
Неизвестный RAID
Неизвестный RAID
Тема данной статьи на первый взгляд представляется сугубо специальной и малоизвестна даже в среде "крутых" профессионалов. Везде, где вы зададите вопрос о RAID, кроме разве что центральных филиалов крупных банков с их мощными серверами и разветвленными сетями, в лучшем случае услышите, что это — некая технология, используемая в серверах с целью защиты данных. В худшем — ответом вам будет просто недоуменное пожатие плечами.
И в самом деле, вопрос локальный — вот пусть специалисты по серверам им и занимаются. С точки зрения пользователя, пусть даже "завязанного" на локальную сеть, трудно придумать что-нибудь скучнее сервера. Стоит себе серверок и пусть стоит, дешевенький такой, за полторы штуки баксов, минской сборки. Никаких интересных приложений на нем не крутится. Правда, если сеть в порядке (а это, вообще говоря, тема отдельная и весьма интересная, но речь пока не о ней), то данные движутся так, как нужно, и попадают туда, куда нужно. Словом, полная идиллия, которая тянется до тех пор, пока в дисковой подсистеме сервера не наступает серьезный сбой либо она полностью не выходит из строя.
Здесь-то обычно и выясняется, что защита ваших данных от возможной потери — вопрос, увы, далеко не праздный и имеет к вам самое прямое и непосредственное отношение. Конечно, утрату дистрибутива Microsoft Windows 95, зачем-то лежавшего на аварийном диске, сжав зубы, пережить можно. Но если вместе с ним "ушли" данные, представляющие собой результат годовой работы научно-исследовательской лаборатории или отдела, то воспринять это как пустяковое происшествие не поможет никакая гештальт-терапия.
То, что ущерб от потери информации сегодня может достигать величин астрономических, общеизвестно. Все это знают, хорошо понимают и... успешно игнорируют на практике. Соображения "экономии" чаще всего берут верх, а прозрение, если и наступает, то только задним числом. Между тем, еще у прадедов для таких случаев была поговорка: "Мы не настолько богаты, чтобы позволить себе покупать дешевые вещи".
Может быть, картина в целом и не столь мрачна. Если говорить о дисковой подсистеме (о чем, собственно, и пойдет сегодня разговор), то здесь есть определенные сдвиги. Пусть медленно, с трудом, однако понимание того факта, что винчестер с IDE-интерфейсом и сервер — вещи несовместные, пробивает себе дорогу. Наряду с осознанием того, что разница в цене между сервером и рабочей станцией при одинаковых вроде бы емкостях диска, размерах ОЗУ и тактовой частоте процессора — не просто прихоть алчных фирм-продавцов этой техники. Избыточность и высочайшая надежность — вот неотъемлемые характеристики сервера (PC, "на страх врагам" переделанные в сервер, естественно, не в счет). О том, за счет чего достигается сегодня надежная и безотказная работа дисковой подсистемы, и пойдет речь далее.
Безусловно, жесткие диски, используемые сегодня в персональных компьютерах, рабочих станциях и серверах, значительно более устойчивы, чем их предшественники 10-летней давности. Основным критерием, характеризующим надежность накопителя, является среднее время между неисправностями, или MTBF (mean time between failures). В отношении сохранности данных используется другой критерий, известный как среднее время до потери данных, или MTDL (mean time to data loss). У высококачественных дисков величина MTDL составляет от 100,000 часов работы (11.4 года) и более.
Казалось бы, вопросы решены. Но в действительности все не так просто. Наряду с увеличением степени надежности дисков растет и их емкость, причем куда более быстрыми темпами. Тем самым постоянно повышающиеся требования пользователей к безотказной работе дисков опережают увеличение надежности, происходящее в действительности. Это означает, что уровень безопасности данных, который можно считать приемлемым для установленного в персоналке винчестера емкостью 540 мегабайт, совершенно неприемлем для 9-гигабайтного SCSI-накопителя.
Можно привести еще и такую предельно наглядную аналогию. Скажем, выход из строя одной из подсистем тепловой электростанции представляет собой достаточно неприятное происшествие, способное доставить персоналу этой станции немало хлопот. Однако подобное происшествие на АЭС может быть источником угрозы уже планетарного масштаба, а последствия аварии, как мы все, к несчастью, уже знаем, придется ликвидировать долгие годы. Ясно поэтому, что уровень надежности, который должен быть заложен при проектировании этих двух типов станций, совершенно не сопоставим по масштабам.
В отношении надежности накопителей, о которой говорилось выше, существует еще одна немаловажная проблема. А именно — объем жестких дисков, доступных на рынке, хронически не успевает за экспоненциальным ростом объемов информации. Кроме того, в то время как стоимость популярных накопителей небольшой емкости достаточно быстро снижается, стоимость высокоемких и быстрых жестких дисков остается весьма высокой. Отсюда вытекает, в частности, тот факт, что пользователю с точки зрения экономии может быть выгоднее оснащать свою систему вместо одного высокоемкого жесткого диска несколькими дисками меньшего объема. Однако устойчивость к ошибкам для дисковой подсистемы в целом при этом уменьшается из-за роста числа потенциальных точек неисправности. Примем величину MTBF для высококачественного диска за 100,000 часов непрерывной работы, как об этом говорилось выше. Для системы из двадцати таких дисков MTBF составит около 4,000 часов, то есть не превышает 6 месяцев!
А потому кажется парадоксальным, что именно размещение данных на разных дисках способно обеспечить чрезвычайно высокую производительность и надежность. Эта фундаментальная идея лежит в основе RAID-конфигураций. Понятие RAID (аббревиатура от Redundant Array of Inexpensive Disks — избыточный массив недорогих дисков) было предложено в 1987 году Дэвидом Паттерсоном, Гартом Гибсоном и Рэнди Кацем из Калифорнийского университета в Беркли в статье "Выбор избыточного массива недорогих дисков".
