
ABBYY FineReader 8 новое качество распознавания
Какова будет первая ваша ассоциация на слово "процессор"? У одних наверняка посыплются названия Intel, Pentium, Celeron; другие сразу вспомнят про AMD, Athlon, Sempron… С "операционной системой" у большинства ассоциируется Windows, но немало и тех, кому сразу придет в голову слово "Linux". В мире железа и софта подобные ассоциации редко бывают однозначными. Но все-таки бывают: говорим "растровый графический редактор" — подразумеваем Adobe Photoshop; говорим текстовый редактор — подразумеваем MS Word; говорим "оптическая система распознавания символов" (или "ОСR'ка", или "распознавалка") и, конечно же, имеем в виду его — ABBYY FineReader.
Впрочем, косвенно сделанное чуть выше заявление о том, что у FineReader совсем уж нет конкурентов было бы, естественно, неправдой. Да, на мировом рынке систем оптического распознавания символов хватает игроков: тут вам и Adobe, и IRIS, и Cognitive Technologies, но ABBYY действительно можно по праву назвать одним из самых серьезных, если не самым. Шутка ли: почти 18 млн пользователей по всему миру включая крупнейшие мировые корпорации (Samsung, Lockheed Martin, Siemens Nixdorf), более 150 различных наград, 179 поддерживаемых языков (для 36 из них поддерживается также проверка орфографии!), а также широчайшее народное признание (по крайней мере, в странах бывшего СССР). Впрочем, это отнюдь не означает, что программа идеальна: в предыдущих версиях существовали проблемы распознавания документов сложной структуры с таблицами, а также материалов невысокого разрешения, да и работала программа зачастую не так быстро, как хотелось бы… Тем не менее, судя по списку усовершенствований и нововведений (см. таблицу), есть все основания полагать, что результат более чем двухлетней работы ABBYY еще на несколько шагов приблизил серию FineReader к идеалу. Так это или нет — проверим в процессе тестирования. Для его проведения компанией-разработчиком была предоставлена полнофункциональная копия ABBYY FineReader 8.0 Professional Edition (условимся в дальнейшем называть этот продукт в статье просто FineReader 8 — для краткости-"сестры"). Что ж, приступим?
|Нововведения и усовершенствования в ABBYY FineReader 8.0*
* Приводятся по материалам ABBYY
Встречаем по одежке
 Театр начинается с вешалки, танцы — от печки, а знакомство с любым программным продуктом (о'кей, "практически любым";)) — с процесса его установки. Инсталляция же, в свою очередь, начинается с распечатывания коробки. FineReader 8 поставляется в яркой, но не теряющей от этого солидности коробке достаточно крупного размера. Открываем коробку и понимаем, что ее толщину можно было бы безболезненно уменьшить вдвое, а то и втрое;). Внутри обнаруживаются:
Театр начинается с вешалки, танцы — от печки, а знакомство с любым программным продуктом (о'кей, "практически любым";)) — с процесса его установки. Инсталляция же, в свою очередь, начинается с распечатывания коробки. FineReader 8 поставляется в яркой, но не теряющей от этого солидности коробке достаточно крупного размера. Открываем коробку и понимаем, что ее толщину можно было бы безболезненно уменьшить вдвое, а то и втрое;). Внутри обнаруживаются:
. Установочный диск в довольно прочной и эффектной упаковке.
. Руководство пользователя (на русском языке).
. Лицензионный договор с конечным пользователем ПО (то есть с вами).
. Брошюра "быстрого знакомства" с ПО.
Вставляем диск в оптический привод, начинаем установку. За время ее можно попить чаю, пролистывая при этом брошюры "быстрого знакомства", лицензионное соглашение и руководство пользователя — на моей машине (Athlon XP 2500+ Barton/KT600/512 Mb RAM/DVD-ROM Sony DDU1612/80 Gb HDD WD) весь процесс занял около 10 минут. Из лицензионного соглашения узнаем, что FineReader 8 можно устанавливать максимум на два компьютера, а также один раз передать лицензию другому лицу (еще две установки, стало быть) — разумеется, с удалением программы со своего компьютера. Как это дело будет проверяться? Да очень просто: FineReader 8 после инсталляции для полнофункциональной работы необходима активация. Без прохождения этой процедуры работа с программой будет практически невозможна (не работает сохранение распознанных результатов и т.п.). Для активации необходимо сформированный на базе данных о конфигурации компьютера код Installation ID передать в ABBYY, и на основе полученной информации вам будет выслан (или продиктован;)) код активации. Наиболее удобным вариантом является активация через Интернет: нажимаете кнопку, и через десяток-другой секунд программа радостно рапортует вам о завершении процесса.
