
FineReader: просто, качественно, быстро
Откуда в этом тексте могут быть ошибки? Это же материал из FineReader'a.
(редактор журнала)
Ситуация: Вам вручают лист (10, 100, 200) с печатным текстом и просят поправить пару строк. Какая дискета? Давно все стерто/забыто/не было/сгорел компьютер/это вообще прислали из администрации и т.д. В силу недостаточной крепости нервной системы я так и не смог пройти экшн "Соло на клавиатуре" дальше сорокового уровня. А посему радостная перспектива скоростного набора отпадает сразу. А вот сканер завалялся/одолжился/нашелся у друга на работе. Дистрибутив OCR-программы тоже под рукой. Заставим технику вкалывать за нас!
 На рынке присутствует ряд программ оптического распознавания текстов (OCR). Врать не буду: не все пробовал. Прикипел к Abby FineReader еще с четвертой версии этого замечательного продукта. Над ним, родимым, и будем проводить эксперименты.
На рынке присутствует ряд программ оптического распознавания текстов (OCR). Врать не буду: не все пробовал. Прикипел к Abby FineReader еще с четвертой версии этого замечательного продукта. Над ним, родимым, и будем проводить эксперименты.
Пару слов о сканере. Оптимальным выбором на сегодняшний день являются модели с интерфейсом USB и внешним питанием. Установка драйверов сканера, как правило, труда не составляет, рекомендую, однако, не тащить во время инсталляции с фирменного CD ненужное ПО. Всяческие iPhotoPlus, Text Bridge, Panels, реагирующие, когда нужно и не нужно, на поднятие крышки сканера, нам совершенно ни к чему — достаточно стандартного TWAIN- 32-драйвера, который позволяет сканеру взаимодействовать и с Abby FineReader, и с прочим ПО.
К примеру, при установке своего Mustek BierPaw я выбрал тип инсталляции Custom и пометил галочкой только пункт TWAIN. Возможно, в вашем случае без фирменных примочек сканер попросту не заведется. Ну что ж, могу только посочувствовать и выразить надежду, что пытливый ум всегда найдет выход из подобной ситуации:). Следом за сканером — FineReader версии 7.0. Интересующимся советую прогуляться на сайт компании Abby. Надо сказать, OCR-программы — не единственный ее конек. Среди ПО компании — словарик Lingvo, софт для разработки различных опросных листов для дальнейшей автоматической обработки, довольно любопытные разработки для банков, предназначенные для ввода и распознавания платежных документов, и даже специальный скриптовый язык для интеграции функций оптического распознавания в ваши собственные программы. Вопрос лицензий по традиции пусть останется на совести читателя — добавлю лишь, что недавно в новостях упоминалась цена Home-пакета FineReader — $15. К тому же, программу, помимо ввода лицензионного номера, необходимо еще и активировать, что может доставить некоторые неудобства;).
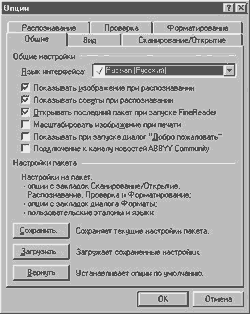 При первом запуске FineReader поприветствует нас предложением поучиться на примерах или приступить к работе вместе с мастером Scan&Read. Снимем птичку, отвечающую за появление этого окошка, и закроем его навсегда. Прежде чем приступить к работе, приведем в порядок свой "инструмент". Отправляемся в меню Сервис/Опции и открываем вкладку Сканирование/Открытие. Помечаем галочкой пункт Использовать интерфейс FineReader. Теперь мы можем работать со сканером в обход ненужных нам опций его TWAIN-интерфейса. Жмем кнопочку Настройки сканера и изучаем открывшееся окошко. Ориентацию страницы выбираем в зависимости от оригинала. Размер бумаги устанавливать не следует — при такой настройке сканер передаст в FineReader максимально отсканированную область. Пункты в правой части окна выбираем исходя из качества оригинала. Если сканируемый документ напечатан на лазерном или струйном принтере на белой бумаге при кегле (размере шрифта) в 10 пунктов, то значений по умолчанию — автоматического подбора яркости и разрешения в 300 dpi — более чем достаточно. Чем хуже оригинал (серая бумага, мелкий шрифт, неравномерная печать и т.д.), тем выше должно быть разрешение при сканировании и тем медленнее этот процесс будет осуществляться. В нижней трети окна следует уделить внимание пункту Пауза между страницами. Он отвечает за время простоя сканера при работе в режиме Сканировать много страниц. Подбирается пауза экспериментально.