Паттерсон и его коллеги предложили пять методов использования недорогих устройств в параллельном массиве, который сконфигурирован так, чтобы обеспечивать даже более высокую надежность, чем у одного диска большой емкости. Каждый из этих методов основан на избыточности данных, при которой в состав дисковой подсистемы включен один или несколько жестких дисков сверх количества, необходимого для создания заданной емкости. Этот подход позволяет восстановить данные при неисправности диска, а эффективный уровень ошибок для подобной системы будет очень низким. При этом данные могут размещаться по накопителям различным образом, в соответствии с конфигурациями, которые называют уровнями RAID. Авторы концепции описали уровни RAID с первого по пятый.
Рис. 1. Современные RAID-контроллеры не только поддерживают все уровни RAID, но и обладают массой иных полезных качеств
Все конфигурации, описанные Паттерсоном и его соавторами, используют подход, известный как data striping (разбивка данных), при котором последовательность данных не записывается последовательно на один накопитель, а распределяется на нескольких дисках. Этот способ и обеспечивает реально большую производительность по сравнению с одиночным жестким диском. Перед тем как непосредственно перейти к описанию уровней RAID, следует сказать, что все они имеют свои особенности в отношении цены, производительности в том или ином операционном окружении и надежности. Любое возможное решение представляет собой некоторую комбинацию этих переменных, что дает возможность выбрать оптимальный вариант, наилучшим образом соответствующий требованиям конкретного приложения. А теперь рассмотрим в общих чертах плюсы и минусы каждой конфигурации.
(R)AID 0: Data Striping (разбивка данных)
RAID 0, или правильнее AID 0, так как избыточность данных отсутствует, в общем случае называется Data Striping — разбивка данных или разделение их на полосы. RAID 0 не был определен авторами концепции как самостоятельный уровень, но со временем такое название стало популярным.
В этой конфигурации запись данных производится последовательно через все доступные диски. Другими словами, если есть четыре диска в конфигурации AID 0, то первый блок данных записывается на первый диск, следующий — на второй и т.д., пока четвертый блок не запишется на четвертый диск. Затем процесс повторяется.
Рис. 2. Схема размещения данных в RAID 0 массиве с четырьмя дисками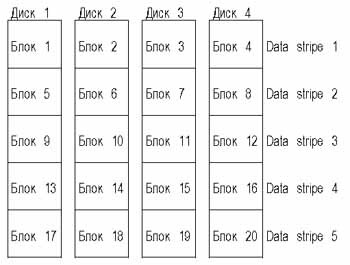
Блоки данных, записанные последовательно на четыре диска, вместе называются полосой данных (data stripe). Производительность при разбиении прямо зависит от размера блока данных. Если размер блока относительно невелик (от одного бита до 1 килобайта), то необходимо использовать синхронизированные по скорости вращения диски и передавать данные параллельно для достижения высокой пропускной способности. Действительно, при маленьком размере блока такой массив устройств выглядит как один большой и быстрый диск. Однако, как бы вы ни старались, вам не обеспечить при этом подходе скорость доступа более высокую, чем у отдельных дисков массива (необходима синхронизация, чтобы поддерживать время доступа на уровне худшего из данных дисков). Следовательно, этот вариант оптимален для высокой скорости передачи данных при малом числе транзакций — видео или CAD/CAM-приложения.
Второй вариант реализации Data Striping — это использование блоков больших размеров и отсутствие необходимости синхронизации скорости вращения. В этом случае упор сделан на попытку обслужить много запросов одновременно на разных дисках. Идея состоит в том, что если размер блока достаточно большой, то можно достигать производительности обычной (не RAID) многодисковой конфигурации при случайных дисковых запросах, а если понадобится произвести большую последовательную передачу данных, проявится польза от собственно Data Striping. Реальный "наилучший" размер блока зависит от конкретного приложения, и при возможности его нужно подстраивать.
Таким образом, преимущества AID 0 зависят от правильно выбранного размера блока. Главный недостаток схемы — все тот же, о котором говорилось выше. Неисправность одного накопителя ведет к потере данных, а общая надежность дисковой подсистемы падает пропорционально количеству дисков. AID 0 рекомендуется там, где критическими параметрами являются низкая стоимость и высокая производительность. Но там, где требования к сохранности информации повышены, особенно если число дисков в вашей системе велико, широко использовать AID 0 не стоит, во всяком случае если вы дорожите сохранностью данных.
Рис. 3. Входящие в RAID-массив диски можно легко заменять и добавлять к ним новые даже без выключения сервера
RAID 1 и RAID 10: Mirroring (зеркальное отражение)
RAID 1 в основном связывают с понятием mirroring, известным у нас как "зеркалка", хотя производители, использующие этот стандарт, до сих пор не устранили несогласованность в его определении. Непременным условием для RAID 1 является использование четного количества дисков. Когда задействовано два накопителя, расхождений в интерпретации нет. Идентичная информация просто дублируется на дисках одинаковой емкости. Если число накопителей более двух, то возможны варианты. Скажем, при наличии четырех жестких дисков в системе они могут быть разделены на две пары, на каждой из которых организуется data striping. Содержимое обеих пар дисков полностью совпадает. По сути, мы имеем дело с зеркальным отражением конфигурации RAID 0. В другом случае опять-таки происходит простое копирование, при котором одна и та же информация записывается сразу на два разных диска. Тогда для описания конфигурации RAID 0 с отражением применяют термин RAID 10.
Запись данных будет производиться на зеркально отраженные пары дисков без дополнительных перегрузок, поскольку может осуществляться параллельно. Скорость записи в конфигурации RAID 1 приблизительно равна скорости AID 0, но скорость чтения может быть существенно выше, поскольку данные могут считываться с любой их копии.