Можно отправить e-mail с кодом и получить активационный код от робота или, в крайнем случае, позвонить в ближайший офис компании/ее представителя и продиктовать Installation ID — взамен вам продиктуют ваш активационный код. ABBYY уверяет, что в процессе активации не передается никаких персональных данных, кроме тех, которые нужны для работы программы активации (например, активный язык в системе и собственно ее аппаратная конфигурация). Создатели программы утверждают, что число инсталляций на одном и том же компьютере не ограничено, однако в случае смены ОС или глобального апгрейда может потребоваться повторная активация. Не совсем ясно, однако, как будет контролироваться соблюдение условий лицензирования: ведь если число активаций не ограничено, то, по сути, можно установить не одну, а несколько копий программы. Конечно же, это будет прямым нарушением лицензионного договора. Полагаю, существуют определенные способы защиты от многократных инсталляций, однако их исследованием я не занимался: мне более чем достаточно двух установок (по одной на каждом из домашних компьютеров), да и пора уже избавляться от совкового менталитета "где бы что-нибудь стырить". После активации рекомендуется провести регистрацию продукта: по заполнению небольшой анкеты пользователя вы получите возможность получать бесплатную техническую поддержку, а также активационный код для ABBYY Screenshot Reader — небольшой полезной утилиты, входящей в состав FineReader 8. Если же отбросить активацию (по сравнению с процессом инсталляции она занимает ничтожное количество времени) с последующей регистрацией, установка проходит вполне стандартно: принимаем лицензионное соглашение, выбираем, какие компоненты и куда ставить, а затем любуемся на картинки и неспешно ползущий progress-bar. Кстати, FineReader 8 с минимальным набором языков "откушал" на моем винчестере чуть более 200 Мб.
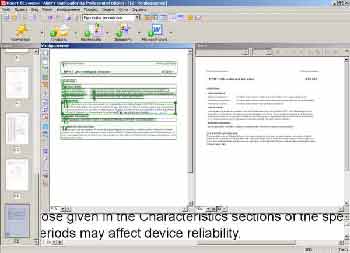 После установки запускаем программу и видим, что… что, кроме новых иконок, в интерфейсе практически нет изменений (на первый взгляд; в действительности многие вещи выстроены более четко и логично). Все та же "панель пакетов" слева, строка меню, стандартная панель инструментов и главная панель управления с крупными кнопками сверху. При работе свободное пространство в центре дополняется до боли знакомыми по предыдущим версиям окнами "изображение" (исходник), "текст" (результат), а также "крупным планом" попавшей под курсор части изображения. Очевидно, при создании интерфейса разработчики руководствовались разумным принципом "лучшее — враг хорошего". Интерфейс функционален, привычен (по сути, все та же 6-я версия) и очень удобен. Вот только новая иконка, красная стилизованная восьмерка, выглядит очень непривычно и чуть неуклюже. Впрочем, глупо делать выводы с наскоку, да еще по "внешней оболочке" программы: как показывает практика, основные изменения каждой новой версии FineReader заключаются в совершенствовании движка распознавания. Пора переходить к обзору функциональных свойств программы.
После установки запускаем программу и видим, что… что, кроме новых иконок, в интерфейсе практически нет изменений (на первый взгляд; в действительности многие вещи выстроены более четко и логично). Все та же "панель пакетов" слева, строка меню, стандартная панель инструментов и главная панель управления с крупными кнопками сверху. При работе свободное пространство в центре дополняется до боли знакомыми по предыдущим версиям окнами "изображение" (исходник), "текст" (результат), а также "крупным планом" попавшей под курсор части изображения. Очевидно, при создании интерфейса разработчики руководствовались разумным принципом "лучшее — враг хорошего". Интерфейс функционален, привычен (по сути, все та же 6-я версия) и очень удобен. Вот только новая иконка, красная стилизованная восьмерка, выглядит очень непривычно и чуть неуклюже. Впрочем, глупо делать выводы с наскоку, да еще по "внешней оболочке" программы: как показывает практика, основные изменения каждой новой версии FineReader заключаются в совершенствовании движка распознавания. Пора переходить к обзору функциональных свойств программы.
