуществующей переменной. Вот пример:
def AB
@a + @b
end
А еще одна просто обалденная фишка Ruby — использование в именовании методов и атрибутов символов "?" и "!". Вот здесь Ruby впереди планеты всей. Как в тех же Java и C# мы именуем булевские свойства (true/false)? Пра-a-авильно: isFoo, isSomething. В Ruby используется знак "?" для дополнительного указания на то, что полученный ответ будет иметь значение да/нет.
Пример:
b = "abc".include? ('a')
В переменной b результат будет, разумеется, "true".
Методы, которые заканчиваются знаком "!", как правило модифицируют объект, на котором они вызваны. Хотя иногда восклицательный знак говорит о значительности метода. Так, метод Process::exit! завершает программу.
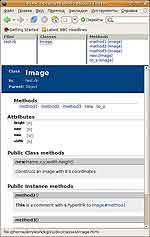 Следующая отличительная особенность Ruby — самодокументирующийся код. Не сказать, что это такая уж инновация. Документация прямо по исходникам автоматически составлялась еще в ранних версиях Perl и, уж конечно, сегодня поддерживается такими могучими технологиями, как Java и .NET. Но, на мой взгляд, у Ruby есть некоторые особенности, которые делают его документирование более удобным. Делается это при помощи утилиты RDoc, которая поставляется вместе с дистрибутивом Ruby. Она изучает состав классов, извлекает документацию, форматирует и создает два вида выходных файлов: html и формат ri. Для того, чтобы создать документацию по классу Java, в код нужно включать специальные комментарии, начинающиеся с символов "/**". В .NET чуть лучше, хотя для документирования также используется особый тип комментария: "///". Для RDoc не нужно никаких особых маркеров. Комментарий перед методом будет добавлен к его описанию. Если в комментарии присутствуют записи в виде "Image#method1", то в документации будет сгенерирована ссылка на метод method1 класса Image. Если слова в комментарии окружить html-тегами форматирования, например, <b> или <i>, то выходной текст получит желаемые атрибуты (рис. 2).
Следующая отличительная особенность Ruby — самодокументирующийся код. Не сказать, что это такая уж инновация. Документация прямо по исходникам автоматически составлялась еще в ранних версиях Perl и, уж конечно, сегодня поддерживается такими могучими технологиями, как Java и .NET. Но, на мой взгляд, у Ruby есть некоторые особенности, которые делают его документирование более удобным. Делается это при помощи утилиты RDoc, которая поставляется вместе с дистрибутивом Ruby. Она изучает состав классов, извлекает документацию, форматирует и создает два вида выходных файлов: html и формат ri. Для того, чтобы создать документацию по классу Java, в код нужно включать специальные комментарии, начинающиеся с символов "/**". В .NET чуть лучше, хотя для документирования также используется особый тип комментария: "///". Для RDoc не нужно никаких особых маркеров. Комментарий перед методом будет добавлен к его описанию. Если в комментарии присутствуют записи в виде "Image#method1", то в документации будет сгенерирована ссылка на метод method1 класса Image. Если слова в комментарии окружить html-тегами форматирования, например, <b> или <i>, то выходной текст получит желаемые атрибуты (рис. 2).
Подводя итог моим рассуждениям, приведу слова знаменитейших специалистов в области IT Абельсона и Сассмана: "Программы должны быть написаны так, чтобы их могли читать люди, и лишь иногда выполнять машины".
Дмитрий Бушенко
Пришло время познакомиться с Ruby поближе, узнать его сильные стороны и научиться их применять. Сегодняшняя статья — это не краткий курс языка Ruby, а лишь демонстрация его возможностей в сравнении с другими популярными языками (C++, Java, C#, Perl). Всем, кому потребуется более подробное описание Ruby, советую обратиться к учебникам на wikipedia.org, а также к классической книге "Programming Ruby. The Pragmatic Programmer's Guide" Дэва Томаса, электронная версия которой есть на ruby-lang.org. Множество полезной документации можно найти также на ruby- doc.org.