Достоинства RAID 1 (RAID 10) проявляются в высокой производительности (лучшей среди возможных RAID-конфигураций) и наличии двух полных копий данных. Возможен выход из строя до половины всех дисков без потери информации. Недостаток — потеря 50 процентов дисковой памяти, необходимой для хранения избыточной информации. Встречаются реализации зеркального отражения данных с дуплексированием дисковых контроллеров, при которых дополнительный контроллер используется для управления вторым банком дисковых устройств. Это обеспечивает еще большую отказоустойчивость и производительность. Дуплексирование должно поддерживаться на уровне операционной системы, например Novell NetWare 3.xx и 4.xx.
RAID 1 популярен по причине его высокой производительности, полной избыточности данных и того факта, что его преимущества легко понять и объяснить даже непосвященным. Он рекомендуется для приложений, когда производительность и избыточность являются более важными факторами, чем цена. Программы, использующие множественные транзакции в реальном времени, или критические и сильно нагруженные базы данных относятся к этому разряду.
RAID 2: Hamming ECC (коррекция ошибок при помощи кода Хемминга)
RAID 2 использует чередование битов (размер блока в 1 бит) и специальный код с коррекцией ошибок (ECC — Error-Correcting Code), называемый кодом Хемминга, для реализации избыточности данных. Каждый диск системы участвует во всех операциях чтения или записи. Код Хемминга устраняет ошибки на одном диске, но не способен исправить ошибки, возникшие на двух и более дисках. Практические реализации RAID 2 достаточно немногочисленны из-за сложности и дополнительной стоимости ECC-устройств. Большую часть рынка RAID 2 обслуживают более дешевые реализации RAID 3.
RAID 3: Чередование байт или слов с дополнительной четностью
RAID 3 также использует чередование, однако размер блока, используемого при разбиении данных, равен байту или слову. Для обеспечения избыточности введен дополнительный диск четности. Контрольные данные на этом диске опять-таки представлены словами или байтами, каждый из которых соответствует некоторой последовательности данных, разнесенной по всем остальным устройствам. Получить контрольный байт (слово) можно путем простейшей операции "логическое ИЛИ".
Четность — наиболее простой способ реализации всех форм ECC, таких как код Хемминга. Однако обнаружить по данным четности, какой именно диск содержит ошибку, невозможно. Правда, к чести современных накопителей будет сказано, они и сами способны заниматься диагностикой, сообщая о ее результатах контроллеру. Поэтому, если вашим дискам можно доверить надежную индикацию неисправности, то четность удобно применять для обнаружения и исправления ошибок.
Используя RAID 3, можно восстановить все утраченные данные с одного накопителя. Результатом ошибки на нескольких дисках является потеря данных, но это случается крайне редко, особенно если системный администратор удостаивает своим вниманием такую мелочь, как своевременная замена неисправных дисков. В большинстве реализаций RAID 3 используется аппаратный способ подсчета четности при записи. Синхронизация скорости вращения дисков обязательна в любом варианте.
Рис. 4. Конфигурация RAID 3 с пятью дисковыми устройствами. Замечание: каждый блок данных — это байт или слово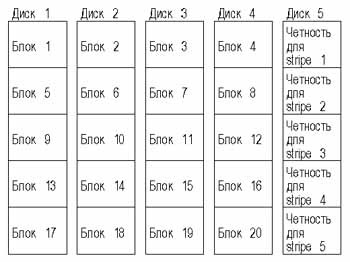
RAID 3 отличается низкой стоимостью и высокой скоростью передачи данных, которая тем выше, чем больше накопителей в системе. Необходим только один диск для четности, независимо от их общего числа. Конечными приложениями для RAID 3 могут являться программы обработки видеоизображений, CAD/CAM и другие, использующие относительно большие объемы данных (мегабайты за одно обращение). RAID 3 не очень хорошо приспособлен для обработки транзакций и для работы с приложениями, использующими множество случайных запросов, такими как, например, Novell NFS. Как и в случае с RAID 2, все диски участвуют в операциях чтения/записи, так что одновременно обслуживается только один запрос.
RAID 3 требует как минимум трех дисков. Если вам необходимо набрать емкость в 4 Гбайта, комплектуя систему винчестерами по 1 Гбайту, то вам потребуется пять дисков.
RAID 4: Чередование блоков с выделенной четностью
RAID 4 — полное подобие RAID 3 во всем, кроме размера блока данных. Типично использование блоков размером 512 байт и выше. Различия между RAID 3 и RAID 4 примерно такие же, как у версий RAID 0 с разными размерами блоков.
Различие в размере блока данных также влечет за собой сторонний эффект. Хотя большинство операций записи в конфигурации RAID 4 вызывает обновление информации лишь на одном диске, четность уже не может быть вычислена исходя только из новых данных, как это было в RAID 3. Типичный процесс требует чтения старых данных с обновляемого диска, чтения старой информации о четности, вычисления новой четности и наконец записи новых данных и четности. Так как только один диск содержит данные о четности, то каждая операция записи затрагивает этот диск. В итоге полоса пропускания всего массива при записи ограничивается полосой пропускания одного-единственного диска — диска четности. Эта зависимость в оригинальном документе по RAID получила название write-performance penalty. (Желающие могут потренироваться в подыскивании подходящего и не слишком косноязычного русского эквивалента.) Производительность при записи RAID 4 обычно составляет 50 процентов от производительности одного диска.
Мораль: достоинства RAID 4 включают в себя хорошую скорость транзакций, низкую плату за избыточность информации (один диск независимо от общего количества дисков в массиве) и относительную простоту реализации. Конфигурация RAID 0 может быть преобразована в RAID 4 путем добавления одного диска. К недостаткам можно отнести потенциально низкую скорость передачи данных относительно RAID 3 и write-performance penalty. Эта конфигурация наилучшим образом подходит для приложений, в которых удельный вес операций записи по отношению к общему числу обращений к дискам довольно мал. Для Novell NFS это обычно справедливо. Другим примером могут служить базы данных с небольшим количеством запросов на обновление информации.