Провожаем по уму и деловым качествам
Прежде чем приступить к детальному (и не очень) рассмотрению основных реализованных в FineReader 8 возможностей, хотелось бы оговориться: я не претендую на истину в последней инстанции и не занимаюсь оцифровкой сотен и тысяч документов ежемесячно, оттого и функциональность программы буду анализировать "со своей колокольни" — т.е. с точки зрения пользователя, применяющего ПО для OCR от случая к случаю, в объемах примерно до сотни распознанных страниц в месяц. Последовательность процедуры распознавания не изменилась. На первом этапе мы добавляем в "пакет" готовые изображения, подлежащие распознаванию, либо получаем их со сканера. Затем нажимаем кнопку "2-распознать", и FineReader начинает работу: на первом этапе выполняется проверка правильности ориентирования изображения, уничтожение мелких дефектов, способных помешать процессу ("очистка" изображения), а также прочие подготовительные операции. На втором этапе происходит непосредственно распознавание текста. Ему предшествует так называемое "сегментирование", или разбивка изображения на текстовые блоки (в их границах будет распознаваться текст), "табличные" блоки и блоки изображений — последние будут вставлены в текст "как есть", безо всякого распознавания. Сегментирование может выполняться как автоматически (по умолчанию), так и вручную в документах специфической структуры. Можно добавлять и удалять блоки даже после распознавания. При этом, однако, данные в новых блоках останутся нераспознанными (необходимо будет запустить операцию распознавания еще раз), а распознанные данные, содержавшиеся в удаленных блоках, будут изъяты из результирующего текста. На мой взгляд, FineReader 8 выполняет разделение на блоки несколько лучше, чем предыдущая версия, корректно распределяя их для большинства документов несложной структуры. Если же вы планируете распознавать специфические материалы, настойчиво рекомендую расставить блоки распознавания вручную. FineReader 8 умеет производить быстрое распознавание документов хорошего качества: 300 dpi книжный разворот в этом режиме распознался у меня всего за 8 сек. (включая время на разворот страницы), а такой же материал в обычном ("тщательном") режиме FineReader обрабатывал 13 секунд. Если учесть, что число неуверенно распознанных символов в обоих случаях было одинаково мизерным, выгода от использования быстрого режима очевидна. Но лишь для документов высокого качества — при снижении разрешения (даже до 200 dpi) исходника количество ошибок распознавания в "быстром" режиме сильно возрастает, и его применение становится нецелесообразным. К слову, о разрешениях: FineReader 8 умеет искусственно увеличивать (интерполировать) разрешение низкокачественных оригиналов, однако слишком полагаться на эту возможность не стоит. В целом же можно отметить, что с распознаванием сравнительно высококачественных документов со стандартными шрифтами новая версия, как и прежде (или чуть-чуть лучше), справляется великолепно. А как же все остальные? FineReader 8 теперь "официально" поддерживает распознавание документов, полученных с цифровой камеры. Правда, необходимо отметить, что и ранние версии вполне успешно справлялись с этой задачей — однако в новой версии, по заявлениям ABBYY, были серьезно улучшены алгоритмы обработки "фотографированных" изображений. Разработчики рекомендуют использовать штатив, применять качественную фотокамеру (4 Мпикс с вариообъективом и возможностью ручной настройки на резкость) и по возможности избегать применения вспышки. Я нагло наплевал на эти требования руководства пользователя и для "экстрим-теста" снял исходное изображение (первую страничку буклета "быстрого знакомства") ночью со вспышкой (несколько, правда, подсветив исходник лампой) стареньким двухмегапиксельным Olympus C-220 Zoom, оставив по краям свободное пространство и несколько исказив кадр, держа камеру не строго над оригиналом. К моему удивлению, даже такой "уродец", с которым меня наверняка бы "послали в будущее" предыдущие версии, подхватился и был вполне успешно (конечно, не без ошибок — но их число не выходило за рамки) распознан! Так что подтверждаю: новый FineReader 8 может успешно обрабатывать даже фотоснимки невысокого качества, за что разработчикам низкий поклон.
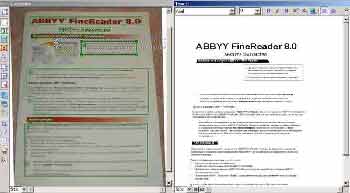 Даже документ с нарочно искаженной перспективой, снятый в темноте со вспышкой двухмегапиксельной камерой, новый FineReader распознал без особых проблем.
Даже документ с нарочно искаженной перспективой, снятый в темноте со вспышкой двухмегапиксельной камерой, новый FineReader распознал без особых проблем.
Впрочем, существуют и недостатки: стилизованные и "рукописные" шрифты, как и прежде, распознаются с большим скрипом; на больших и сложных таблицах автосегментирование нередко "запинается", а количество ошибок с понижением разрешения оригинала, пусть не так стремительно, как в предыдущих версиях, но все равно заметно растет даже в "тщательном" режиме.
После распознавания производится проверка неуверенно распознанных символов с возможностью подключения инструментов проверки правописания для многих языков, а также удаление или корректировка неправильно выделенных при автоматическом определении блоков. Затем осуществляется выбор программы, куда необходимо передать результат распознавания, и, наконец, весь документ с минимальными изменениями в форматировании (в зависимости от настроек формата экспорта) появляется в нужной нам программе. В MS Word'е, Excel'е, Adobe Acrobat [Reader]'е, браузере, MS PowerPoint'е… Процесс несложен даже при ручной настройке каждой из стадий; впрочем, если вы любите, чтобы вас "водили за руку", то по нажатию кнопки с "волшебной палочкой", Scan&Read, за вами будет ухаживать многоопытный и незанудный мастер. Кроме того, по нажатию на эту кнопку можно вызывать выбранный сценарий. По сути, сценарий — это стандартный макрос (прямым его аналогом будет, пожалуй, Photoshop'овский action), только несколько ограниченный в возможностях. Если в Photoshop и прочих программах макросы можно записывать, то сценарий FineReader'а необходимо составлять путем выбора из списка доступных вариантов. Это, в принципе, практически не ограничивает свободу в создании сценария, но делает процесс более громоздким. Впрочем, уверен, многим "профессиональным сканерам" (где под "сканером" подразумевается много и часто сканирующий/распознающий пользователь;)) такая возможность придется весьма и весьма по вкусу, а ради возможности "родной" автоматизации процесса они легко смирятся с любыми возможными недостатками, буде такие объявятся.