При первом запуске FineReader поприветствует нас предложением поучиться на примерах или приступить к работе вместе с мастером Scan&Read. Снимем птичку, отвечающую за появление этого окошка, и закроем его навсегда. Прежде чем приступить к работе, приведем в порядок свой "инструмент". Отправляемся в меню Сервис/Опции и открываем вкладку Сканирование/Открытие. Помечаем галочкой пункт Использовать интерфейс FineReader. Теперь мы можем работать со сканером в обход ненужных нам опций его TWAIN-интерфейса. Жмем кнопочку Настройки сканера и изучаем открывшееся окошко. Ориентацию страницы выбираем в зависимости от оригинала. Размер бумаги устанавливать не следует — при такой настройке сканер передаст в FineReader максимально отсканированную область. Пункты в правой части окна выбираем исходя из качества оригинала. Если сканируемый документ напечатан на лазерном или струйном принтере на белой бумаге при кегле (размере шрифта) в 10 пунктов, то значений по умолчанию — автоматического подбора яркости и разрешения в 300 dpi — более чем достаточно. Чем хуже оригинал (серая бумага, мелкий шрифт, неравномерная печать и т.д.), тем выше должно быть разрешение при сканировании и тем медленнее этот процесс будет осуществляться. В нижней трети окна следует уделить внимание пункту Пауза между страницами. Он отвечает за время простоя сканера при работе в режиме Сканировать много страниц. Подбирается пауза экспериментально.
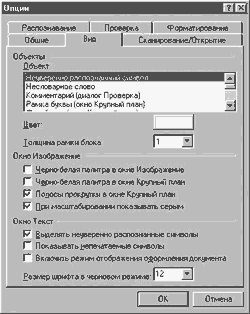
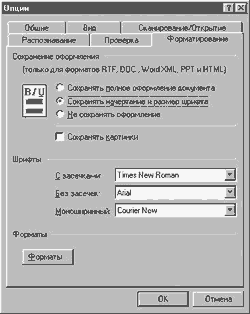
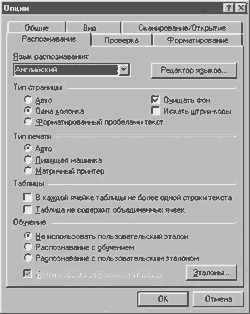
Для своего Mustek'а я поставил 2 секунды — вполне достаточно, чтобы извлечь из сканера отснятый и заложить новый лист. Прочие пункты особого внимания не требуют. Закрываем окошко настроек сканера и продолжаем путешествовать по вкладке Сканирование/Открытие. В разделе Обработка изображений помечаем галочками пункты Очистить от мусора, Определять ориентацию страницы и Приводить цветное/серое изображение к черно-белому. В группе Новая страница отмечаем Открывать изображения по мере сканирования. Вкладка Общие позволяет сменить язык интерфейса программы и активизировать 6 прочих несущественных опций. Главное ее достоинство заключается в том, что она позволяет загрузить сохраненные ранее настройки пакета либо вернуть все параметры программы к первоначальному состоянию. Во вкладку Вид изменения не вносим — настройки по умолчанию достаточно разумны. Вкладка Форматирование — отдельная тема. Маркетологи и рекламисты компании Abby постоянно подчеркивают достоинства FineReader в плане сохранения форматирования текста. А оно нам надо? Для копий существуют ксерокс и Photoshop. А уж с текстом-то мы и сами разберемся. Поэтому я обычно активизирую опцию Сохранять начертание и размер шрифта и снимаю галочку напротив пункта Сохранять картинки. Разделу Шрифты можно не уделять внимания. В нижней части вкладки находится кнопочка Форматы. Нажимать ее следует в том случае, если вы хотите до последнего проконтролировать экспорт готового текстового материала в *.txt, *.csv, *.dbf, *.xls, *.pdf и т.д. Не стоит уделять внимания и вкладке Проверка. Средства проверки правописания в Word и Exel просто замечательны, чтобы заниматься этим в FineReader'е. На вкладке Распознавание можно выбрать язык распознавания текста по умолчанию, отредактировать имеющиеся языковые шаблоны. В разделе Тип страницы ставим флажок напротив пункта Одна колонка (о "пользе" сохранения форматирования — выше:)), активизируем опцию Очищать фон. В группе Тип печати выставляем Авто (если, конечно, вы не собираетесь всю жизнь сканировать оригиналы, созданные на печатной машинке или матричнике). Разделам Таблицы и Обучение внимания не уделяем. Уф-ф! Закрываем меню Опции. Замечу, что вы можете в любой момент быстро изменить настройки программы из ее главного окна. Каждая кнопка, будь то Сканирование, Распознавание и т.д., имеет свой выпадающий список опций.
