
Эффективное программирование 3D-приложений с помощью Irrlicht и Jython. Часть 7
Сегодня мы продолжаем знакомиться со средствами irrlicht. Пока мы работаем только с 2d-графикой. На этот раз научимся выводить на экран текстовые надписи, разумеется, с русскими буквами. Также разберем возможности модуля string, содержащего функции работы со строками. Почти все 3d-движки, и irrlicht — не исключение, перед выводом текста требуют подготовительной работы. Необходимо создать файл, в котором находятся нарисованные буквы. Алгоритм создания шрифта применительно к irrlicht вкратце таков: необходимо перебрать все символы начиная с 32 и нарисовать их в файле bmp. Верхняя граница цикла определяется тем набором символов, который вы хотите использовать.
Например, если вам нужна только латиница и цифры, то можно остановиться на 127. Если нужна кириллица, то цикл идет по 255. Дело в том, что исторически сложилось при создании кодировочной таблицы (кодировочная таблица — это правило отображения символов в их коды или номера) отводить для латиницы нижний диапазон до 127, а верхний диапазон отводить для национальных алфавитов. Эта схема применяется только для таблиц, в которых символ кодируется однобайтовым числом. Диапазон значений байта от 0 до 255. В случае Unicode, где для кодирования символа используется 2 байта, правила игры меняются. Для тренировки откройте Пуск -> Стандартные -> Таблица символов. Внизу таблицы для каждого выбранного символа отображается его код в шестнадцатеричной системе счисления. Используйте стандартный калькулятор windows в инженерном режиме для перевода чисел из шестнадцатеричной с/с в десятичную с/с. Первый символ таблицы — восклицательный знак — имеет код 33 в 10 с/с или же 21 в 16 с/с. Пока, не вдаваясь в подробности, запомните, что для irrlicht отсчет начинается именно с 32 символа (этот символ невидим). Далее очевидно, что для большинства шрифтов ширина символов различается так: буквы "i" меньше, чем буква "щ". Поэтому для разделения графических изображений символов необходимо использовать точки специального цвета. Например, пиксель с координатами 0,0 должен быть желтым, пиксель с координатами 1,0 — красным, пиксель с координатами 2,0 — черным. Здесь мы закодировали используемые цвета для маркировки границ символов. Если ваш шрифт использует красный или желтый цвет для отрисовки символов, то вы должны выбрать другие цвета.
К слову заметить, рисовать шрифт можно любым цветом — практического эффекта это не имеет. Фон, на котором рисуются символы, является черным и кодируется пикселем 2,0. Затем обозначенные цвета применяются по правилу: желтый цвет для левой верхней границы области символа, а красный — для правой нижней границы области символа. Воспользовавшись данным алгоритмом, вы можете рисовать свои шрифты в любом графическом редакторе. Для упрощения сего процесса я написал более продвинутую версию стандартной утилиты irrfonttool в пакете irrlicht (оригинальная утилита на основании выбранного шрифта и размера создает bmp-файл с нарисованными символами). К сожалению, разработчики irrfonttool, как и многие другие англоговорящие программисты, забыли о жителях 1/6 части суши, равно как и об говорящих на китайском, фарси и других языках. Я исправил данную ошибку, добавил несколько новых возможностей и — как же без этого — пару своих ошибок. Загрузить мою версию irrfonttool можно по адресу black-zorro.jino-net.ru/irrlicht/. Теперь следует разобраться с тем, как обрабатывать строки в python|jython. Для работы со строками вам необходимо подключить модуль string. Строки в python могут хранить не только печатные символы, но и специальные символы — например, табулятор, перевод каретки. Также строка может содержать двоичные данные. Хорошая новость для любителей c|c++: в python вы можете забыть об том, что строка — это массив символов с завершающим нулем терминатором. И, следовательно, мы говорим "нет" утомительной возне с контролем за выделением и освобождением памяти. Строка может быть заключена в одинарные или двойные кавычки по вашему выбору. Если у вас есть две строки, идущие друг за другом и разделенные только несколькими пробелами, то python склеит их в одну строку — например:
>>> print len("a" "b")
2
Если вам необходимо создать достаточно длинную строку, содержащую большое количество как одинарных, так и двойных кавычек и вместе с тем ряд символов перехода на новую строку, то рекомендуется использовать синтаксис с тремя одинарными или двойными кавычками — например, так:
>>> print """ hello
... bye, go, stop
... "and" other words on few lines
... """
hello
bye, go, stop
"and" other words on few lines
Для определения длины строки используйте функцию len — например, так:
>>> len("""
... barracuda
... and
... spring
... """)
22
Строки в python, как и во многих других высокоуровневых языках, можно объединять с помощью оператора "+".