Особо стоит остановиться на возможности пакетной обработки PDF-файлов: открыл его FineReader'ом, он автоматически превратился в пакет из страниц (или избранных страниц), и вперед, на распознавание! Можно даже в быстром режиме — результат будет гарантированно хорошим. Единственная возможная проблема — не всегда корректная разбивка на блоки — придется подправлять ручками. Спросите, зачем это надо? Нередко случается, что беспроблемно "достать" текст из PDF-файла (особенно в случае, если этот текст русскоязычный) практически невозможно. Нужно идти на различные ухищрения, использовать специальные дополнительные утилиты и т.д. Несмотря на то, что в последних версиях Acrobat Reader'а инструмент Text Select работает гораздо эффективнее, зачастую необходимо получить PDF-документы в более "управляемом", что ли, варианте с сохранением форматирования. Этого позволяет достичь новая возможность FineReader 8 — теперь не нужно тупо выдирать по одной странице из PDF'ки и загонять их в пакет — достаточно просто выбрать файл и указать требуемый диапазон — остальное программа сделает за вас. Высокая скорость распознавания достигается за счет того, что часть текста (или весь) FineReader выбирает из текстового слоя PDF-файла при условии его соответствия изображенному на страницах тексту. Последним номером в обзоре новых возможностей хотелось бы остановиться на ABBYY ScreenShot Reader — программа позволяет делать скриншоты любой части экрана и распознавать текстовую информацию из них. Случается, что текст на веб-страницах защищен от копирования (что обходится, но не всегда удобными способами) или просто информация упрятана в картинку, а специально запускать FineReader для ее распознавания лень. В таком случае ScreenShot Reader вам однозначно поможет. Он не лишен недостатков (из слишком уж пестрых изображений текст будет вынуть весьма проблематично), но в целом выглядит прекрасным дополнением к "глыбе" — FineReader'у.
Итоги
Что сказать в заключение? ABBYY в очередной раз подтвердила свое лидерство в области распознавания документов. В обмен на два года ожидания пользователи получили улучшенные алгоритмы распознавания, особенно распознавания не слишком качественных документов. Подправленный интерфейс и новые возможности, заметно улучшающие удобство работы, однозначно стоят того, чтобы перейти на новую версию. Однако, по большому счету, если вы работаете с небольшими объемами качественных документов (300 dpi книг, например), новые возможности восьмой версии вряд ли покажутся вам достаточным резоном для ее приобретения.
[+] Возможность качественного распознавания даже "проблемных" печатных документов.
[+] Впечатляющая скорость работы в "быстром" режиме.
[+] Расширенные возможности работы с PDF, поддержка сценариев и формата LIT.
[-] Достаточно ощутимая стоимость ПО (более 100 у.е.).
[=] Наиболее совершенная и функциональная OCR-система для распознавания русского (и не только!) языка на данный момент.
Справка КГ: OCR
В переводе с английского OCR (Optical Character Recognition) означает "оптическое распознавание символов". А конкретнее набор технологий и методов, позволяющий переводить текст из бумажной формы в редактируемую на компьютере текстовую — наборы ASCII- или Unicode-символов, сохраняемые в текстовом, а не графическом формате. На сегодняшний день непосредственно оптическими используемые методы распознавания символов назвать сложно — оптика применяется лишь для оцифровки исходного изображения, превращения его в набор точек (пикселей). Более выигрышно смотрится название "цифровое распознавание символов". Первые упоминания о системах автоматического распознавания датируются 50-ми годами ХХ века. Современные системы OCR распознают печатные документы и заполненные от руки формы с высокой степенью точности, не является проблемой и распознавание вводимых в реальном времени от руки символов (PDA). Однако задача распознавания рукописных текстовых документов с приемлемым качеством все еще остается непосильной для массовых OCR-приложений. Наиболее популярным в России и СНГ OCR-комплексом для домашнего и делового применения является ПО FineReader российской компании ABBYY.
Справка КГ: ABBYY Software House
Российская компания ABBYY (до 1997 года — BIT Software) основана в 1989 г. студентом МФТИ Давидом Яном и на сегодняшний день является одним из ведущих мировых разработчиков программного обеспечения в области искусственного интеллекта — в частности, распознавания документов и обработки естественного языка. ABBYY объединяет более 500 сотрудников в 5 компаниях группы по всему миру (США, Россия, Германия, Великобритания, Украина) и головном московском офисе. ABBYY имеет разветвленную сеть дилеров и партнеров в 80 странах мира на всех континентах. Среди наиболее популярных продуктов компании выделяется семейство электронных словарей ABBYY Lingvo для ПК и КПК, а также система распознавания (OCR) ABBYY FineReader, позволяющая вводить в компьютер документы при помощи сканера и/или цифрового фотоаппарата. Многие российские и международные компании применяют продукты ABBYY: АВТОВАЗ, ВГТРК, ГАЗПРОМ, DHL INTERNATIONAL C.I.S., Lockheed Space and Missile Corporation (США), Procter&Gamble (Москва), Samsung Electronics (Южная Корея), Siemens Nixdorf (Германия) и другие — всего более 100.000 организаций в самых разных странах мира. По оценкам компании, ее продуктами в мире пользуются более 17,5 млн человек.
