
Создание парсеров в JAXP
Создание парсеров в JAXP
Одна из главных и наиболее важных особенностей J2EE — это встроенная поддержка XML, которая не зависит от производителей парсеров. В этой статье будут рассмотрены приемы создания и использования парсеров в Java API for XML (JAXP). JAXP представляет собой набор встроенных интерфейсов для создания и конфигурирования XML-парсеров, например, для J2EE-приложений. Подразумевается, что вы уже знакомы с интерфейсами SAX и DOM, а также с некоторыми базовыми понятиями XML (об этом шла речь в статьях "Java и XML").
Как уже упоминалось, JAXP имеет все необходимое для создания как SAX-парсеров, так и DOM-парсеров. JAXP располагается в пакете javax.xml.parsers, в состав которого входят четыре класса:
DocumentBuilder — это DOM-парсер, который создает объект класса org.w3c.dom.Document.
DocumentBuilderFactory — класс, который создает DOM-парсеры.
SAXParser — SAX-парсер, который привязывает обработчик SAX-событий к XML-документу, т.е. обрабатывает XML-документ согласно коду, определенному разработчиком.
SAXParserFactory — класс, который создает SAX-парсеры.
Чтобы обработать XML-документ с помощью парсеров JAXP, как для SAX, так и для DOM необходимо выполнить 4 действия:
1. Получить ссылку на объект одного из Factory-классов (DocumentBuilderFactory или SAXParserFactory).
2. Настроить необходимые параметры и свойства парсера.
3. Создать парсер.
4. Использовать полученный парсер для обработки XML-документа.
Если вы скачаете архив ttfeb2003.ear ( http://java.sun.com/jdc/EJTechTips/download/ttfeb2003.ear ), то там вы найдете сервлет ParseXMLServlet. С его помощью вы можете создавать, конфигурировать и применять к XML-документам как DOM-, так и SAX-парсеры. Внутри этого архива вы найдете также весь исходный код, некоторые части которого мы здесь рассмотрим. Поскольку SAX-парсеры несколько проще для понимания, нежели DOM-парсеры, с них и начнем.
Создание SAX-парсера
В интерфейсе SAX-парсера существует метод newInstance(), который возвращает ссылку на новый объект класса SAXParserFactory. Например:
SAXParserFactory spf = SAXParserFactory.newInstance();
Следующим шагом нам нужно сконфигурировать полученный объект. Существуют три метода, позволяющих настроить (включить/выключить) некоторые параметры парсера, который мы создаем:
void setNamespaceAware(boolean awareness) — если параметр awareness равен true, то будет создан парсер, который будет учитывать пространства имен, если же awareness равен false, тогда пространства имен учитываться не будут.
void setValidating(boolean validating) — если параметр validating равен true, то парсер, перед тем как приступить к обработке XML-документа, сначала проверит его на соответствие его своему DTD.
void setFeature(String name, boolean value) — этот метод позволяет менять некоторые параметры, определяемые производителями парсера, которым вы пользуетесь (т.е., если вы решили воспользоваться парсером от Oracle, JAXP это позволяет). Парсер должен поддерживать спецификацию SAX2.