RAID 4 требует как минимум трех дисков. 4 Гбайта дискового пространства, как и в RAID 3, можно получить, используя пять дисков по 1 Гбайту.
RAID 5: Чередование блоков с распределением четности
RAID 5 аналогичен RAID 4, за исключением того, что информация о четности записывается не на один выделенный для этого диск, а распределяется по всем дискам в массиве. Такое распределение призвано уменьшить write-performance penalty RAID 4, вызванное привязкой всех операций записи к одному диску четности.
Рис. 5. Расположение блоков данных и четности в конфигурации RAID 5 с пятью дисковыми устройствами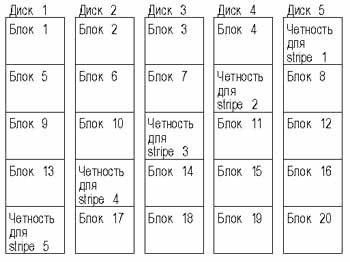
Как видно из диаграммы, блоки четности не хранятся больше на каком-то одном диске. Реальное распределение блоков четности зависит от конкретной реализации, зависимость производительности от распределения является предметом академических исследований.
Преимущество RAID 5 над RAID 4 состоит в том, что благодаря распределению секторов четности по разным дискам сокращается проигрыш в производительности при записи. В RAID 4 конфигурации производительность операций записи остается неизменной при добавлении дополнительных устройств и составляет примерно 50% от производительности одного диска, в то время как у RAID 5 она масштабируется пропорционально числу дисков, отставая, однако, процентов на 25 от производительности RAID 0 при той же емкости. В RAID 4 со всеми исправными дисками операции чтения распределяются по всем дискам, исключая диск четности. RAID 5 в операции чтения задействует все диски без исключения, что дает преимущество в производительности. Скорость чтения в конфигурациях RAID 4 и RAID 5 пропорциональна количеству дисковых устройств.
Массив RAID 5 может быть сконфигурирован как минимум из трех дисков. Емкость в 4 Гбайта достигается использованием пяти дисков по 1 Гбайту. Рынок подходящих приложений для RAID5 идентичен RAID 4, но поскольку скорость записи RAID 5 выше, именно эта конфигурация является лучшим выбором.
В оригинальном RAID-документе RAID 5 была не совсем корректно объявлена высшим уровнем RAID-технологии. И повторять эту неточность не стоит, особенно если вы хотите блеснуть эрудицией в кругу знакомых. Номер RAID не имеет прямого отношения к степени безопасности данных или преимуществу одной реализации над другой. Для каждого уровня RAID определен свой собственный круг задач, для которых он подходит наилучшим образом. При этом одни и те же особенности конфигурации могут быть преимуществом в одном случае и недостатком в другом.
Другие RAID-конфигурации
Другие RAID-конфигурации были определены, но не вошли в число пяти первоначально описанных (известных как уровни RAID Беркли). Один из авторов концепции, Рэнди Кац, дал определение конфигурации RAID 6. Она аналогична RAID5, за исключением того, что используются два алгебраически независимых блока четности на одну разбивку данных. RAID 6 обеспечивает полную сохранность данных даже в случае их потери на двух дисках. Производительность RAID 6 равна производительности RAID 5 в случае операций чтения, но ниже для операции записи из-за необходимости записывать сразу два блока четности на каждую операцию.
Другое определение RAID 6 было предложено Mylex Corporation. В этом определении RAID 6 более походит на RAID 1 или RAID 10. Блок данных 1 записывается на диск 1, дубликат блока 1 записывается на диск 2, блок данных 2 пишется на диск 3, его дубликат пишется на диск 4 и т.д., пока не будет использовано последнее устройство. Затем диск 1 используется вновь и весь процесс повторяется. Для четного числа дисков это полный эквивалент RAID 1 (RAID 10). Однако при нечетном числе накопителей это, очевидно, не так. RAID 6 от Mylex имеет преимущество именно при работе с нечетным количеством дисков. Для реализации этой конфигурации требуется как минимум два диска, а производительность приблизительно равна RAID 1.
Хотелось бы добавить еще несколько слов об использовании всех этих теоретических построений на практике. В современных мощных системах реализация того или иного режима RAID и размещение данных по дискам является прямой обязанностью устройства, называемого RAID-контроллером. Большинство современных RAID-контроллеров является мультирежимными, то есть способно поддерживать сразу несколько уровней RAID.
С момента появления на свет статьи Паттерсона, Гибсона и Каца и первой практической реализации их идей прошло немало времени. За эти годы значительно "поумнели" все электронные устройства, ну а к RAID-контроллерам это относится в первую очередь. Чтобы добиться максимальной привлекательности своей продукции, фирмы-производители соревнуются в том, как "втиснуть" в RAID-контроллер достижения самых передовых технологий и как можно большее количество дополнительных функций.
Так, например, PERC (PowerEdge Expandable RAID Controller), устанавливаемый корпорацией DELL на ее мощных серверах, отличается целым рядом таких особенностей. Помимо мультирежимности и PCI-интерфейса, этот контроллер имеет собственный встроенный кэш емкостью до 32 Мбайт, построенный на микросхемах ECC-памяти. Наличие независимого ОЗУ позволяет контроллеру не только кэшировать данные, наиболее эффективным образом организуя работу с дисками. Дело в том, что память PERC является энергонезависимой. В случае прекращения подачи питания на сервер этот контроллер способен удерживать данные, которые не были записаны на диск, в своей памяти в течение 48 часов. При очередном включении всей системы ее работа начинается с сохранения этих данных на дисках.
PERC оснащен двумя каналами Ultra/Wide SCSI, каждый из которых обладает пропускной способностью до 40 Мбайт/c. Контроллер поддерживает такие функции, как полная диагностика состояния всех накопителей, удаленное конфигурирование и стандарт "горячей" (без выключения сервера) замены и добавления новых дисков.