Николай "Nickky" Щетько, me@nickky.com
Впрочем, косвенно сделанное чуть выше заявление о том, что у FineReader совсем уж нет конкурентов было бы, естественно, неправдой. Да, на мировом рынке систем оптического распознавания символов хватает игроков: тут вам и Adobe, и IRIS, и Cognitive Technologies, но ABBYY действительно можно по праву назвать одним из самых серьезных, если не самым. Шутка ли: почти 18 млн пользователей по всему миру включая крупнейшие мировые корпорации (Samsung, Lockheed Martin, Siemens Nixdorf), более 150 различных наград, 179 поддерживаемых языков (для 36 из них поддерживается также проверка орфографии!), а также широчайшее народное признание (по крайней мере, в странах бывшего СССР). Впрочем, это отнюдь не означает, что программа идеальна: в предыдущих версиях существовали проблемы распознавания документов сложной структуры с таблицами, а также материалов невысокого разрешения, да и работала программа зачастую не так быстро, как хотелось бы… Тем не менее, судя по списку усовершенствований и нововведений (см. таблицу), есть все основания полагать, что результат более чем двухлетней работы ABBYY еще на несколько шагов приблизил серию FineReader к идеалу. Так это или нет — проверим в процессе тестирования. Для его проведения компанией-разработчиком была предоставлена полнофункциональная копия ABBYY FineReader 8.0 Professional Edition (условимся в дальнейшем называть этот продукт в статье просто FineReader 8 — для краткости-"сестры"). Что ж, приступим?
|Нововведения и усовершенствования в ABBYY FineReader 8.0*
| Кратко | Подробности |
| Улучшено качество распознавания документов с низким разрешением | Изображения низкого разрешения (факсы) распознаются на 30% лучше (по сравнению с FineReader 7, по данным внутренних исследований ABBYY) |
| Распознавание изображений, полученных с помощью цифровой фотокамеры | Новая адаптивная технология распознавания, появившаяся в системе FineReader 8, обеспечивает улучшенное качество обработки фотографий |
| Возможность защиты создаваемых PDF-файлов | При сохранении распознанного текста в формате PDF можно задать пароль для открытия документа, пароль для изменения прав доступа, а также выбрать уровень шифрования (40-битный или 128-битный на основе стандарта RC4, а также новейший 128-битный уровень, основанный на стандарте AES) |
| Добавление тегов в PDF-документы | FineReader 8 позволяет разметить структуру документа при сохранении в формате PDF для удобства просмотра документа на экранах разного размера |
| Менеджер сценариев | Благодаря этой новой функции появилась возможность объединять в один сценарий несколько операций, выполняемых последовательно, и запускать их на выполнение по одному нажатию кнопки. Предусмотрен ряд готовых сценариев и возможность создавать собственные |
| Распознавание гиперссылок | Теперь FineReader автоматически находит в тексте гиперссылки на веб-сайты либо адреса электронной почты и восстанавливает их в выходных документах |
| Режим быстрого распознавания | Режим быстрого распознавания, впервые реализованный в FineReader 8, позволяет ускорить обработку документов в 2-2,5 раза. Данный режим рекомендуется для распознавания документов с простым оформлением и высоким качеством печати, отсканированных с достаточным разрешением. В большинстве случаев быстрый режим обеспечивает высокое качество распознавания |
| Сохранение в формате Microsoft Reader e-book (LIT) | Распознанный FineReader 8 текст можно сохранить в формате LIT, используемом для создания электронных книг. Он позволяет получать документы, пригодные для просмотра на экранах КПК и других портативных устройств |
| Добавление свойств документа | FineReader 8 позволяет указать для распознанного текста дополнительные свойства: описание, автор, тема, а также ключевые слова. Сохранить текст можно в файле любого из этих форматов: PDF, DOC/RTF, XLS, HTML, Word XML или LIT |
| Расширенная языковая и словарная поддержка | Общее количество языков распознавания в новой версии FineReader достигло 179. Словарная поддержка и функция проверки правописания доступны для 36 языков. Словари юридических и медицинских терминов для немецкого и английского языков добавлены к остальным словарям, соответственно нет необходимости устанавливать специализированные языки распознавания при работе с текстами юридической и медицинской тематики |
| Открытие многостраничных PDF- и TIFF-файлов | Теперь, если вам нужен лишь фрагмент многостраничного документа, в FineReader 8 вы сможете открыть и распознать только выбранные страницы |
| ABBYY Screenshot Reader (для зарегистрированных пользователей Professional Edition и всех пользователей Corporate Edition) | Данная утилита позволяет быстро и легко распознать текст с любой области экрана компьютера |
| ABBYY Hot Folder & Scheduling (только в Corporate Edition) | По сравнению с предыдущей версией значительно расширились возможности автоматической проверки папок и обработки поступивших в них документов. Новое приложение-планировщик позволяет автоматически выполнять обработку документов в наиболее удобное время |
* Приводятся по материалам ABBYY
Встречаем по одежке
. Установочный диск в довольно прочной и эффектной упаковке.