>>> "abc" + "cde" """
... barracuda"""
'abccde\nbarracuda'
Для доступа к отдельным символам используйте оператор квадратные скобки с указанием индекса символа, подлежащего извлечению. Удобно, что можно задавать диапазоны символов — например, "начальный_символ : конечный_символ". Более того, каждая из этих двух частей может отсутствовать (разумеется, что не две одновременно). Не забывайте, что отсчет символов идет с нуля. Еще один прием — указание диапазонов с конца строки. Для этого используйте знак минус (как в последнем примере).
>>> "ferrum"[1]
'e'
>>> "ferrum"[3:]
'rum'
>>> "ferrum"[3:5]
'ru'
>>> "ferrum"[:4]
'ferr'
>>> "ferrum"[:-4]
'fe'
Плохая новость при работе со строками в том, что строки в python подобно строкам в java и в отличие от строк-массивов c|c++ не могут быть изменены. Так, если я попытаюсь присвоить символу строки новое значение, будет сгенерирована ошибка:
>>> bar = "ferrum"
>>> bar [5] = 'x'
Traceback (innermost last):
File "<console>", line 1, in ?
TypeError: can't assign to immutable object
Разумеется, переменной можно присвоить новое значение, вычисленное на базе старого. В примере я заменяю третью букву переменной bar на символ "g":
>>> bar = bar [:3] + 'g' + bar[4:]
>>> bar
'fergum'
Теперь рассмотрим уже знакомый нам оператор "%". В части 3 мы использовали его для получения остатка от деления двух чисел. Применительно к строкам "%" действует подобно функции printf из c|c++. Если вы не знакомы с c|c++, то запомните этот прием, очень полезный в ситуации, когда вам нужно вывести некоторое достаточно длинное сообщение пользователю, а в тексте этого сообщения должны присутствовать некоторые переменные, чередующиеся со строками. Можно пойти по классическому пути склеивания нескольких переменных. Но учитывайте, что в python не выполняется автоматического преобразования переменных к типу данных "строка". Это нужно делать явно, что может быть достаточно громоздко.
>>> money = 10
>>> print "money = " + money
Traceback (innermost last):
File "<console>", line 1, in ?
TypeError: unsupported operand type(s) for +: 'str' and 'int'
>>> print "money = " + str(money)
money = 10
>>> print "money = %d" % money
money = 10
Перед оператором "%" находится строка-шаблон. В ней с помощью символов подстановки вы помечаете места, куда будут помещены переменные, список которых размещен после символа "%". В моем примере была только одна переменная "money", если же переменных несколько, то их следует разделять с помощью запятой. Комбинация символов "%d" служит для вставки целой переменной, пара символов "%f" — для вставки вещественного числа, и пара символов "%s" — для вставки строки. Остальные комбинации символов подстановки вы можете найти в любом популярном учебнике по python. Для сравнения строк вы можете применять те же операторы, что и для сравнения целых или вещественных чисел. Следует помнить, что при сравнении символов регистр имеет значение.
>>> print "Python" <= "jython", "Jython" == "jython"
1 0
Для того, чтобы использовать следующие функции, необходимо подключить к скрипту модуль string — в противном случае python не узнает вызываемые функции.
import string
Для преобразования строки в нижний или верхний регистр используйте функцию lower и upper.
>>> print string.lower("BinGo"), string.upper("bAngO")
bingo BANGO
Если вам нужно найти в некоторой строке подстроку, то используйте функцию find, первым параметром которой вы указываете, где будет выполнен поиск, второй параметр указывает, что именно следует найти. Возможно указать третий и четвертый параметры, задающие начальную и конечную позицию подстроки, которая будет извлечена из первого параметра. В случае, если подстрока не будет найдена, функция find вернет значение "-1".