Собственно говоря, можно упомянуть и еще множество других возможностей. Тем не менее автору не хотелось бы утомлять читателей, углубляясь в столь любимые им технические подробности. К тому же они окончательно загубили бы эту статью, скромно, но с достоинством претендующую на теоретический обзор вопроса. Как говорят, положение обязывает, а потому об особенностях различных RAID-контроллеров лучше поговорить как-нибудь в другой раз. Всему свое место и свое время.
Иван Левченко, GreenLine Computer, фото Сергея Шарубы
Тема данной статьи на первый взгляд представляется сугубо специальной и малоизвестна даже в среде "крутых" профессионалов. Везде, где вы зададите вопрос о RAID, кроме разве что центральных филиалов крупных банков с их мощными серверами и разветвленными сетями, в лучшем случае услышите, что это — некая технология, используемая в серверах с целью защиты данных. В худшем — ответом вам будет просто недоуменное пожатие плечами.
И в самом деле, вопрос локальный — вот пусть специалисты по серверам им и занимаются. С точки зрения пользователя, пусть даже "завязанного" на локальную сеть, трудно придумать что-нибудь скучнее сервера. Стоит себе серверок и пусть стоит, дешевенький такой, за полторы штуки баксов, минской сборки. Никаких интересных приложений на нем не крутится. Правда, если сеть в порядке (а это, вообще говоря, тема отдельная и весьма интересная, но речь пока не о ней), то данные движутся так, как нужно, и попадают туда, куда нужно. Словом, полная идиллия, которая тянется до тех пор, пока в дисковой подсистеме сервера не наступает серьезный сбой либо она полностью не выходит из строя.
Здесь-то обычно и выясняется, что защита ваших данных от возможной потери — вопрос, увы, далеко не праздный и имеет к вам самое прямое и непосредственное отношение. Конечно, утрату дистрибутива Microsoft Windows 95, зачем-то лежавшего на аварийном диске, сжав зубы, пережить можно. Но если вместе с ним "ушли" данные, представляющие собой результат годовой работы научно-исследовательской лаборатории или отдела, то воспринять это как пустяковое происшествие не поможет никакая гештальт-терапия.
То, что ущерб от потери информации сегодня может достигать величин астрономических, общеизвестно. Все это знают, хорошо понимают и... успешно игнорируют на практике. Соображения "экономии" чаще всего берут верх, а прозрение, если и наступает, то только задним числом. Между тем, еще у прадедов для таких случаев была поговорка: "Мы не настолько богаты, чтобы позволить себе покупать дешевые вещи".
Может быть, картина в целом и не столь мрачна. Если говорить о дисковой подсистеме (о чем, собственно, и пойдет сегодня разговор), то здесь есть определенные сдвиги. Пусть медленно, с трудом, однако понимание того факта, что винчестер с IDE-интерфейсом и сервер — вещи несовместные, пробивает себе дорогу. Наряду с осознанием того, что разница в цене между сервером и рабочей станцией при одинаковых вроде бы емкостях диска, размерах ОЗУ и тактовой частоте процессора — не просто прихоть алчных фирм-продавцов этой техники. Избыточность и высочайшая надежность — вот неотъемлемые характеристики сервера (PC, "на страх врагам" переделанные в сервер, естественно, не в счет). О том, за счет чего достигается сегодня надежная и безотказная работа дисковой подсистемы, и пойдет речь далее.
Безусловно, жесткие диски, используемые сегодня в персональных компьютерах, рабочих станциях и серверах, значительно более устойчивы, чем их предшественники 10-летней давности. Основным критерием, характеризующим надежность накопителя, является среднее время между неисправностями, или MTBF (mean time between failures). В отношении сохранности данных используется другой критерий, известный как среднее время до потери данных, или MTDL (mean time to data loss). У высококачественных дисков величина MTDL составляет от 100,000 часов работы (11.4 года) и более.
Казалось бы, вопросы решены. Но в действительности все не так просто. Наряду с увеличением степени надежности дисков растет и их емкость, причем куда более быстрыми темпами. Тем самым постоянно повышающиеся требования пользователей к безотказной работе дисков опережают увеличение надежности, происходящее в действительности. Это означает, что уровень безопасности данных, который можно считать приемлемым для установленного в персоналке винчестера емкостью 540 мегабайт, совершенно неприемлем для 9-гигабайтного SCSI-накопителя.
Можно привести еще и такую предельно наглядную аналогию. Скажем, выход из строя одной из подсистем тепловой электростанции представляет собой достаточно неприятное происшествие, способное доставить персоналу этой станции немало хлопот. Однако подобное происшествие на АЭС может быть источником угрозы уже планетарного масштаба, а последствия аварии, как мы все, к несчастью, уже знаем, придется ликвидировать долгие годы. Ясно поэтому, что уровень надежности, который должен быть заложен при проектировании этих двух типов станций, совершенно не сопоставим по масштабам.
В отношении надежности накопителей, о которой говорилось выше, существует еще одна немаловажная проблема. А именно — объем жестких дисков, доступных на рынке, хронически не успевает за экспоненциальным ростом объемов информации. Кроме того, в то время как стоимость популярных накопителей небольшой емкости достаточно быстро снижается, стоимость высокоемких и быстрых жестких дисков остается весьма высокой. Отсюда вытекает, в частности, тот факт, что пользователю с точки зрения экономии может быть выгоднее оснащать свою систему вместо одного высокоемкого жесткого диска несколькими дисками меньшего объема. Однако устойчивость к ошибкам для дисковой подсистемы в целом при этом уменьшается из-за роста числа потенциальных точек неисправности. Примем величину MTBF для высококачественного диска за 100,000 часов непрерывной работы, как об этом говорилось выше. Для системы из двадцати таких дисков MTBF составит около 4,000 часов, то есть не превышает 6 месяцев!