Упомянутый ранее сервлет, который мы используем в качестве примера, предоставляет возможность перед созданием SAX-парсера включить или выключить пространства имен и проверку на соответствие DTD. Вот часть его кода, который позволяет в соответствии с заданными значениями параметров задать параметры создаваемому парсеру:
// req — это объект класса HttpServletRequest. Содержит всю информацию о запросе пользователя, вызвавшего этот сервлет, включая переданные ему параметры и их значения
boolean isNamespaceAware = req.getParameter ("JAXP_NamespaceAware") != null;
boolean isValidating = req.getParameter ("JAXP_Validating") != null;
spf.setNamespaceAware(isNamespaceAware);
spf.setValidating(isValidating);
После этого нам осталось связать файл XML-документа с потоком, передать этот поток парсеру, чтобы тот начал обработку документа. Например:
SAXParseHandler sph = new SAXParseHandler(out);
try {
SAXParser sp = spf.newSAXParser();
InputSource isrc = getInputSource(req);
sp.parse(isrc, sph);
}catch (ParserConfigurationException pce) {
throw new ServletException(pce);
} catch (SAXException sx) {
;
}
В приведенном выше коде для создания нового, сконфигурированного заранее парсера вызывается метод newSAXParser(). В случае, если по какой-либо причине парсер не может быть создан, будет выброшено исключение ParserConfigurationException. Метод parse() вновь созданного парсера в качестве первого параметра принимает экземпляр класса org.xml.sax.InputSource, который может быть сконструирован из любого объекта, производного от java.io.Reader. Вторым параметром метода parse() задается объект, унаследовавший и расширивший класс org.xml.sax.helpers.DefaultHandler. Именно этот объект и выражает всю функциональность приложения по обработке XML-документов. Как создавать подобные объекты, мы уже обсуждали в статье "Java и XML", посвященной SAX.
Создание DOM-парсера
При создании DOM-парсера мы будем выполнять все те же 4 шага, что и при создании SAX-парсера. Однако имена классов и методов будут, естественно, другими. Второе различие состоит в том, каким образом проходит обработка XML-документа. В случае с SAX мы имеем дело с созданием объекта класса org.xml.sax.helpers.DefaultHandler, в котором и определяем методы-события, которые будут вызываться при возникновении того или иного события (например, начало элемента, его конец, его содержание и пр.). Таким образом, весь процесс обработки сводится к созданию этого объекта и вызова метода parse(). В случае с DOM мы получаем объект DOM-дерева (org.xml.dom.Document) и уже после этого, пользуясь методами этого объекта, производим анализ этого дерева: извлекаем, добавляем и изменяем структуру и содержание.
Итак, для того чтобы создать DOM-парсер, вначале необходимо получить ссылку на объект класса DocumentBuilderFactory:
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
Все фактически как с SAX-парсером. Теперь мы будем конфигурировать полученный объект, придавая ему те свойства, которые нам необходимы. Следует сказать, что у DOM-парсеров гораздо больше свойств, чем у SAX-парсеров. Помимо тех, что мы упомянули ранее (setValidating и setNamespaceAware), DocumentBuilderFactory позволяет также определять следующие параметры:
void setCoalescing(boolean value) — если value равно true, то парсер будет объединять текстовые узлы и CDATA-секции в единые текстовые узлы в DOM-дереве. Иначе CDATA-секции будут вынесены в отдельные узлы.
void setExpandEntityReferences(boolean value) — если установлено (true), то ссылки на сущности будут заменены содержанием этих сущностей (самими сущностями). Если же нет, то эти узлы будут содержать все те же ссылки. Этот метод полезен, если вы не хотите себе головной боли по разыменованию ссылок вручную, если, конечно, они у вас есть.
void setIgnoringComments(boolean value) — если установлено, то все комментарии, содержащиеся в XML-документе, не появятся в результативном DOM-документе. Если нет, тогда DOM-документ будет содержать узлы с комментариями.
void setIgnoringElementContentWhitespace(boolean value) — если установлено, то пробельные символы (символы табуляции, пробелы и пр.), которые располагаются между элементами XML-документа, будут игнорироваться, и они не будут вынесены в узлы результативного DOM-дерева. Если нет, тогда будут созданы дополнительные текстовые узлы, содержащие эти символы.
В DOM нет метода setFeature(), как в SAX2, поэтому установка специальных переменных и параметров здесь не предусмотрена.