. Руководство пользователя (на русском языке).
. Лицензионный договор с конечным пользователем ПО (то есть с вами).
. Брошюра "быстрого знакомства" с ПО.
Вставляем диск в оптический привод, начинаем установку. За время ее можно попить чаю, пролистывая при этом брошюры "быстрого знакомства", лицензионное соглашение и руководство пользователя — на моей машине (Athlon XP 2500+ Barton/KT600/512 Mb RAM/DVD-ROM Sony DDU1612/80 Gb HDD WD) весь процесс занял около 10 минут. Из лицензионного соглашения узнаем, что FineReader 8 можно устанавливать максимум на два компьютера, а также один раз передать лицензию другому лицу (еще две установки, стало быть) — разумеется, с удалением программы со своего компьютера. Как это дело будет проверяться? Да очень просто: FineReader 8 после инсталляции для полнофункциональной работы необходима активация. Без прохождения этой процедуры работа с программой будет практически невозможна (не работает сохранение распознанных результатов и т.п.). Для активации необходимо сформированный на базе данных о конфигурации компьютера код Installation ID передать в ABBYY, и на основе полученной информации вам будет выслан (или продиктован;)) код активации. Наиболее удобным вариантом является активация через Интернет: нажимаете кнопку, и через десяток-другой секунд программа радостно рапортует вам о завершении процесса.
Можно отправить e-mail с кодом и получить активационный код от робота или, в крайнем случае, позвонить в ближайший офис компании/ее представителя и продиктовать Installation ID — взамен вам продиктуют ваш активационный код. ABBYY уверяет, что в процессе активации не передается никаких персональных данных, кроме тех, которые нужны для работы программы активации (например, активный язык в системе и собственно ее аппаратная конфигурация). Создатели программы утверждают, что число инсталляций на одном и том же компьютере не ограничено, однако в случае смены ОС или глобального апгрейда может потребоваться повторная активация. Не совсем ясно, однако, как будет контролироваться соблюдение условий лицензирования: ведь если число активаций не ограничено, то, по сути, можно установить не одну, а несколько копий программы. Конечно же, это будет прямым нарушением лицензионного договора. Полагаю, существуют определенные способы защиты от многократных инсталляций, однако их исследованием я не занимался: мне более чем достаточно двух установок (по одной на каждом из домашних компьютеров), да и пора уже избавляться от совкового менталитета "где бы что-нибудь стырить". После активации рекомендуется провести регистрацию продукта: по заполнению небольшой анкеты пользователя вы получите возможность получать бесплатную техническую поддержку, а также активационный код для ABBYY Screenshot Reader — небольшой полезной утилиты, входящей в состав FineReader 8. Если же отбросить активацию (по сравнению с процессом инсталляции она занимает ничтожное количество времени) с последующей регистрацией, установка проходит вполне стандартно: принимаем лицензионное соглашение, выбираем, какие компоненты и куда ставить, а затем любуемся на картинки и неспешно ползущий progress-bar. Кстати, FineReader 8 с минимальным набором языков "откушал" на моем винчестере чуть более 200 Мб.