А потому кажется парадоксальным, что именно размещение данных на разных дисках способно обеспечить чрезвычайно высокую производительность и надежность. Эта фундаментальная идея лежит в основе RAID-конфигураций. Понятие RAID (аббревиатура от Redundant Array of Inexpensive Disks — избыточный массив недорогих дисков) было предложено в 1987 году Дэвидом Паттерсоном, Гартом Гибсоном и Рэнди Кацем из Калифорнийского университета в Беркли в статье "Выбор избыточного массива недорогих дисков".
Паттерсон и его коллеги предложили пять методов использования недорогих устройств в параллельном массиве, который сконфигурирован так, чтобы обеспечивать даже более высокую надежность, чем у одного диска большой емкости. Каждый из этих методов основан на избыточности данных, при которой в состав дисковой подсистемы включен один или несколько жестких дисков сверх количества, необходимого для создания заданной емкости. Этот подход позволяет восстановить данные при неисправности диска, а эффективный уровень ошибок для подобной системы будет очень низким. При этом данные могут размещаться по накопителям различным образом, в соответствии с конфигурациями, которые называют уровнями RAID. Авторы концепции описали уровни RAID с первого по пятый.
Рис. 1. Современные RAID-контроллеры не только поддерживают все уровни RAID, но и обладают массой иных полезных качеств
Все конфигурации, описанные Паттерсоном и его соавторами, используют подход, известный как data striping (разбивка данных), при котором последовательность данных не записывается последовательно на один накопитель, а распределяется на нескольких дисках. Этот способ и обеспечивает реально большую производительность по сравнению с одиночным жестким диском. Перед тем как непосредственно перейти к описанию уровней RAID, следует сказать, что все они имеют свои особенности в отношении цены, производительности в том или ином операционном окружении и надежности. Любое возможное решение представляет собой некоторую комбинацию этих переменных, что дает возможность выбрать оптимальный вариант, наилучшим образом соответствующий требованиям конкретного приложения. А теперь рассмотрим в общих чертах плюсы и минусы каждой конфигурации.
(R)AID 0: Data Striping (разбивка данных)
RAID 0, или правильнее AID 0, так как избыточность данных отсутствует, в общем случае называется Data Striping — разбивка данных или разделение их на полосы. RAID 0 не был определен авторами концепции как самостоятельный уровень, но со временем такое название стало популярным.
В этой конфигурации запись данных производится последовательно через все доступные диски. Другими словами, если есть четыре диска в конфигурации AID 0, то первый блок данных записывается на первый диск, следующий — на второй и т.д., пока четвертый блок не запишется на четвертый диск. Затем процесс повторяется.
Рис. 2. Схема размещения данных в RAID 0 массиве с четырьмя дисками
Блоки данных, записанные последовательно на четыре диска, вместе называются полосой данных (data stripe). Производительность при разбиении прямо зависит от размера блока данных. Если размер блока относительно невелик (от одного бита до 1 килобайта), то необходимо использовать синхронизированные по скорости вращения диски и передавать данные параллельно для достижения высокой пропускной способности. Действительно, при маленьком размере блока такой массив устройств выглядит как один большой и быстрый диск. Однако, как бы вы ни старались, вам не обеспечить при этом подходе скорость доступа более высокую, чем у отдельных дисков массива (необходима синхронизация, чтобы поддерживать время доступа на уровне худшего из данных дисков). Следовательно, этот вариант оптимален для высокой скорости передачи данных при малом числе транзакций — видео или CAD/CAM-приложения.
Второй вариант реализации Data Striping — это использование блоков больших размеров и отсутствие необходимости синхронизации скорости вращения. В этом случае упор сделан на попытку обслужить много запросов одновременно на разных дисках. Идея состоит в том, что если размер блока достаточно большой, то можно достигать производительности обычной (не RAID) многодисковой конфигурации при случайных дисковых запросах, а если понадобится произвести большую последовательную передачу данных, проявится польза от собственно Data Striping. Реальный "наилучший" размер блока зависит от конкретного приложения, и при возможности его нужно подстраивать.
Таким образом, преимущества AID 0 зависят от правильно выбранного размера блока. Главный недостаток схемы — все тот же, о котором говорилось выше. Неисправность одного накопителя ведет к потере данных, а общая надежность дисковой подсистемы падает пропорционально количеству дисков. AID 0 рекомендуется там, где критическими параметрами являются низкая стоимость и высокая производительность. Но там, где требования к сохранности информации повышены, особенно если число дисков в вашей системе велико, широко использовать AID 0 не стоит, во всяком случае если вы дорожите сохранностью данных.
Рис. 3. Входящие в RAID-массив диски можно легко заменять и добавлять к ним новые даже без выключения сервера
RAID 1 и RAID 10: Mirroring (зеркальное отражение)
RAID 1 в основном связывают с понятием mirroring, известным у нас как "зеркалка", хотя производители, использующие этот стандарт, до сих пор не устранили несогласованность в его определении. Непременным условием для RAID 1 является использование четного количества дисков. Когда задействовано два накопителя, расхождений в интерпретации нет. Идентичная информация просто дублируется на дисках одинаковой емкости. Если число накопителей более двух, то возможны варианты. Скажем, при наличии четырех жестких дисков в системе они могут быть разделены на две пары, на каждой из которых организуется data striping. Содержимое обеих пар дисков полностью совпадает. По сути, мы имеем дело с зеркальным отражением конфигурации RAID 0. В другом случае опять-таки происходит простое копирование, при котором одна и та же информация записывается сразу на два разных диска. Тогда для описания конфигурации RAID 0 с отражением применяют термин RAID 10.
Запись данных будет производиться на зеркально отраженные пары дисков без дополнительных перегрузок, поскольку может осуществляться параллельно. Скорость записи в конфигурации RAID 1 приблизительно равна скорости AID 0, но скорость чтения может быть существенно выше, поскольку данные могут считываться с любой их копии.