 Завершаем настройку. Сканируем какой-нибудь документ. Щелкаем правой кнопкой мыши на самом нижнем окне программы (Крупный план) и выбираем из выпавшего списка пункт Окна/Скрыть. Ни к чему нам это окошко — только отнимает драгоценное место. А монитор у меня всего лишь 17-дюймовый. Закладываем лист в сканер как можно ровнее, ориентируясь на метку (обычно стрелочка в уголке пластикового обрамления предметного стекла сканера). Жмем кнопку Сканировать и ждем результата. В докере справа появится пиктограмма отсканированного документа. Окно в центре отобразит страничку в заданном вами процентном соотношении. Поиграйте с масштабом так, чтобы изображение заняло максимум полезной площади, но осталось читаемым. Следующий этап — сегментация. Выбираем инструмент "т" и выделяем только текстовые блоки, которые нам нужно распознать.
Завершаем настройку. Сканируем какой-нибудь документ. Щелкаем правой кнопкой мыши на самом нижнем окне программы (Крупный план) и выбираем из выпавшего списка пункт Окна/Скрыть. Ни к чему нам это окошко — только отнимает драгоценное место. А монитор у меня всего лишь 17-дюймовый. Закладываем лист в сканер как можно ровнее, ориентируясь на метку (обычно стрелочка в уголке пластикового обрамления предметного стекла сканера). Жмем кнопку Сканировать и ждем результата. В докере справа появится пиктограмма отсканированного документа. Окно в центре отобразит страничку в заданном вами процентном соотношении. Поиграйте с масштабом так, чтобы изображение заняло максимум полезной площади, но осталось читаемым. Следующий этап — сегментация. Выбираем инструмент "т" и выделяем только текстовые блоки, которые нам нужно распознать.
Тем же инструментом выделяем таблицы. После чего щелкаем по блоку правой кнопкой мыши и из выпавшего списка выбираем его тип — Таблица. Повторяем последнее действие и выполняем Анализ структуры таблицы. Нужно это для того, чтобы объяснить программе, что распознанный текст не нужно представлять в виде ряда символов, разделенных табуляторами, а следует отобразить именно в виде таблицы. После анализа таблицу можно отредактировать при помощи инструментов, добавляющих или удаляющих линии. Блоки сегментации можно изменять в размерах, удалять, перенумеровывать и даже задавать для каждого свой язык распознавания. По завершении сегментации выбираем в выпадающем списке язык и нажимаем на кнопку Распознать. Скорость процесса зависит от процессора, количества ОЗУ и качества текста. В результате откроется окно Текст, в котором и появится наш документ. Изумрудным цветом выделяются неуверенно распознанные символы. Можно заняться проверкой орфографии прямо в FineReader.
 Я же сразу перехожу к сохранению. Выбираем формат сохранения результатов в выпадающем списке кнопки Передать. Для текста это Word, для таблиц — Exel и т.д. Документ откроется в программе, формат которой вы выбрали. Осталось взять в руки бумажный оригинал и сверить с тем, что мы видим на экране. Пользователь, работавший в FineReader, может вполне резонно поинтересоваться: а зачем, собственно, все делать вручную? Существует же мастер Scan&Read! Как показывает мой скромный опыт, при автоматической сегментации мастер включает в блоки для распознавания слишком много мусора (номера страниц, например).