В изучении нового языка программирования для меня всегда самым интересным было то, какие типы есть у переменных, и как с ними работать. Целая серия неожиданностей ждала меня с таким нужным для любого программиста типом, как строковый. Например, при переходе с Pascal на C, к своему удивлению, обнаружил, что в языке отсутствует тип string. А при переходе с С на C++ оказалось, что string, конечно, существует, но дико неудобен в использовании и плохо совместим с С'шной эмуляцией строкового типа — "char*". О том, сколько "нежных" чувств испытал при работе с Java и C#, с их переходом от однобайтовых строк к двухбайтовым — вообще молчу. Не будем тянуть кота за хвост и выясним, что там со строками в Ruby. Строки — экземпляры класса String, содержат ряды однобайтовых (ура!) букв и легко преобразуются к массивам байтов. В Ruby строки используют наработки языка Perl, поэтому возможности работы с текстом поистине фантастические. Вот краткий список возможностей строк:
1. Нет ограничений на длину, которая может достигать гигантских размеров. На практике это можно использовать для чтения целого файла в одну строку.
2. Изменяемость. Строки можно расширять, уменьшать и всячески изменять. В C# и Java существует целая технология для работы со строками. Создавать и редактировать строки надо в экземпляре StringBuilder, потом преобразовывать к String... А вот в Ruby все сделано для того, чтобы удобнее было программисту, а не компилятору.
3. Любой объект можно преобразовать к строке. Для этого используются методы to_s() и inspect(), которые есть у любого класса. Обычная, в общем- то, штука для всех новых языков программирования, которую в ближайшее время в С++ включать не собираются.
4. В Ruby реализовано большое количество методов для работы с регулярными выражениями. Здесь они, правда, как и в Perl 6, называются правилами, но сущность их от этого не изменилась.
5. И, наконец, развею мрачные мысли скептиков: в Ruby есть возможность преобразовать однобайтовые кодировки к двухбайтовым, и наоборот. Это, конечно, не так удобно, как в Java и C#, но, на мой взгляд, приемлемо. Насколько мне известно, в планах Ruby 2.0 — решить проблему Unicode кардинальным образом.
Следующий после строк тип, который всегда интересовал меня больше всего — массивы. Когда после С++ я начал изучать C#, то совсем не ожидал худого, полагая, что массив — это просто индексированный набор однотипных объектов. Но в действительно объектноориентированных языках массив — это экземпляр класса, который поддерживает не только индексацию, но и редактирование коллекции, сортировку, знает ее размеры, тип и т.д. Ну что еще можно было добавить к таким интуитивно понятным вещам? Казалось бы, в C# и Java реализованы идеальные массивы, и более мечтать уж и не о чем. Ан нет! Нашлись еще гурманы ООП, у которых циклы for и foreach не вызвали эстетических ощущений.
Так появились итераторы и блоки кода, тесно связанные с контейнерами (массивами и хэшами). Вот три относительно обычных способа создания массива и один необычный:
1. a = [1,2,3,4,5,6] — перечисление в квадратных скобках всех элементов массива.
2. a = (1..6).to_a — указание диапазона и преобразование его методом to_a() к массиву.
3. a = Array.new( 6 ) — явное создание экземпляра класса Array с указанием числа элементов массива.
До сих пор все было просто и достаточно понятно. А если необходимо задать значения элементов массива по более сложному правилу? Пусть, например, по такой формуле: v = 2*i, где v — значение i-го элемента массива. Во всех языках программирования, кроме Ruby, для этого придется использовать минимум три строки кода примерно такого вида:
int[] a = new int[6];
for(int i = 0; i < a.Length; i++) {
a[i] = i * 2;
}
Как видите, здесь нет возможности применить конструкцию foreach, потому что она позволяет лишь считать содержимое элемента массива, но не установить его. А раз так, то остается открытой проблема выхода за границы массива.
Посмотрим теперь, как эта задача решается на Ruby.
a = Array.new( 6 ) { | i | i * 2 }
Вот так, одной строкой кода вместо трех. Конструктор класса Array реализует технологию итератор — блок кода. Поэтому при создании экземпляра Array конструктор проходит по каждому созданному элементу и вызывает для него код, заключенный в фигурных скобках, передавая параметром индекс элемента. Этот параметр для блока кода в фигурных скобках принимается переменной в вертикальных разделителях — " | i | ". Значение, которое вернет блок кода, будет присвоено текущему элементу массива. Напомню: в предыдущей части статьи я рассказывал о том, что любой участок кода возвращает какое-то значение, поэтому оператор return в Ruby хоть и существует, но, как правило, не используется за ненадобностью.