Провожаем по уму и деловым качествам
Прежде чем приступить к детальному (и не очень) рассмотрению основных реализованных в FineReader 8 возможностей, хотелось бы оговориться: я не претендую на истину в последней инстанции и не занимаюсь оцифровкой сотен и тысяч документов ежемесячно, оттого и функциональность программы буду анализировать "со своей колокольни" — т.е. с точки зрения пользователя, применяющего ПО для OCR от случая к случаю, в объемах примерно до сотни распознанных страниц в месяц. Последовательность процедуры распознавания не изменилась. На первом этапе мы добавляем в "пакет" готовые изображения, подлежащие распознаванию, либо получаем их со сканера. Затем нажимаем кнопку "2-распознать", и FineReader начинает работу: на первом этапе выполняется проверка правильности ориентирования изображения, уничтожение мелких дефектов, способных помешать процессу ("очистка" изображения), а также прочие подготовительные операции. На втором этапе происходит непосредственно распознавание текста. Ему предшествует так называемое "сегментирование", или разбивка изображения на текстовые блоки (в их границах будет распознаваться текст), "табличные" блоки и блоки изображений — последние будут вставлены в текст "как есть", безо всякого распознавания. Сегментирование может выполняться как автоматически (по умолчанию), так и вручную в документах специфической структуры. Можно добавлять и удалять блоки даже после распознавания. При этом, однако, данные в новых блоках останутся нераспознанными (необходимо будет запустить операцию распознавания еще раз), а распознанные данные, содержавшиеся в удаленных блоках, будут изъяты из результирующего текста. На мой взгляд, FineReader 8 выполняет разделение на блоки несколько лучше, чем предыдущая версия, корректно распределяя их для большинства документов несложной структуры. Если же вы планируете распознавать специфические материалы, настойчиво рекомендую расставить блоки распознавания вручную. FineReader 8 умеет производить быстрое распознавание документов хорошего качества: 300 dpi книжный разворот в этом режиме распознался у меня всего за 8 сек. (включая время на разворот страницы), а такой же материал в обычном ("тщательном") режиме FineReader обрабатывал 13 секунд. Если учесть, что число неуверенно распознанных символов в обоих случаях было одинаково мизерным, выгода от использования быстрого режима очевидна. Но лишь для документов высокого качества — при снижении разрешения (даже до 200 dpi) исходника количество ошибок распознавания в "быстром" режиме сильно возрастает, и его применение становится нецелесообразным. К слову, о разрешениях: FineReader 8 умеет искусственно увеличивать (интерполировать) разрешение низкокачественных оригиналов, однако слишком полагаться на эту возможность не стоит. В целом же можно отметить, что с распознаванием сравнительно высококачественных документов со стандартными шрифтами новая версия, как и прежде (или чуть-чуть лучше), справляется великолепно. А как же все остальные? FineReader 8 теперь "официально" поддерживает распознавание документов, полученных с цифровой камеры. Правда, необходимо отметить, что и ранние версии вполне успешно справлялись с этой задачей — однако в новой версии, по заявлениям ABBYY, были серьезно улучшены алгоритмы обработки "фотографированных" изображений. Разработчики рекомендуют использовать штатив, применять качественную фотокамеру (4 Мпикс с вариообъективом и возможностью ручной настройки на резкость) и по возможности избегать применения вспышки. Я нагло наплевал на эти требования руководства пользователя и для "экстрим-теста" снял исходное изображение (первую страничку буклета "быстрого знакомства") ночью со вспышкой (несколько, правда, подсветив исходник лампой) стареньким двухмегапиксельным Olympus C-220 Zoom, оставив по краям свободное пространство и несколько исказив кадр, держа камеру не строго над оригиналом. К моему удивлению, даже такой "уродец", с которым меня наверняка бы "послали в будущее" предыдущие версии, подхватился и был вполне успешно (конечно, не без ошибок — но их число не выходило за рамки) распознан! Так что подтверждаю: новый FineReader 8 может успешно обрабатывать даже фотоснимки невысокого качества, за что разработчикам низкий поклон.
Впрочем, существуют и недостатки: стилизованные и "рукописные" шрифты, как и прежде, распознаются с большим скрипом; на больших и сложных таблицах автосегментирование нередко "запинается", а количество ошибок с понижением разрешения оригинала, пусть не так стремительно, как в предыдущих версиях, но все равно заметно растет даже в "тщательном" режиме.
После распознавания производится проверка неуверенно распознанных символов с возможностью подключения инструментов проверки правописания для многих языков, а также удаление или корректировка неправильно выделенных при автоматическом определении блоков. Затем осуществляется выбор программы, куда необходимо передать результат распознавания, и, наконец, весь документ с минимальными изменениями в форматировании (в зависимости от настроек формата экспорта) появляется в нужной нам программе. В MS Word'е, Excel'е, Adobe Acrobat [Reader]'е, браузере, MS PowerPoint'е… Процесс несложен даже при ручной настройке каждой из стадий; впрочем, если вы любите, чтобы вас "водили за руку", то по нажатию кнопки с "волшебной палочкой", Scan&Read, за вами будет ухаживать многоопытный и незанудный мастер. Кроме того, по нажатию на эту кнопку можно вызывать выбранный сценарий. По сути, сценарий — это стандартный макрос (прямым его аналогом будет, пожалуй, Photoshop'овский action), только несколько ограниченный в возможностях. Если в Photoshop и прочих программах макросы можно записывать, то сценарий FineReader'а необходимо составлять путем выбора из списка доступных вариантов. Это, в принципе, практически не ограничивает свободу в создании сценария, но делает процесс более громоздким. Впрочем, уверен, многим "профессиональным сканерам" (где под "сканером" подразумевается много и часто сканирующий/распознающий пользователь;)) такая возможность придется весьма и весьма по вкусу, а ради возможности "родной" автоматизации процесса они легко смирятся с любыми возможными недостатками, буде такие объявятся.