Последним этапом мы создаем парсер и используем его для обработки XML-документа:
SAXErrorHandler errorHandler = new SAXErrorHandler();
// создаем парсер
DocumentBuilder db = dbf.newDocumentBuilder();
db.setErrorHandler(errorHandler);
out.println("Successfully created document builder<br>");
// создаем объект InputSource
InputSource isrc = getInputSource(req);
// обрабатываем XML-документ и на выходе получаем объект org.xml.dom.Document
document = db.parse(isrc);
Чтобы создать объект DocumentBuilder, мы воспользовались, как видно из примера, методом newDocumentBuilder(). Этот созданный объект и есть DOM-парсер. Метод setErrorHandler() принимает в качестве параметра определенный разработчиком объект, созданный на основе интерфейса org.xml.sax.ErrorHandler (в нашем случае это экземпляр класса SAXErrorHandler). Парсер обращается к этому обработчику при возникновении каких-либо ошибок. Реализованный разработчиком объект для обработки ошибок может выводить сообщения о возникновении аварийных ситуаций, выбрасывать исключения и пр.
И в конце мы вызываем метод parse(). В DOM этот метод принимает только один параметр — объект класса InputSource. После чего он возвращает непосредственно документ DOM, который содержит всю необходимую нам информацию об XML-документе. Некоторые методы в DOM принимают объекты классов SAX (например, ErrorHandler и InputSource). Это вполне естественно, поскольку в заведении подобных же классов в реализации DOM нет никакой надобности.
Запуск примера
Подразумевается, что вы уже скачали архив с примером, а также что на вашем компьютере установлен пакет J2EE (http://java.sun.com). Теперь вы можете развернуть это приложение (ttfeb2003.ear) в своем сервере приложений, воспользовавшись программой deploytool:
$J2EE_HOME/deploytool -deploy ttfeb2003.ear localhost
Здесь localhost вам следует заменить именем хоста, которое вы определили при установке J2EE. Обычно по умолчанию используется именно localhost. После того, как deploytool развернет это приложение на вашем сервере, вы можете получить к нему доступ из браузера по следующему адресу: http://localhost:8000/ttfeb2003.
Если вы пользуетесь каким-нибудь другим J2EE-совместимым сервером приложений (например, BEA Weblogic, JBoss, IBM Websphere или другим), то вам следует воспользоваться той утилитой для развертывания приложений на сервер, которая предусмотрена сервером приложений, которым вы пользуетесь.
После того, как вы запустите это приложение, в своем браузере вы должны увидеть следующее:
1. Текстовое поле, в которое следует ввести имя файла XML-документа, который вы хотите обработать.
2. Кнопки-переключатели (radio buttons), с помощью которых вы можете выбрать тип парсера: SAX или DOM.
3. Кнопки-флажки (checkboxes), которыми вы можете включать или выключать те или иные параметры как для DOM, так и для SAX, а также параметры, специфичные только для DOM-парсеров.
Попробуйте поэкспериментировать с различными параметрами.
Предположим, что вы передаете файл XML-документа примерно следующего содержания:
<movies>
<movie>
<title>
Gone With the Wind
</title>
<actors>
<actorName> Vivien Leigh</actorName>
<actorName> Clark Gable</actorName>
</actors>
<description>
A movie classic set during the Civil War.
</description>
</movie>
</movies>
Вот часть результата, который вы получите, если выберете метод SAX и не будете включать (определять) никаких дополнительных параметров:
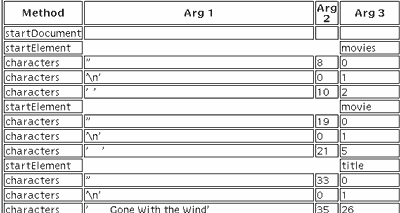
Если вы, к тому же, включите какой-нибудь из параметров (Namespace-Aware или Validating), то в дополнение к этому будет выдано следующее:

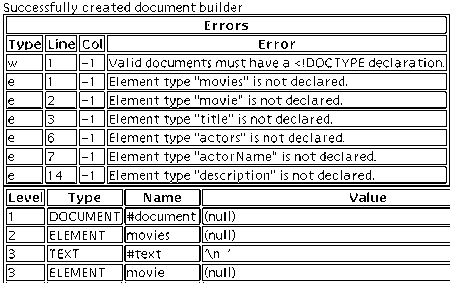
Следующее изображение показывает вывод результата в случае, если вы выбрали метод DOM и включили абсолютно все флажки (включая те, что только для DOM):
Вот и все, что касается создания парсеров в JAXP. За дополнительной информацией вы можете обращаться к 'JAXP Tutorial' по адресу: http://java.sun.com/webservices/docs/1.0/tutorial/doc/JAXPIntro.html .