А вот еще одна часто решаемая задача: индексация с конца массива. Вот как выглядит доступ к последнему элементу массива на C#.
v = a[ a.Length — 1]
Эта распространенная конструкция в Ruby имеет сокращенный вид:
v = a[ -1 ]
Отрицательное индексирование — просто удобное сокращение классической записи. А как в Ruby с типизацией? На стадии компиляции ее нет. Хорошо это или плохо — вопрос весьма спорный. В C#, например, типизация тотальная и не позволяет программисту привести объект одного типа к другому. В Perl типизации, как и в Ruby, нет. Просто в зависимости от контекста значение "32" может быть воспринято и как строка, и как число, и как символ пробела, и вообще как что угодно. Такая динамическая типизация чревата проблемами, если программист использует объект класса А как экземпляр класса Б, но зато дает определенные возможности. Так, например, в массивах могут храниться объекты вообще любых типов:
a = [1, 2, "abc", 'd', [3, 4, 5], { 'qaz' => 'wsd', 1 => 2} ]
Здесь мы создали массив, в котором два числа, две строки, массив из трех чисел и хэш из двух пар ключ-значение. Все переменные в Ruby имеют ссылочный тип. Т.е. каждая переменная указывает на объект в памяти. Для клонирования объектов, как и в Java, и в C#, используется специальный метод — clone(). Теперь посмотрим, что в Ruby придумано для реализации ключевой технологии ООП — инкапсуляции. А проще говоря: как в Ruby создаются классы. По идее, ничего особенно революционного здесь придумать уже невозможно. Технология ООП развивается уже не первый десяток лет, и был когда-то SmallTalk... Чем еще можно удивить искушенного программиста? Пожалуй, самая спорная и развивающаяся в синтаксисе языков программирования часть — свойства классов. Если говорить формально, то закрытые переменные класса будем считать его состоянием, а открытые — свойствами. Помните, из далекого Object Pascal, были такие переменные: readable, writeable? Это то самое, что в Java называется getter/setter, а на самом деле — просто методы с префиксами get и set для работы с закрытыми переменными. Первым языком, в котором мне понравилась реализация свойств, был C#. Свойства в C# выглядят как открытые переменные, но на самом деле — просто методы, обеспечивающие правильную инкапсуляцию данных.
Пример:
public int Num {
get {return num; }
set { num = value; }
}
Ruby и здесь на полшага впереди. Вот как выглядит свойство Num в Ruby, написанное в стиле C#:
def Num
@num
end
def Num= (num)
@num = num
end
Но давайте внимательно посмотрим на этот код и подумаем: что в нем лишнее? Если свойство создается лишь для обеспечения инкапсуляции, но при обращении к переменной не происходит никакой дополнительной обработки, то вполне можно было бы написать некий макрос для уменьшения кода. Вот как это делается на Ruby сразу для нескольких переменных:
attr_reader :num, :str, :abc
attr_writer :num, :str, :abc
Улавливаете мысль? Количество исходника опять сокращается в разы, потому что не нужно писать сотни строк совершенно рутинного кода. Отсюда же появляется понятие "виртуального атрибута". Раз реальный атрибут — метод-обертка над переменной, то виртуальный атрибут — метод, возвращающий значение несуществующей переменной. Вот пример:
def AB
@a + @b
end
А еще одна просто обалденная фишка Ruby — использование в именовании методов и атрибутов символов "?" и "!". Вот здесь Ruby впереди планеты всей. Как в тех же Java и C# мы именуем булевские свойства (true/false)? Пра-a-авильно: isFoo, isSomething. В Ruby используется знак "?" для дополнительного указания на то, что полученный ответ будет иметь значение да/нет.
Пример:
b = "abc".include? ('a')
В переменной b результат будет, разумеется, "true".
Методы, которые заканчиваются знаком "!", как правило модифицируют объект, на котором они вызваны. Хотя иногда восклицательный знак говорит о значительности метода. Так, метод Process::exit! завершает программу.
Подводя итог моим рассуждениям, приведу слова знаменитейших специалистов в области IT Абельсона и Сассмана: "Программы должны быть написаны так, чтобы их могли читать люди, и лишь иногда выполнять машины".
Дмитрий Бушенко
Компьютерная газета. Статья была опубликована в номере 15 за 2007 год в рубрике программирование