Достоинства RAID 1 (RAID 10) проявляются в высокой производительности (лучшей среди возможных RAID-конфигураций) и наличии двух полных копий данных. Возможен выход из строя до половины всех дисков без потери информации. Недостаток — потеря 50 процентов дисковой памяти, необходимой для хранения избыточной информации. Встречаются реализации зеркального отражения данных с дуплексированием дисковых контроллеров, при которых дополнительный контроллер используется для управления вторым банком дисковых устройств. Это обеспечивает еще большую отказоустойчивость и производительность. Дуплексирование должно поддерживаться на уровне операционной системы, например Novell NetWare 3.xx и 4.xx.
RAID 1 популярен по причине его высокой производительности, полной избыточности данных и того факта, что его преимущества легко понять и объяснить даже непосвященным. Он рекомендуется для приложений, когда производительность и избыточность являются более важными факторами, чем цена. Программы, использующие множественные транзакции в реальном времени, или критические и сильно нагруженные базы данных относятся к этому разряду.
RAID 2: Hamming ECC (коррекция ошибок при помощи кода Хемминга)
RAID 2 использует чередование битов (размер блока в 1 бит) и специальный код с коррекцией ошибок (ECC — Error-Correcting Code), называемый кодом Хемминга, для реализации избыточности данных. Каждый диск системы участвует во всех операциях чтения или записи. Код Хемминга устраняет ошибки на одном диске, но не способен исправить ошибки, возникшие на двух и более дисках. Практические реализации RAID 2 достаточно немногочисленны из-за сложности и дополнительной стоимости ECC-устройств. Большую часть рынка RAID 2 обслуживают более дешевые реализации RAID 3.
RAID 3: Чередование байт или слов с дополнительной четностью
RAID 3 также использует чередование, однако размер блока, используемого при разбиении данных, равен байту или слову. Для обеспечения избыточности введен дополнительный диск четности. Контрольные данные на этом диске опять-таки представлены словами или байтами, каждый из которых соответствует некоторой последовательности данных, разнесенной по всем остальным устройствам. Получить контрольный байт (слово) можно путем простейшей операции "логическое ИЛИ".
Четность — наиболее простой способ реализации всех форм ECC, таких как код Хемминга. Однако обнаружить по данным четности, какой именно диск содержит ошибку, невозможно. Правда, к чести современных накопителей будет сказано, они и сами способны заниматься диагностикой, сообщая о ее результатах контроллеру. Поэтому, если вашим дискам можно доверить надежную индикацию неисправности, то четность удобно применять для обнаружения и исправления ошибок.
Используя RAID 3, можно восстановить все утраченные данные с одного накопителя. Результатом ошибки на нескольких дисках является потеря данных, но это случается крайне редко, особенно если системный администратор удостаивает своим вниманием такую мелочь, как своевременная замена неисправных дисков. В большинстве реализаций RAID 3 используется аппаратный способ подсчета четности при записи. Синхронизация скорости вращения дисков обязательна в любом варианте.
Рис. 4. Конфигурация RAID 3 с пятью дисковыми устройствами. Замечание: каждый блок данных — это байт или слово
RAID 3 отличается низкой стоимостью и высокой скоростью передачи данных, которая тем выше, чем больше накопителей в системе. Необходим только один диск для четности, независимо от их общего числа. Конечными приложениями для RAID 3 могут являться программы обработки видеоизображений, CAD/CAM и другие, использующие относительно большие объемы данных (мегабайты за одно обращение). RAID 3 не очень хорошо приспособлен для обработки транзакций и для работы с приложениями, использующими множество случайных запросов, такими как, например, Novell NFS. Как и в случае с RAID 2, все диски участвуют в операциях чтения/записи, так что одновременно обслуживается только один запрос.
RAID 3 требует как минимум трех дисков. Если вам необходимо набрать емкость в 4 Гбайта, комплектуя систему винчестерами по 1 Гбайту, то вам потребуется пять дисков.
RAID 4: Чередование блоков с выделенной четностью
RAID 4 — полное подобие RAID 3 во всем, кроме размера блока данных. Типично использование блоков размером 512 байт и выше. Различия между RAID 3 и RAID 4 примерно такие же, как у версий RAID 0 с разными размерами блоков.
Различие в размере блока данных также влечет за собой сторонний эффект. Хотя большинство операций записи в конфигурации RAID 4 вызывает обновление информации лишь на одном диске, четность уже не может быть вычислена исходя только из новых данных, как это было в RAID 3. Типичный процесс требует чтения старых данных с обновляемого диска, чтения старой информации о четности, вычисления новой четности и наконец записи новых данных и четности. Так как только один диск содержит данные о четности, то каждая операция записи затрагивает этот диск. В итоге полоса пропускания всего массива при записи ограничивается полосой пропускания одного-единственного диска — диска четности. Эта зависимость в оригинальном документе по RAID получила название write-performance penalty. (Желающие могут потренироваться в подыскивании подходящего и не слишком косноязычного русского эквивалента.) Производительность при записи RAID 4 обычно составляет 50 процентов от производительности одного диска.
Мораль: достоинства RAID 4 включают в себя хорошую скорость транзакций, низкую плату за избыточность информации (один диск независимо от общего количества дисков в массиве) и относительную простоту реализации. Конфигурация RAID 0 может быть преобразована в RAID 4 путем добавления одного диска. К недостаткам можно отнести потенциально низкую скорость передачи данных относительно RAID 3 и write-performance penalty. Эта конфигурация наилучшим образом подходит для приложений, в которых удельный вес операций записи по отношению к общему числу обращений к дискам довольно мал. Для Novell NFS это обычно справедливо. Другим примером могут служить базы данных с небольшим количеством запросов на обновление информации.
RAID 4 требует как минимум трех дисков. 4 Гбайта дискового пространства, как и в RAID 3, можно получить, используя пять дисков по 1 Гбайту.