>>> posAv = string.find("gravity", "av")
>>> if posAv == -1:
... print "not found"
... else:
... print "found at ", posAv
...
found at 2
Следующая функция — replace. Ее назначение — заменить в некоторой строке (первый параметр) старое значение (второй параметр) на новое значение (третий параметр). Во втором примере я указал еще четвертый параметр — число, задающее количество первых совпадений, которое будет подвергнуто замене. Так, последняя буква "a" не была заменена на "c".
>>> string.replace("barracuda", "cud", "Gravity")
'barraGravitya'
>>> string.replace("abba", "a", "c", 1)
'cbba'
Интерес также представляют функции для выполнения преобразования строки в число. Раньше мы уже сталкивались с функциями int и float, теперь рассмотрим их подробнее. Функция int получает два параметра: первый — строковое представление числа, второй параметр — основание системы счисления. В третьем примере я пытался преобразовать строку "23" в 2 с/с. Это ошибка, т.к. в 2 с/с числа задаются только комбинацией 0 и 1.
>>> print int("23", 10)
23
>>> print int("23", 16)
35
>>> print int("23", 2)
Traceback (most recent call last):
File "<stdin>", line 1, in ?
ValueError: invalid literal for int(): 23
Функция float, преобразующая строку в вещественное число, необязательных параметров не имеет. Две функции, которые будут нужны нам для того, чтобы понять, как работает python|jython со строками, — это chr и ord. Так как строка — это множество символов, а каждый символ имеет свой код, бывает полезно иметь возможность преобразовать символ в его код, а по коду вычислить символ. Давайте исследуем, как работает это преобразование для python и для jython применительно к русским символам.
# сначала для jython, важно, чтобы исходный файл находился в кодировке windows-1251
import string
print ord('й'), ord('а'), ord('в')
print chr (ord('а') + 1)
# результат работы скрипта
1081 1072 1074
Б
Теперь то же, но для python — текст программы дополнился только указанием кодировки, в которой находится файл, для windows, я напоминаю, это cp866. Когда я работаю в linux и пользуюсь fedora core 4, то в ней консоль работает в кодировке utf8.
# -*- coding: cp866 -*-
import string
print ord('й'), ord('а'), ord('в')
print chr (ord('а') + 1)
# результат работы скрипта
169 160 162
б
# -*- coding: cp1251 -*-
import string
print ord('й'), ord('а'), ord('в')
print chr (ord('а') + 1)
# результат работы скрипта
233 224 226
б
 Попробуйте сами выполнить подобные вычисления для символов верхнего регистра. Теперь займемся анализом полученных данных. Результаты работы скрипта и в первом случае, и во втором корректные. И там, и там преобразование chr -> ord -> chr является корректным и однозначным. Отличия только в начальном значении, под которым в кодировочной таблице хранится символ "a-русское". Опять запустите программу Пуск -> Стандартные -> Таблица символов и рассмотрите ее подробнее. В нижней части окна приложения вы можете выбрать используемый набор символов. Заметьте, в какой позиции для набора "Unicode" находится символ "a-русское": это 430 в 16 c/с или же 1072 в десятичной системе счисления, что совпадает с результатами, полученными в jython. Если же выбрать набор символов "DOS: кириллица 2", то буква "а-русское" будет под номером A0 в 16 с/с или же 160 в 10 с/с, что совпадает с результатами для python. Когда jython прочитал в кодировке windows-1251 файл исходного текста скрипта, то он выполнил его преобразование в unicode. Последний пример: когда файл исходного кода был в кодировке windows-1251, буква "a-маленькое" имеет код 224, что соответствует набору символов "Windows: кириллица".
Попробуйте сами выполнить подобные вычисления для символов верхнего регистра. Теперь займемся анализом полученных данных. Результаты работы скрипта и в первом случае, и во втором корректные. И там, и там преобразование chr -> ord -> chr является корректным и однозначным. Отличия только в начальном значении, под которым в кодировочной таблице хранится символ "a-русское". Опять запустите программу Пуск -> Стандартные -> Таблица символов и рассмотрите ее подробнее. В нижней части окна приложения вы можете выбрать используемый набор символов. Заметьте, в какой позиции для набора "Unicode" находится символ "a-русское": это 430 в 16 c/с или же 1072 в десятичной системе счисления, что совпадает с результатами, полученными в jython. Если же выбрать набор символов "DOS: кириллица 2", то буква "а-русское" будет под номером A0 в 16 с/с или же 160 в 10 с/с, что совпадает с результатами для python. Когда jython прочитал в кодировке windows-1251 файл исходного текста скрипта, то он выполнил его преобразование в unicode. Последний пример: когда файл исходного кода был в кодировке windows-1251, буква "a-маленькое" имеет код 224, что соответствует набору символов "Windows: кириллица".