Я же сразу перехожу к сохранению. Выбираем формат сохранения результатов в выпадающем списке кнопки Передать. Для текста это Word, для таблиц — Exel и т.д. Документ откроется в программе, формат которой вы выбрали. Осталось взять в руки бумажный оригинал и сверить с тем, что мы видим на экране. Пользователь, работавший в FineReader, может вполне резонно поинтересоваться: а зачем, собственно, все делать вручную? Существует же мастер Scan&Read! Как показывает мой скромный опыт, при автоматической сегментации мастер включает в блоки для распознавания слишком много мусора (номера страниц, например).
Работа с многостраничными документами
При работе с большим количеством материала стоит вспомнить ударника соцтруда Стаханова. Работать по-стахановски — значит, использовать бригадный метод. Применительно к распознаванию мы просто разобьем всю работу на маленькие подзадачи.
Этап 1. Подготовка материала
Разделяем по возможности страницы по одной, организуем рабочее место для их быстрой закладки/извлечения из сканера. Делаем несколько пробных проходов одного и того же листа в разных разрешениях и с различными значениями яркости. Задача — подобрать максимальную скорость сканирования при высоком качестве распознавания.
Этап 2. Сканирование
Жмем выпадающий список кнопки Сканировать и выбираем пункт Сканировать много страниц. Дальнейшая работа на некоторое время сведется к закладке и извлечению страниц из сканера. Если пауза между страницами, которую мы задали равной 2 секундам, вас не устраивает, измените ее в меню Опции выпадающего списка Сканировать. В процессе работы отснятые странички будут появляться перед вами в окне Просмотр. Рекомендую останавливать сканирование через каждые 50 страниц и сохранять результаты (Файл/Сохранить пакет). Отсканированные изображения, блоки сегментации, а также распознанный текст FineReader автоматически сохраняет в пакете — отдельной папке. После завершения сканирования не помешает просмотреть все страницы. Если имеются дефекты сканирования (темные пятна, неправильно положенный оригинал), лист нужно переснять, присвоить ему корректный номер (функция перенумерации страниц в пакете присутствует), а затем удалить ненужное.
 Этап 3. Сегментация
Этап 3. Сегментация
Процесс, который нельзя доверить автоматике. Вычистим номера страниц и прочий мусор, то есть сэкономим. Снова сохраняем пакет.
Этап 4. Распознавание
Жмем кнопку "Распознать все" и пьем кофе. По окончании процесса экспортируем результаты в выбранный формат.
Этап 5. Сверка
Самая тяжелая часть работы. Берем в руки оригинал и начинаем сверять с тем, что видим на мониторе.
Положительная сторона деления на этапы — скорость. Человек — не многозадачная операционная система. Переключение со сканирования на сегментацию и сверку отнимет время. Выполнение однообразных задач проще и эффективнее. Сканирование выполняется на машине со сканером. Для сегментации и распознавания сканер ни к чему — достаточно флэшки да FineReader у друга и дома: и друг не напрягается, и работа делается.
И несколько полезных советов
 Детально изучите возможности своего сканера. Заметив стандартные ошибки распознавания, не поленитесь записать макрос для Word. Можно попробовать создать пользовательский эталон в FineReader. Если вы не считаете себя докой в области русского языка и корректуры, если вас интересует качество — поручите сверку редактору (корректору). Профессионал выполнит такую работу и быстрее, и эффективнее.
Детально изучите возможности своего сканера. Заметив стандартные ошибки распознавания, не поленитесь записать макрос для Word. Можно попробовать создать пользовательский эталон в FineReader. Если вы не считаете себя докой в области русского языка и корректуры, если вас интересует качество — поручите сверку редактору (корректору). Профессионал выполнит такую работу и быстрее, и эффективнее.
RTFM, RTFM, RTFM… FineReader — русская программа и обладает подробной и понятной справкой.
Используйте старый добрый метод экспериментального тыка: он позволяет получить удовольствие:).