По материалам Mark Johnson
Подготовил Алексей Литвинюк, http://www.litvinuke.hut.ru
Одна из главных и наиболее важных особенностей J2EE — это встроенная поддержка XML, которая не зависит от производителей парсеров. В этой статье будут рассмотрены приемы создания и использования парсеров в Java API for XML (JAXP). JAXP представляет собой набор встроенных интерфейсов для создания и конфигурирования XML-парсеров, например, для J2EE-приложений. Подразумевается, что вы уже знакомы с интерфейсами SAX и DOM, а также с некоторыми базовыми понятиями XML (об этом шла речь в статьях "Java и XML").
Как уже упоминалось, JAXP имеет все необходимое для создания как SAX-парсеров, так и DOM-парсеров. JAXP располагается в пакете javax.xml.parsers, в состав которого входят четыре класса:
DocumentBuilder — это DOM-парсер, который создает объект класса org.w3c.dom.Document.
DocumentBuilderFactory — класс, который создает DOM-парсеры.
SAXParser — SAX-парсер, который привязывает обработчик SAX-событий к XML-документу, т.е. обрабатывает XML-документ согласно коду, определенному разработчиком.
SAXParserFactory — класс, который создает SAX-парсеры.
Чтобы обработать XML-документ с помощью парсеров JAXP, как для SAX, так и для DOM необходимо выполнить 4 действия:
1. Получить ссылку на объект одного из Factory-классов (DocumentBuilderFactory или SAXParserFactory).
2. Настроить необходимые параметры и свойства парсера.
3. Создать парсер.
4. Использовать полученный парсер для обработки XML-документа.
Если вы скачаете архив ttfeb2003.ear ( http://java.sun.com/jdc/EJTechTips/download/ttfeb2003.ear ), то там вы найдете сервлет ParseXMLServlet. С его помощью вы можете создавать, конфигурировать и применять к XML-документам как DOM-, так и SAX-парсеры. Внутри этого архива вы найдете также весь исходный код, некоторые части которого мы здесь рассмотрим. Поскольку SAX-парсеры несколько проще для понимания, нежели DOM-парсеры, с них и начнем.
Создание SAX-парсера
В интерфейсе SAX-парсера существует метод newInstance(), который возвращает ссылку на новый объект класса SAXParserFactory. Например:
SAXParserFactory spf = SAXParserFactory.newInstance();
Следующим шагом нам нужно сконфигурировать полученный объект. Существуют три метода, позволяющих настроить (включить/выключить) некоторые параметры парсера, который мы создаем:
void setNamespaceAware(boolean awareness) — если параметр awareness равен true, то будет создан парсер, который будет учитывать пространства имен, если же awareness равен false, тогда пространства имен учитываться не будут.
void setValidating(boolean validating) — если параметр validating равен true, то парсер, перед тем как приступить к обработке XML-документа, сначала проверит его на соответствие его своему DTD.
void setFeature(String name, boolean value) — этот метод позволяет менять некоторые параметры, определяемые производителями парсера, которым вы пользуетесь (т.е., если вы решили воспользоваться парсером от Oracle, JAXP это позволяет). Парсер должен поддерживать спецификацию SAX2.