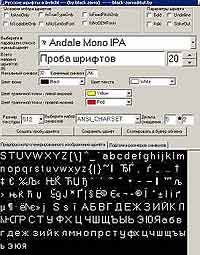
Теперь следующий шаг. Запустив мою версию программы irrfonttool, укажите диапазон генерируемых символов порядка 256 (так, чтобы стопроцентно захватить весь русский отрезок символов). Созданный файл bmp сохраните под любым именем. Необходимо найти на второй закладке программы позицию, с которой начинается русский набор символов. Это 192 для буквы "A-большое" и 224 — код для буквы "a-маленькое" — запомните это число. Теперь мы готовы к выводу надписей на русском в irrlicht. Если же вы допустили ошибку при создании файла шрифта, то при запуске следующего шрифта получите сообщение вида:
The amount of upper corner pixels and the lower corner pixels is not equal, font file may be corrupted.
 Пример исходного кода программы приводится ниже. Обратите внимание на существование функции adapt, получающей на вход два параметра. Это строка текста, содержащая в том числе русские буквы, а также число, задающее номер буквы A-большое в данном шрифте. Функция adapt организует цикл по всем символам строки, проверяет каждый символ на предмет того, что он попадает в интервал русских символов. Мы выше уже узнали, что "а- маленькое" имеет код 1072, а символ "А-большое" — 1040. Очевидно, что остальные символы русского алфавита будут иметь коды больше, чем 1040. В случае необходимости коды символов корректируются на разницу в кодах для jython и шрифта. Остальной код тривиален: подобно тому, как я заставлял двигаться Деда Мороза в части 5, здесь перемещаются строки текста. Для теста они содержат символы как нижнего, так и верхнего регистра. Кроме перемещения строк, выполняется плавное изменение цвета.
Пример исходного кода программы приводится ниже. Обратите внимание на существование функции adapt, получающей на вход два параметра. Это строка текста, содержащая в том числе русские буквы, а также число, задающее номер буквы A-большое в данном шрифте. Функция adapt организует цикл по всем символам строки, проверяет каждый символ на предмет того, что он попадает в интервал русских символов. Мы выше уже узнали, что "а- маленькое" имеет код 1072, а символ "А-большое" — 1040. Очевидно, что остальные символы русского алфавита будут иметь коды больше, чем 1040. В случае необходимости коды символов корректируются на разницу в кодах для jython и шрифта. Остальной код тривиален: подобно тому, как я заставлял двигаться Деда Мороза в части 5, здесь перемещаются строки текста. Для теста они содержат символы как нижнего, так и верхнего регистра. Кроме перемещения строк, выполняется плавное изменение цвета.