Виталий Закревский, mrtwister@tut.by
(редактор журнала)
Ситуация: Вам вручают лист (10, 100, 200) с печатным текстом и просят поправить пару строк. Какая дискета? Давно все стерто/забыто/не было/сгорел компьютер/это вообще прислали из администрации и т.д. В силу недостаточной крепости нервной системы я так и не смог пройти экшн "Соло на клавиатуре" дальше сорокового уровня. А посему радостная перспектива скоростного набора отпадает сразу. А вот сканер завалялся/одолжился/нашелся у друга на работе. Дистрибутив OCR-программы тоже под рукой. Заставим технику вкалывать за нас!
Пару слов о сканере. Оптимальным выбором на сегодняшний день являются модели с интерфейсом USB и внешним питанием. Установка драйверов сканера, как правило, труда не составляет, рекомендую, однако, не тащить во время инсталляции с фирменного CD ненужное ПО. Всяческие iPhotoPlus, Text Bridge, Panels, реагирующие, когда нужно и не нужно, на поднятие крышки сканера, нам совершенно ни к чему — достаточно стандартного TWAIN- 32-драйвера, который позволяет сканеру взаимодействовать и с Abby FineReader, и с прочим ПО.
К примеру, при установке своего Mustek BierPaw я выбрал тип инсталляции Custom и пометил галочкой только пункт TWAIN. Возможно, в вашем случае без фирменных примочек сканер попросту не заведется. Ну что ж, могу только посочувствовать и выразить надежду, что пытливый ум всегда найдет выход из подобной ситуации:). Следом за сканером — FineReader версии 7.0. Интересующимся советую прогуляться на сайт компании Abby. Надо сказать, OCR-программы — не единственный ее конек. Среди ПО компании — словарик Lingvo, софт для разработки различных опросных листов для дальнейшей автоматической обработки, довольно любопытные разработки для банков, предназначенные для ввода и распознавания платежных документов, и даже специальный скриптовый язык для интеграции функций оптического распознавания в ваши собственные программы. Вопрос лицензий по традиции пусть останется на совести читателя — добавлю лишь, что недавно в новостях упоминалась цена Home-пакета FineReader — $15. К тому же, программу, помимо ввода лицензионного номера, необходимо еще и активировать, что может доставить некоторые неудобства;).
Для своего Mustek'а я поставил 2 секунды — вполне достаточно, чтобы извлечь из сканера отснятый и заложить новый лист. Прочие пункты особого внимания не требуют. Закрываем окошко настроек сканера и продолжаем путешествовать по вкладке Сканирование/Открытие. В разделе Обработка изображений помечаем галочками пункты Очистить от мусора, Определять ориентацию страницы и Приводить цветное/серое изображение к черно-белому. В группе Новая страница отмечаем Открывать изображения по мере сканирования. Вкладка Общие позволяет сменить язык интерфейса программы и активизировать 6 прочих несущественных опций. Главное ее достоинство заключается в том, что она позволяет загрузить сохраненные ранее настройки пакета либо вернуть все параметры программы к первоначальному состоянию. Во вкладку Вид изменения не вносим — настройки по умолчанию достаточно разумны. Вкладка Форматирование — отдельная тема. Маркетологи и рекламисты компании Abby постоянно подчеркивают достоинства FineReader в плане сохранения форматирования текста. А оно нам надо? Для копий существуют ксерокс и Photoshop. А уж с текстом-то мы и сами разберемся. Поэтому я обычно активизирую опцию Сохранять начертание и размер шрифта и снимаю галочку напротив пункта Сохранять картинки. Разделу Шрифты можно не уделять внимания. В нижней части вкладки находится кнопочка Форматы. Нажимать ее следует в том случае, если вы хотите до последнего проконтролировать экспорт готового текстового материала в *.txt, *.csv, *.dbf, *.xls, *.pdf и т.д. Не стоит уделять внимания и вкладке Проверка. Средства проверки правописания в Word и Exel просто замечательны, чтобы заниматься этим в FineReader'е. На вкладке Распознавание можно выбрать язык распознавания текста по умолчанию, отредактировать имеющиеся языковые шаблоны. В разделе Тип страницы ставим флажок напротив пункта Одна колонка (о "пользе" сохранения форматирования — выше:)), активизируем опцию Очищать фон. В группе Тип печати выставляем Авто (если, конечно, вы не собираетесь всю жизнь сканировать оригиналы, созданные на печатной машинке или матричнике). Разделам Таблицы и Обучение внимания не уделяем. Уф-ф! Закрываем меню Опции. Замечу, что вы можете в любой момент быстро изменить настройки программы из ее главного окна. Каждая кнопка, будь то Сканирование, Распознавание и т.д., имеет свой выпадающий список опций.