RAID 5: Чередование блоков с распределением четности
RAID 5 аналогичен RAID 4, за исключением того, что информация о четности записывается не на один выделенный для этого диск, а распределяется по всем дискам в массиве. Такое распределение призвано уменьшить write-performance penalty RAID 4, вызванное привязкой всех операций записи к одному диску четности.
Рис. 5. Расположение блоков данных и четности в конфигурации RAID 5 с пятью дисковыми устройствами
Как видно из диаграммы, блоки четности не хранятся больше на каком-то одном диске. Реальное распределение блоков четности зависит от конкретной реализации, зависимость производительности от распределения является предметом академических исследований.
Преимущество RAID 5 над RAID 4 состоит в том, что благодаря распределению секторов четности по разным дискам сокращается проигрыш в производительности при записи. В RAID 4 конфигурации производительность операций записи остается неизменной при добавлении дополнительных устройств и составляет примерно 50% от производительности одного диска, в то время как у RAID 5 она масштабируется пропорционально числу дисков, отставая, однако, процентов на 25 от производительности RAID 0 при той же емкости. В RAID 4 со всеми исправными дисками операции чтения распределяются по всем дискам, исключая диск четности. RAID 5 в операции чтения задействует все диски без исключения, что дает преимущество в производительности. Скорость чтения в конфигурациях RAID 4 и RAID 5 пропорциональна количеству дисковых устройств.
Массив RAID 5 может быть сконфигурирован как минимум из трех дисков. Емкость в 4 Гбайта достигается использованием пяти дисков по 1 Гбайту. Рынок подходящих приложений для RAID5 идентичен RAID 4, но поскольку скорость записи RAID 5 выше, именно эта конфигурация является лучшим выбором.
В оригинальном RAID-документе RAID 5 была не совсем корректно объявлена высшим уровнем RAID-технологии. И повторять эту неточность не стоит, особенно если вы хотите блеснуть эрудицией в кругу знакомых. Номер RAID не имеет прямого отношения к степени безопасности данных или преимуществу одной реализации над другой. Для каждого уровня RAID определен свой собственный круг задач, для которых он подходит наилучшим образом. При этом одни и те же особенности конфигурации могут быть преимуществом в одном случае и недостатком в другом.
Другие RAID-конфигурации
Другие RAID-конфигурации были определены, но не вошли в число пяти первоначально описанных (известных как уровни RAID Беркли). Один из авторов концепции, Рэнди Кац, дал определение конфигурации RAID 6. Она аналогична RAID5, за исключением того, что используются два алгебраически независимых блока четности на одну разбивку данных. RAID 6 обеспечивает полную сохранность данных даже в случае их потери на двух дисках. Производительность RAID 6 равна производительности RAID 5 в случае операций чтения, но ниже для операции записи из-за необходимости записывать сразу два блока четности на каждую операцию.
Другое определение RAID 6 было предложено Mylex Corporation. В этом определении RAID 6 более походит на RAID 1 или RAID 10. Блок данных 1 записывается на диск 1, дубликат блока 1 записывается на диск 2, блок данных 2 пишется на диск 3, его дубликат пишется на диск 4 и т.д., пока не будет использовано последнее устройство. Затем диск 1 используется вновь и весь процесс повторяется. Для четного числа дисков это полный эквивалент RAID 1 (RAID 10). Однако при нечетном числе накопителей это, очевидно, не так. RAID 6 от Mylex имеет преимущество именно при работе с нечетным количеством дисков. Для реализации этой конфигурации требуется как минимум два диска, а производительность приблизительно равна RAID 1.
Хотелось бы добавить еще несколько слов об использовании всех этих теоретических построений на практике. В современных мощных системах реализация того или иного режима RAID и размещение данных по дискам является прямой обязанностью устройства, называемого RAID-контроллером. Большинство современных RAID-контроллеров является мультирежимными, то есть способно поддерживать сразу несколько уровней RAID.
С момента появления на свет статьи Паттерсона, Гибсона и Каца и первой практической реализации их идей прошло немало времени. За эти годы значительно "поумнели" все электронные устройства, ну а к RAID-контроллерам это относится в первую очередь. Чтобы добиться максимальной привлекательности своей продукции, фирмы-производители соревнуются в том, как "втиснуть" в RAID-контроллер достижения самых передовых технологий и как можно большее количество дополнительных функций.
Так, например, PERC (PowerEdge Expandable RAID Controller), устанавливаемый корпорацией DELL на ее мощных серверах, отличается целым рядом таких особенностей. Помимо мультирежимности и PCI-интерфейса, этот контроллер имеет собственный встроенный кэш емкостью до 32 Мбайт, построенный на микросхемах ECC-памяти. Наличие независимого ОЗУ позволяет контроллеру не только кэшировать данные, наиболее эффективным образом организуя работу с дисками. Дело в том, что память PERC является энергонезависимой. В случае прекращения подачи питания на сервер этот контроллер способен удерживать данные, которые не были записаны на диск, в своей памяти в течение 48 часов. При очередном включении всей системы ее работа начинается с сохранения этих данных на дисках.
PERC оснащен двумя каналами Ultra/Wide SCSI, каждый из которых обладает пропускной способностью до 40 Мбайт/c. Контроллер поддерживает такие функции, как полная диагностика состояния всех накопителей, удаленное конфигурирование и стандарт "горячей" (без выключения сервера) замены и добавления новых дисков.
Собственно говоря, можно упомянуть и еще множество других возможностей. Тем не менее автору не хотелось бы утомлять читателей, углубляясь в столь любимые им технические подробности. К тому же они окончательно загубили бы эту статью, скромно, но с достоинством претендующую на теоретический обзор вопроса. Как говорят, положение обязывает, а потому об особенностях различных RAID-контроллеров лучше поговорить как-нибудь в другой раз. Всему свое место и свое время.
Иван Левченко, GreenLine Computer, фото Сергея Шарубы
Компьютерная газета. Статья была опубликована в номере 18 за 1997 год в рубрике hard :: hdd