import java
import sys
import os
import net.sf.jirr
from net.sf.jirr import dimension2di
from net.sf.jirr import position2di
from net.sf.jirr import recti
from net.sf.jirr import SColor
# начало стандартное — загружаем библиотеку irrlicht
# создаем окно вывода
java.lang.System.loadLibrary ('irrlicht_wrap')
device = net.sf.jirr.Jirr.createDevice(
net.sf.jirr.E_DRIVER_TYPE.EDT_DIRECT3D9, dimension2di(800, 600), 32
)
device.setWindowCaption("1.3 программа — irrlicht и шрифты на русском — это круто");
driver = device.getVideoDriver()
gui = device.getGUIEnvironment()
# это код функции, выполняющей корректировку строки выводимого текста
def adapt (s, start_from_in_font):
rez = ""
for _c in s:
if ord(_c) >= 1040:
rez = rez + chr( ord(_c) — (1040 — start_from_in_font))
else:
rez = rez + _c
return rez
# теперь начинаем загружать шрифты
# первым я получаю ссылку на стандартный-встроенный шрифт,
# разумеется, русский текст, выводимый с его помощью, не работает
in_font = gui.getBuiltInFont()
# остальная загрузка тривиальна — нужно указать имя файла картинки со шрифтом
user_font_arial = gui.getFont("f:/kolya/py/py3d/resources/fonts/arial.bmp")
user_font_comic = gui.getFont("f:/kolya/py/py3d/resources/fonts/comic.bmp")
user_font_baltic = gui.getFont("f:/kolya/py/py3d/resources/fonts/baltic.bmp")
user_font_andale = gui.getFont("f:/kolya/py/py3d/resources/fonts/andale.bmp")
# засекаем время на начало главного цикла программы,
# это нам нужно для того, чтобы изменять координаты строк текста
# и цвет символов
initial_now_ms = device.getTimer().getTime()
while device.run():
time_now_ms = device.getTimer().getTime()
# значение текущего цвета — изменяется со скоростью 10 миллисекунд = 1 градация цвета
# операция остатка от деления % очень важна для того, чтобы значение цвета не вышло за
# допустимый диапазон 0-255
cur_color = ((time_now_ms — initial_now_ms) / 10) % 256
# по аналогии расчитывается смещение выводимого текста
cur_height = ((time_now_ms — initial_now_ms) / 100) % 50
driver.beginScene(1, 1, SColor(255,200,150,150))
gui.drawAll()
# при задании цвета первым параметром мы указываем значение альфа-компоненты,
# затем идут компоненты цвета красный, зеленый, синий
user_font_arial.draw(adapt("ARIAL: irrlicht + русские буквы = РАБОТАЕТ !", 192),
recti(10,10+cur_height,600,80),
SColor(cur_color,cur_color,cur_color,255))
user_font_comic.draw(adapt("COMIC: irrlicht + русские БУКВЫ = работает !", 192),
recti(10,60 — cur_height,600,180),
SColor(cur_color,cur_color,cur_color,255))
in_font.draw(adapt("INNER: irrlicht + РУсские буквы = работает !", 192),
recti(10,110+ cur_height,600,180),
SColor(cur_color,cur_color,cur_color,255))
user_font_baltic.draw(adapt("BALTIC: irrlicht + рУсские буквы = работает !", 192),
recti(10,160 — cur_height,600,180),
SColor(cur_color,cur_color,cur_color,255))
user_font_andale.draw(adapt("ANDALE: irrlicht + русскИЕ буквы = работает !", 192),
recti(10,210 + cur_height,600,180),
SColor(cur_color,cur_color,cur_color,255))
driver.endScene()
device.drop
black zorro, black-zorro@tut.by
Например, если вам нужна только латиница и цифры, то можно остановиться на 127. Если нужна кириллица, то цикл идет по 255. Дело в том, что исторически сложилось при создании кодировочной таблицы (кодировочная таблица — это правило отображения символов в их коды или номера) отводить для латиницы нижний диапазон до 127, а верхний диапазон отводить для национальных алфавитов. Эта схема применяется только для таблиц, в которых символ кодируется однобайтовым числом. Диапазон значений байта от 0 до 255. В случае Unicode, где для кодирования символа используется 2 байта, правила игры меняются. Для тренировки откройте Пуск -> Стандартные -> Таблица символов. Внизу таблицы для каждого выбранного символа отображается его код в шестнадцатеричной системе счисления. Используйте стандартный калькулятор windows в инженерном режиме для перевода чисел из шестнадцатеричной с/с в десятичную с/с. Первый символ таблицы — восклицательный знак — имеет код 33 в 10 с/с или же 21 в 16 с/с. Пока, не вдаваясь в подробности, запомните, что для irrlicht отсчет начинается именно с 32 символа (этот символ невидим). Далее очевидно, что для большинства шрифтов ширина символов различается так: буквы "i" меньше, чем буква "щ". Поэтому для разделения графических изображений символов необходимо использовать точки специального цвета. Например, пиксель с координатами 0,0 должен быть желтым, пиксель с координатами 1,0 — красным, пиксель с координатами 2,0 — черным. Здесь мы закодировали используемые цвета для маркировки границ символов. Если ваш шрифт использует красный или желтый цвет для отрисовки символов, то вы должны выбрать другие цвета.