Тем же инструментом выделяем таблицы. После чего щелкаем по блоку правой кнопкой мыши и из выпавшего списка выбираем его тип — Таблица. Повторяем последнее действие и выполняем Анализ структуры таблицы. Нужно это для того, чтобы объяснить программе, что распознанный текст не нужно представлять в виде ряда символов, разделенных табуляторами, а следует отобразить именно в виде таблицы. После анализа таблицу можно отредактировать при помощи инструментов, добавляющих или удаляющих линии. Блоки сегментации можно изменять в размерах, удалять, перенумеровывать и даже задавать для каждого свой язык распознавания. По завершении сегментации выбираем в выпадающем списке язык и нажимаем на кнопку Распознать. Скорость процесса зависит от процессора, количества ОЗУ и качества текста. В результате откроется окно Текст, в котором и появится наш документ. Изумрудным цветом выделяются неуверенно распознанные символы. Можно заняться проверкой орфографии прямо в FineReader.
Работа с многостраничными документами
При работе с большим количеством материала стоит вспомнить ударника соцтруда Стаханова. Работать по-стахановски — значит, использовать бригадный метод. Применительно к распознаванию мы просто разобьем всю работу на маленькие подзадачи.
Этап 1. Подготовка материала
Разделяем по возможности страницы по одной, организуем рабочее место для их быстрой закладки/извлечения из сканера. Делаем несколько пробных проходов одного и того же листа в разных разрешениях и с различными значениями яркости. Задача — подобрать максимальную скорость сканирования при высоком качестве распознавания.
Этап 2. Сканирование
Жмем выпадающий список кнопки Сканировать и выбираем пункт Сканировать много страниц. Дальнейшая работа на некоторое время сведется к закладке и извлечению страниц из сканера. Если пауза между страницами, которую мы задали равной 2 секундам, вас не устраивает, измените ее в меню Опции выпадающего списка Сканировать. В процессе работы отснятые странички будут появляться перед вами в окне Просмотр. Рекомендую останавливать сканирование через каждые 50 страниц и сохранять результаты (Файл/Сохранить пакет). Отсканированные изображения, блоки сегментации, а также распознанный текст FineReader автоматически сохраняет в пакете — отдельной папке. После завершения сканирования не помешает просмотреть все страницы. Если имеются дефекты сканирования (темные пятна, неправильно положенный оригинал), лист нужно переснять, присвоить ему корректный номер (функция перенумерации страниц в пакете присутствует), а затем удалить ненужное.
Процесс, который нельзя доверить автоматике. Вычистим номера страниц и прочий мусор, то есть сэкономим. Снова сохраняем пакет.
Этап 4. Распознавание
Жмем кнопку "Распознать все" и пьем кофе. По окончании процесса экспортируем результаты в выбранный формат.
Этап 5. Сверка
Самая тяжелая часть работы. Берем в руки оригинал и начинаем сверять с тем, что видим на мониторе.
Положительная сторона деления на этапы — скорость. Человек — не многозадачная операционная система. Переключение со сканирования на сегментацию и сверку отнимет время. Выполнение однообразных задач проще и эффективнее. Сканирование выполняется на машине со сканером. Для сегментации и распознавания сканер ни к чему — достаточно флэшки да FineReader у друга и дома: и друг не напрягается, и работа делается.
И несколько полезных советов
RTFM, RTFM, RTFM… FineReader — русская программа и обладает подробной и понятной справкой.
Используйте старый добрый метод экспериментального тыка: он позволяет получить удовольствие:).
Виталий Закревский, mrtwister@tut.by
Компьютерная газета. Статья была опубликована в номере 24 за 2005 год в рубрике soft :: текст