Особо стоит остановиться на возможности пакетной обработки PDF-файлов: открыл его FineReader'ом, он автоматически превратился в пакет из страниц (или избранных страниц), и вперед, на распознавание! Можно даже в быстром режиме — результат будет гарантированно хорошим. Единственная возможная проблема — не всегда корректная разбивка на блоки — придется подправлять ручками. Спросите, зачем это надо? Нередко случается, что беспроблемно "достать" текст из PDF-файла (особенно в случае, если этот текст русскоязычный) практически невозможно. Нужно идти на различные ухищрения, использовать специальные дополнительные утилиты и т.д. Несмотря на то, что в последних версиях Acrobat Reader'а инструмент Text Select работает гораздо эффективнее, зачастую необходимо получить PDF-документы в более "управляемом", что ли, варианте с сохранением форматирования. Этого позволяет достичь новая возможность FineReader 8 — теперь не нужно тупо выдирать по одной странице из PDF'ки и загонять их в пакет — достаточно просто выбрать файл и указать требуемый диапазон — остальное программа сделает за вас. Высокая скорость распознавания достигается за счет того, что часть текста (или весь) FineReader выбирает из текстового слоя PDF-файла при условии его соответствия изображенному на страницах тексту. Последним номером в обзоре новых возможностей хотелось бы остановиться на ABBYY ScreenShot Reader — программа позволяет делать скриншоты любой части экрана и распознавать текстовую информацию из них. Случается, что текст на веб-страницах защищен от копирования (что обходится, но не всегда удобными способами) или просто информация упрятана в картинку, а специально запускать FineReader для ее распознавания лень. В таком случае ScreenShot Reader вам однозначно поможет. Он не лишен недостатков (из слишком уж пестрых изображений текст будет вынуть весьма проблематично), но в целом выглядит прекрасным дополнением к "глыбе" — FineReader'у.
Итоги
Что сказать в заключение? ABBYY в очередной раз подтвердила свое лидерство в области распознавания документов. В обмен на два года ожидания пользователи получили улучшенные алгоритмы распознавания, особенно распознавания не слишком качественных документов. Подправленный интерфейс и новые возможности, заметно улучшающие удобство работы, однозначно стоят того, чтобы перейти на новую версию. Однако, по большому счету, если вы работаете с небольшими объемами качественных документов (300 dpi книг, например), новые возможности восьмой версии вряд ли покажутся вам достаточным резоном для ее приобретения.
[+] Возможность качественного распознавания даже "проблемных" печатных документов.
[+] Впечатляющая скорость работы в "быстром" режиме.
[+] Расширенные возможности работы с PDF, поддержка сценариев и формата LIT.
[-] Достаточно ощутимая стоимость ПО (более 100 у.е.).
[=] Наиболее совершенная и функциональная OCR-система для распознавания русского (и не только!) языка на данный момент.
Справка КГ: OCR
В переводе с английского OCR (Optical Character Recognition) означает "оптическое распознавание символов". А конкретнее набор технологий и методов, позволяющий переводить текст из бумажной формы в редактируемую на компьютере текстовую — наборы ASCII- или Unicode-символов, сохраняемые в текстовом, а не графическом формате. На сегодняшний день непосредственно оптическими используемые методы распознавания символов назвать сложно — оптика применяется лишь для оцифровки исходного изображения, превращения его в набор точек (пикселей). Более выигрышно смотрится название "цифровое распознавание символов". Первые упоминания о системах автоматического распознавания датируются 50-ми годами ХХ века. Современные системы OCR распознают печатные документы и заполненные от руки формы с высокой степенью точности, не является проблемой и распознавание вводимых в реальном времени от руки символов (PDA). Однако задача распознавания рукописных текстовых документов с приемлемым качеством все еще остается непосильной для массовых OCR-приложений. Наиболее популярным в России и СНГ OCR-комплексом для домашнего и делового применения является ПО FineReader российской компании ABBYY.
Справка КГ: ABBYY Software House
Российская компания ABBYY (до 1997 года — BIT Software) основана в 1989 г. студентом МФТИ Давидом Яном и на сегодняшний день является одним из ведущих мировых разработчиков программного обеспечения в области искусственного интеллекта — в частности, распознавания документов и обработки естественного языка. ABBYY объединяет более 500 сотрудников в 5 компаниях группы по всему миру (США, Россия, Германия, Великобритания, Украина) и головном московском офисе. ABBYY имеет разветвленную сеть дилеров и партнеров в 80 странах мира на всех континентах. Среди наиболее популярных продуктов компании выделяется семейство электронных словарей ABBYY Lingvo для ПК и КПК, а также система распознавания (OCR) ABBYY FineReader, позволяющая вводить в компьютер документы при помощи сканера и/или цифрового фотоаппарата. Многие российские и международные компании применяют продукты ABBYY: АВТОВАЗ, ВГТРК, ГАЗПРОМ, DHL INTERNATIONAL C.I.S., Lockheed Space and Missile Corporation (США), Procter&Gamble (Москва), Samsung Electronics (Южная Корея), Siemens Nixdorf (Германия) и другие — всего более 100.000 организаций в самых разных странах мира. По оценкам компании, ее продуктами в мире пользуются более 17,5 млн человек.
Николай "Nickky" Щетько, me@nickky.com
Компьютерная газета. Статья была опубликована в номере 47 за 2005 год в рубрике soft :: текст