К слову заметить, рисовать шрифт можно любым цветом — практического эффекта это не имеет. Фон, на котором рисуются символы, является черным и кодируется пикселем 2,0. Затем обозначенные цвета применяются по правилу: желтый цвет для левой верхней границы области символа, а красный — для правой нижней границы области символа. Воспользовавшись данным алгоритмом, вы можете рисовать свои шрифты в любом графическом редакторе. Для упрощения сего процесса я написал более продвинутую версию стандартной утилиты irrfonttool в пакете irrlicht (оригинальная утилита на основании выбранного шрифта и размера создает bmp-файл с нарисованными символами). К сожалению, разработчики irrfonttool, как и многие другие англоговорящие программисты, забыли о жителях 1/6 части суши, равно как и об говорящих на китайском, фарси и других языках. Я исправил данную ошибку, добавил несколько новых возможностей и — как же без этого — пару своих ошибок. Загрузить мою версию irrfonttool можно по адресу black-zorro.jino-net.ru/irrlicht/. Теперь следует разобраться с тем, как обрабатывать строки в python|jython. Для работы со строками вам необходимо подключить модуль string. Строки в python могут хранить не только печатные символы, но и специальные символы — например, табулятор, перевод каретки. Также строка может содержать двоичные данные. Хорошая новость для любителей c|c++: в python вы можете забыть об том, что строка — это массив символов с завершающим нулем терминатором. И, следовательно, мы говорим "нет" утомительной возне с контролем за выделением и освобождением памяти. Строка может быть заключена в одинарные или двойные кавычки по вашему выбору. Если у вас есть две строки, идущие друг за другом и разделенные только несколькими пробелами, то python склеит их в одну строку — например:
>>> print len("a" "b")
2
Если вам необходимо создать достаточно длинную строку, содержащую большое количество как одинарных, так и двойных кавычек и вместе с тем ряд символов перехода на новую строку, то рекомендуется использовать синтаксис с тремя одинарными или двойными кавычками — например, так:
>>> print """ hello
... bye, go, stop
... "and" other words on few lines
... """
hello
bye, go, stop
"and" other words on few lines
Для определения длины строки используйте функцию len — например, так:
>>> len("""
... barracuda
... and
... spring
... """)
22
Строки в python, как и во многих других высокоуровневых языках, можно объединять с помощью оператора "+".
>>> "abc" + "cde" """
... barracuda"""
'abccde\nbarracuda'
Для доступа к отдельным символам используйте оператор квадратные скобки с указанием индекса символа, подлежащего извлечению. Удобно, что можно задавать диапазоны символов — например, "начальный_символ : конечный_символ". Более того, каждая из этих двух частей может отсутствовать (разумеется, что не две одновременно). Не забывайте, что отсчет символов идет с нуля. Еще один прием — указание диапазонов с конца строки. Для этого используйте знак минус (как в последнем примере).
>>> "ferrum"[1]
'e'
>>> "ferrum"[3:]
'rum'
>>> "ferrum"[3:5]
'ru'
>>> "ferrum"[:4]
'ferr'
>>> "ferrum"[:-4]
'fe'
Плохая новость при работе со строками в том, что строки в python подобно строкам в java и в отличие от строк-массивов c|c++ не могут быть изменены. Так, если я попытаюсь присвоить символу строки новое значение, будет сгенерирована ошибка:
>>> bar = "ferrum"
>>> bar [5] = 'x'
Traceback (innermost last):
File "<console>", line 1, in ?
TypeError: can't assign to immutable object
Разумеется, переменной можно присвоить новое значение, вычисленное на базе старого. В примере я заменяю третью букву переменной bar на символ "g":
>>> bar = bar [:3] + 'g' + bar[4:]
>>> bar
'fergum'
Теперь рассмотрим уже знакомый нам оператор "%". В части 3 мы использовали его для получения остатка от деления двух чисел. Применительно к строкам "%" действует подобно функции printf из c|c++. Если вы не знакомы с c|c++, то запомните этот прием, очень полезный в ситуации, когда вам нужно вывести некоторое достаточно длинное сообщение пользователю, а в тексте этого сообщения должны присутствовать некоторые переменные, чередующиеся со строками. Можно пойти по классическому пути склеивания нескольких переменных. Но учитывайте, что в python не выполняется автоматического преобразования переменных к типу данных "строка". Это нужно делать явно, что может быть достаточно громоздко.
>>> money = 10
>>> print "money = " + money
Traceback (innermost last):
File "<console>", line 1, in ?