Упомянутый ранее сервлет, который мы используем в качестве примера, предоставляет возможность перед созданием SAX-парсера включить или выключить пространства имен и проверку на соответствие DTD. Вот часть его кода, который позволяет в соответствии с заданными значениями параметров задать параметры создаваемому парсеру:
// req — это объект класса HttpServletRequest. Содержит всю информацию о запросе пользователя, вызвавшего этот сервлет, включая переданные ему параметры и их значения
boolean isNamespaceAware = req.getParameter ("JAXP_NamespaceAware") != null;
boolean isValidating = req.getParameter ("JAXP_Validating") != null;
spf.setNamespaceAware(isNamespaceAware);
spf.setValidating(isValidating);
После этого нам осталось связать файл XML-документа с потоком, передать этот поток парсеру, чтобы тот начал обработку документа. Например:
SAXParseHandler sph = new SAXParseHandler(out);
try {
SAXParser sp = spf.newSAXParser();
InputSource isrc = getInputSource(req);
sp.parse(isrc, sph);
}catch (ParserConfigurationException pce) {
throw new ServletException(pce);
} catch (SAXException sx) {
;
}
В приведенном выше коде для создания нового, сконфигурированного заранее парсера вызывается метод newSAXParser(). В случае, если по какой-либо причине парсер не может быть создан, будет выброшено исключение ParserConfigurationException. Метод parse() вновь созданного парсера в качестве первого параметра принимает экземпляр класса org.xml.sax.InputSource, который может быть сконструирован из любого объекта, производного от java.io.Reader. Вторым параметром метода parse() задается объект, унаследовавший и расширивший класс org.xml.sax.helpers.DefaultHandler. Именно этот объект и выражает всю функциональность приложения по обработке XML-документов. Как создавать подобные объекты, мы уже обсуждали в статье "Java и XML", посвященной SAX.
Создание DOM-парсера
При создании DOM-парсера мы будем выполнять все те же 4 шага, что и при создании SAX-парсера. Однако имена классов и методов будут, естественно, другими. Второе различие состоит в том, каким образом проходит обработка XML-документа. В случае с SAX мы имеем дело с созданием объекта класса org.xml.sax.helpers.DefaultHandler, в котором и определяем методы-события, которые будут вызываться при возникновении того или иного события (например, начало элемента, его конец, его содержание и пр.). Таким образом, весь процесс обработки сводится к созданию этого объекта и вызова метода parse(). В случае с DOM мы получаем объект DOM-дерева (org.xml.dom.Document) и уже после этого, пользуясь методами этого объекта, производим анализ этого дерева: извлекаем, добавляем и изменяем структуру и содержание.
Итак, для того чтобы создать DOM-парсер, вначале необходимо получить ссылку на объект класса DocumentBuilderFactory:
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
Все фактически как с SAX-парсером. Теперь мы будем конфигурировать полученный объект, придавая ему те свойства, которые нам необходимы. Следует сказать, что у DOM-парсеров гораздо больше свойств, чем у SAX-парсеров. Помимо тех, что мы упомянули ранее (setValidating и setNamespaceAware), DocumentBuilderFactory позволяет также определять следующие параметры:
void setCoalescing(boolean value) — если value равно true, то парсер будет объединять текстовые узлы и CDATA-секции в единые текстовые узлы в DOM-дереве. Иначе CDATA-секции будут вынесены в отдельные узлы.
void setExpandEntityReferences(boolean value) — если установлено (true), то ссылки на сущности будут заменены содержанием этих сущностей (самими сущностями). Если же нет, то эти узлы будут содержать все те же ссылки. Этот метод полезен, если вы не хотите себе головной боли по разыменованию ссылок вручную, если, конечно, они у вас есть.
void setIgnoringComments(boolean value) — если установлено, то все комментарии, содержащиеся в XML-документе, не появятся в результативном DOM-документе. Если нет, тогда DOM-документ будет содержать узлы с комментариями.
void setIgnoringElementContentWhitespace(boolean value) — если установлено, то пробельные символы (символы табуляции, пробелы и пр.), которые располагаются между элементами XML-документа, будут игнорироваться, и они не будут вынесены в узлы результативного DOM-дерева. Если нет, тогда будут созданы дополнительные текстовые узлы, содержащие эти символы.
В DOM нет метода setFeature(), как в SAX2, поэтому установка специальных переменных и параметров здесь не предусмотрена.