TypeError: unsupported operand type(s) for +: 'str' and 'int'
>>> print "money = " + str(money)
money = 10
>>> print "money = %d" % money
money = 10
Перед оператором "%" находится строка-шаблон. В ней с помощью символов подстановки вы помечаете места, куда будут помещены переменные, список которых размещен после символа "%". В моем примере была только одна переменная "money", если же переменных несколько, то их следует разделять с помощью запятой. Комбинация символов "%d" служит для вставки целой переменной, пара символов "%f" — для вставки вещественного числа, и пара символов "%s" — для вставки строки. Остальные комбинации символов подстановки вы можете найти в любом популярном учебнике по python. Для сравнения строк вы можете применять те же операторы, что и для сравнения целых или вещественных чисел. Следует помнить, что при сравнении символов регистр имеет значение.
>>> print "Python" <= "jython", "Jython" == "jython"
1 0
Для того, чтобы использовать следующие функции, необходимо подключить к скрипту модуль string — в противном случае python не узнает вызываемые функции.
import string
Для преобразования строки в нижний или верхний регистр используйте функцию lower и upper.
>>> print string.lower("BinGo"), string.upper("bAngO")
bingo BANGO
Если вам нужно найти в некоторой строке подстроку, то используйте функцию find, первым параметром которой вы указываете, где будет выполнен поиск, второй параметр указывает, что именно следует найти. Возможно указать третий и четвертый параметры, задающие начальную и конечную позицию подстроки, которая будет извлечена из первого параметра. В случае, если подстрока не будет найдена, функция find вернет значение "-1".
>>> posAv = string.find("gravity", "av")
>>> if posAv == -1:
... print "not found"
... else:
... print "found at ", posAv
...
found at 2
Следующая функция — replace. Ее назначение — заменить в некоторой строке (первый параметр) старое значение (второй параметр) на новое значение (третий параметр). Во втором примере я указал еще четвертый параметр — число, задающее количество первых совпадений, которое будет подвергнуто замене. Так, последняя буква "a" не была заменена на "c".
>>> string.replace("barracuda", "cud", "Gravity")
'barraGravitya'
>>> string.replace("abba", "a", "c", 1)
'cbba'
Интерес также представляют функции для выполнения преобразования строки в число. Раньше мы уже сталкивались с функциями int и float, теперь рассмотрим их подробнее. Функция int получает два параметра: первый — строковое представление числа, второй параметр — основание системы счисления. В третьем примере я пытался преобразовать строку "23" в 2 с/с. Это ошибка, т.к. в 2 с/с числа задаются только комбинацией 0 и 1.
>>> print int("23", 10)
23
>>> print int("23", 16)
35
>>> print int("23", 2)
Traceback (most recent call last):
File "<stdin>", line 1, in ?
ValueError: invalid literal for int(): 23
Функция float, преобразующая строку в вещественное число, необязательных параметров не имеет. Две функции, которые будут нужны нам для того, чтобы понять, как работает python|jython со строками, — это chr и ord. Так как строка — это множество символов, а каждый символ имеет свой код, бывает полезно иметь возможность преобразовать символ в его код, а по коду вычислить символ. Давайте исследуем, как работает это преобразование для python и для jython применительно к русским символам.
# сначала для jython, важно, чтобы исходный файл находился в кодировке windows-1251
import string
print ord('й'), ord('а'), ord('в')
print chr (ord('а') + 1)
# результат работы скрипта
1081 1072 1074
Б
Теперь то же, но для python — текст программы дополнился только указанием кодировки, в которой находится файл, для windows, я напоминаю, это cp866. Когда я работаю в linux и пользуюсь fedora core 4, то в ней консоль работает в кодировке utf8.