Последним этапом мы создаем парсер и используем его для обработки XML-документа:
SAXErrorHandler errorHandler = new SAXErrorHandler();
// создаем парсер
DocumentBuilder db = dbf.newDocumentBuilder();
db.setErrorHandler(errorHandler);
out.println("Successfully created document builder<br>");
// создаем объект InputSource
InputSource isrc = getInputSource(req);
// обрабатываем XML-документ и на выходе получаем объект org.xml.dom.Document
document = db.parse(isrc);
Чтобы создать объект DocumentBuilder, мы воспользовались, как видно из примера, методом newDocumentBuilder(). Этот созданный объект и есть DOM-парсер. Метод setErrorHandler() принимает в качестве параметра определенный разработчиком объект, созданный на основе интерфейса org.xml.sax.ErrorHandler (в нашем случае это экземпляр класса SAXErrorHandler). Парсер обращается к этому обработчику при возникновении каких-либо ошибок. Реализованный разработчиком объект для обработки ошибок может выводить сообщения о возникновении аварийных ситуаций, выбрасывать исключения и пр.
И в конце мы вызываем метод parse(). В DOM этот метод принимает только один параметр — объект класса InputSource. После чего он возвращает непосредственно документ DOM, который содержит всю необходимую нам информацию об XML-документе. Некоторые методы в DOM принимают объекты классов SAX (например, ErrorHandler и InputSource). Это вполне естественно, поскольку в заведении подобных же классов в реализации DOM нет никакой надобности.
Запуск примера
Подразумевается, что вы уже скачали архив с примером, а также что на вашем компьютере установлен пакет J2EE (http://java.sun.com). Теперь вы можете развернуть это приложение (ttfeb2003.ear) в своем сервере приложений, воспользовавшись программой deploytool:
$J2EE_HOME/deploytool -deploy ttfeb2003.ear localhost
Здесь localhost вам следует заменить именем хоста, которое вы определили при установке J2EE. Обычно по умолчанию используется именно localhost. После того, как deploytool развернет это приложение на вашем сервере, вы можете получить к нему доступ из браузера по следующему адресу: http://localhost:8000/ttfeb2003.
Если вы пользуетесь каким-нибудь другим J2EE-совместимым сервером приложений (например, BEA Weblogic, JBoss, IBM Websphere или другим), то вам следует воспользоваться той утилитой для развертывания приложений на сервер, которая предусмотрена сервером приложений, которым вы пользуетесь.
После того, как вы запустите это приложение, в своем браузере вы должны увидеть следующее:
1. Текстовое поле, в которое следует ввести имя файла XML-документа, который вы хотите обработать.
2. Кнопки-переключатели (radio buttons), с помощью которых вы можете выбрать тип парсера: SAX или DOM.
3. Кнопки-флажки (checkboxes), которыми вы можете включать или выключать те или иные параметры как для DOM, так и для SAX, а также параметры, специфичные только для DOM-парсеров.
Попробуйте поэкспериментировать с различными параметрами.
Предположим, что вы передаете файл XML-документа примерно следующего содержания:
<movies>
<movie>
<title>
Gone With the Wind
</title>
<actors>
<actorName> Vivien Leigh</actorName>
<actorName> Clark Gable</actorName>
</actors>
<description>
A movie classic set during the Civil War.
</description>
</movie>
</movies>
Вот часть результата, который вы получите, если выберете метод SAX и не будете включать (определять) никаких дополнительных параметров:
Если вы, к тому же, включите какой-нибудь из параметров (Namespace-Aware или Validating), то в дополнение к этому будет выдано следующее:
Следующее изображение показывает вывод результата в случае, если вы выбрали метод DOM и включили абсолютно все флажки (включая те, что только для DOM):
Вот и все, что касается создания парсеров в JAXP. За дополнительной информацией вы можете обращаться к 'JAXP Tutorial' по адресу: http://java.sun.com/webservices/docs/1.0/tutorial/doc/JAXPIntro.html .
По материалам Mark Johnson
Подготовил Алексей Литвинюк, http://www.litvinuke.hut.ru
Компьютерная газета. Статья была опубликована в номере 08 за 2003 год в рубрике программирование :: разное