# -*- coding: cp866 -*-
import string
print ord('й'), ord('а'), ord('в')
print chr (ord('а') + 1)
# результат работы скрипта
169 160 162
б
# -*- coding: cp1251 -*-
import string
print ord('й'), ord('а'), ord('в')
print chr (ord('а') + 1)
# результат работы скрипта
233 224 226
б
Теперь следующий шаг. Запустив мою версию программы irrfonttool, укажите диапазон генерируемых символов порядка 256 (так, чтобы стопроцентно захватить весь русский отрезок символов). Созданный файл bmp сохраните под любым именем. Необходимо найти на второй закладке программы позицию, с которой начинается русский набор символов. Это 192 для буквы "A-большое" и 224 — код для буквы "a-маленькое" — запомните это число. Теперь мы готовы к выводу надписей на русском в irrlicht. Если же вы допустили ошибку при создании файла шрифта, то при запуске следующего шрифта получите сообщение вида:
The amount of upper corner pixels and the lower corner pixels is not equal, font file may be corrupted.
import java
import sys
import os
import net.sf.jirr
from net.sf.jirr import dimension2di
from net.sf.jirr import position2di
from net.sf.jirr import recti
from net.sf.jirr import SColor
# начало стандартное — загружаем библиотеку irrlicht
# создаем окно вывода
java.lang.System.loadLibrary ('irrlicht_wrap')
device = net.sf.jirr.Jirr.createDevice(
net.sf.jirr.E_DRIVER_TYPE.EDT_DIRECT3D9, dimension2di(800, 600), 32
)
device.setWindowCaption("1.3 программа — irrlicht и шрифты на русском — это круто");
driver = device.getVideoDriver()
gui = device.getGUIEnvironment()
# это код функции, выполняющей корректировку строки выводимого текста
def adapt (s, start_from_in_font):
rez = ""
for _c in s:
if ord(_c) >= 1040:
rez = rez + chr( ord(_c) — (1040 — start_from_in_font))
else:
rez = rez + _c
return rez
# теперь начинаем загружать шрифты
# первым я получаю ссылку на стандартный-встроенный шрифт,
# разумеется, русский текст, выводимый с его помощью, не работает
in_font = gui.getBuiltInFont()
# остальная загрузка тривиальна — нужно указать имя файла картинки со шрифтом
user_font_arial = gui.getFont("f:/kolya/py/py3d/resources/fonts/arial.bmp")
user_font_comic = gui.getFont("f:/kolya/py/py3d/resources/fonts/comic.bmp")
user_font_baltic = gui.getFont("f:/kolya/py/py3d/resources/fonts/baltic.bmp")
user_font_andale = gui.getFont("f:/kolya/py/py3d/resources/fonts/andale.bmp")
# засекаем время на начало главного цикла программы,
# это нам нужно для того, чтобы изменять координаты строк текста
# и цвет символов
initial_now_ms = device.getTimer().getTime()
while device.run():
time_now_ms = device.getTimer().getTime()
# значение текущего цвета — изменяется со скоростью 10 миллисекунд = 1 градация цвета
# операция остатка от деления % очень важна для того, чтобы значение цвета не вышло за
# допустимый диапазон 0-255
cur_color = ((time_now_ms — initial_now_ms) / 10) % 256
# по аналогии расчитывается смещение выводимого текста
cur_height = ((time_now_ms — initial_now_ms) / 100) % 50
driver.beginScene(1, 1, SColor(255,200,150,150))
gui.drawAll()
# при задании цвета первым параметром мы указываем значение альфа-компоненты,
# затем идут компоненты цвета красный, зеленый, синий
user_font_arial.draw(adapt("ARIAL: irrlicht + русские буквы = РАБОТАЕТ !", 192),
recti(10,10+cur_height,600,80),
SColor(cur_color,cur_color,cur_color,255))
user_font_comic.draw(adapt("COMIC: irrlicht + русские БУКВЫ = работает !", 192),
recti(10,60 — cur_height,600,180),
SColor(cur_color,cur_color,cur_color,255))
in_font.draw(adapt("INNER: irrlicht + РУсские буквы = работает !", 192),
recti(10,110+ cur_height,600,180),
SColor(cur_color,cur_color,cur_color,255))
user_font_baltic.draw(adapt("BALTIC: irrlicht + рУсские буквы = работает !", 192),
recti(10,160 — cur_height,600,180),
SColor(cur_color,cur_color,cur_color,255))
user_font_andale.draw(adapt("ANDALE: irrlicht + русскИЕ буквы = работает !", 192),
recti(10,210 + cur_height,600,180),
SColor(cur_color,cur_color,cur_color,255))
driver.endScene()
device.drop
black zorro, black-zorro@tut.by
Компьютерная газета. Статья была опубликована в номере 11 за 2007 год в рубрике программирование
